8. OpenShift のデプロイメントおよび設定¶
Ansible Tower は、OpenShift 上でのコンテナーベースのクラスター実行をサポートするようになりました。このセクションでは、特に以下の内容を含めて、OpenShift と Tower Pod 設定について概説します。
標準の Tower vs OpenShift Tower (インスタンスの自動削除) の主な相違点
Tower は先に単一の Pod をデプロイしてから移行後にスケールアップできること
移行はタスクランナー Pod で実行されること
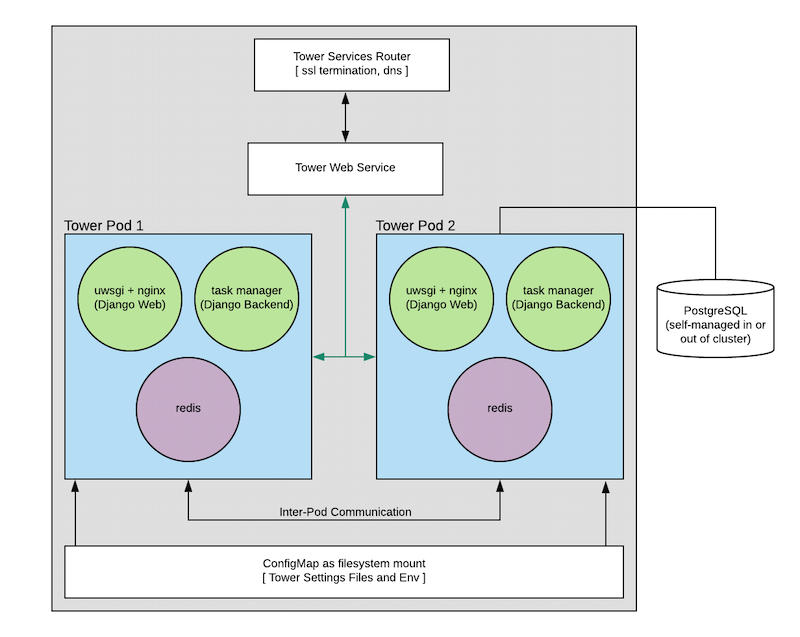
8.1. Tower と OpenShift の基本情報¶
Tower OpenShift ドキュメントは、管理者レベルでの OpenShift の使用方法を理解し、コンテナーベースのインフラストラクチャーの管理経験があることを前提としています。Tower と OpenShift の相違点は以下のとおりです。
スタンドアロンの Tower および OpenShift Tower では、使用するインストーラーが異なります。OpenShift インストーラーは、http://releases.ansible.com/ansible-tower/setup_openshift にアクセスします。
Tower は OpenShift 自体にリンクしており、手動で Playbook を実行したり (新しいノードを起動する)、シェルで管理コマンドを実行したり (ノードを意図的にオフラインにする) せずに、スケールアップとスケールダウンを容易にします。システムが起動すると、Tower Deploymen を設定して、追加の Tower Pod を追加または削除できます。
Tower Pod は、HTTP なしに設定され、インストーラーで、全 Tower Pod へのSSL の中断および分散要求を処理する OpenShift Route を設定します。これは、OpenShift ロードバランサーに似ています。
データベースの移行は、タスクエグゼキューターのコンテナーを Pod 内に起動するプロセスの一部として実行されるので、Playbook が完了してから実行される可能性が高いです。
容量/パフォーマンス検出 (リソース要求および要求プラン のセクションを参照)。
OpenShift での分離インスタンスと Ansible Tower の実行の組み合わせはサポートされません。
8.2. 設定オプション¶
要件
サポートされている最新の OpenShift バージョン 3.x および 4.x (詳細は Red Hat Container Registry Authentication を参照)
- Pod ごとのデフォルトのリソース要件
メモリー 6GB
CPU コア 3 個
インストーラーを実行するマシンに設定した Openshift コマンドラインツール (oc)
設定済みおよび実行中の OpenShift クラスター
OpenShift インストーラーを実行するアカウントの管理者権限 (
cluster-adminロールが必要です)
8.3. 基本設定¶
OpenShift インストールでは、以下のパラメーターを設定する必要があります。
openshift_hostopenshift_projectopenshift_useropenshift_passwordadmin_passwordsecret_keypg_usernamepg_password
OpenShift インストール方法の場合には、設定は「traditional Tower install method」と同じですが、以下の点が異なります。
Tower UI および API の SSL ターミネーションは、OpenShift サービスオブジェクトを使用して処理されます。ここで使用される証明書は、OpenShift の内部 CA によって生成および署名されます。
OpenShift インストールにオプションでデプロイされる、コンテナー化された PostgreSQL Pod は SSL 用に設定することはできません。OpenShift 環境で SSL 対応の PostgreSQL が必要な場合は、PostgreSQL サーバーを個別にデプロイし、Tower ノードを設定する必要があります (
pg_sslmodeを使用)。
プロジェクトが存在しない場合には作成されますが、プロジェクトのユーザーには以下が必要です。
プロジェクトを作成して、Tower が必要とする Pod を使用してデータを投入する機能
または
プロジェクトが存在する場合には、プロジェクトで必要な Pod を作成する権限
パスワードは、インストーラーを実行時に示されるようにコマンドで指定する必要があります。
oc コマンドラインのクライアントをインストールして利用できるようにし、クライアントのバージョンとサーバーのバージョンが一致するようにしてください。
シークレットキー、管理者パスワード、postgresql のユーザー名とパスワードは、インストーラーを実行する前にインベントリーファイルに事前に設定しておく必要があります。
./setup_openshift.sh -e openshift_password=$OPENSHIFT_PASSWORD -- -v
注釈
Tower は、(比較的) 権限のない awx ユーザーに、Ansible プロセスをそれぞれ分離する機能を提供するメカニズムとして、(Project Atomic からの) Bubblewrap を使用します。権限ありのモードで、Tower Web およびタスクコンテナーを実行する必要のあるコンテナーに付与する必要のある権限がいくつかあります。
Tower Web サービスのデフォルトタイプは NodePort です。これをカスタマイズするには、インベントリーファイルの kubernetes_web_svc_type を ClusterIP または LoadBalancer に設定するか、追加の変数として渡します。
8.4. リソース要求および要求プラン¶
通常、Tower は、ジョブの実行や、バックグラウンドの要求実行に必要なキャパシティーを判断するために、Tower が稼働するシステムを検証します。OpenShift では、Pod とコンテナーがシステムで共存する傾向にあるため、仕組みが異なります。Pod は、現在の状況 (たとえば、OpenShift クラスターがアップグレードされる場合や、停止している場合) によってホスト間で移行することも可能です。
Pod とコンテナーが必要なリソースを要求するのは一般的です。OpenShift がこの情報を使用して、どこで何を実行するか (または実行できるか) を決定します。
Tower は、この情報を使用して、個別のジョブを実行可能な数 (およびサイズ) に合わせて、独自のキャパシティーを設定します。
Tower Pod はそれぞれコンテナー 3 個で形成されます (「diagram」参照)。各コンテナーは、標準のデフォルト値で設定されますが、すべてを統合するとかなり大きくなる可能性があります。これらのデフォルト値は設定可能ですが、Tower クラスターに与える影響を把握しておくと便利です。
最も重要な値は、タスク実行コンテナーの CPU とメモリー割り当ての 2 つです。このコンテナーが、実際にジョブの起動を担当するので、これらの値が実行可能なジョブ数やサイズを直接制御します。これらの設定は、インベントリーで変更できます。以下にデフォルト値を紹介します。
task_cpu_request=1500
これは、専用に割り当てる CPU の数量です。1500 の値は、OpenShift 自体が CPU の要求をどのように評価するか (https://docs.OpenShift.com/container-platform/3.9/dev_guide/compute_resources.html#dev-cpu-requests 参照) を指します。値の意味は「https://docs.OpenShift.com/container-platform/3.9/dev_guide/compute_resources.html#dev-compute-resources 」を参照してください。
1500 は 1500 ミリコアで、CPU コア約 1.5 個分になります。
この値は以下の方法で Tower のキャパシティーを設定するのに使用します。
((task_cpu_request/ 1000) * 4)
つまり、デフォルトでは OpenShift の Tower (CPU ベースのアルゴリズムですべて設定された場合) は、同時に最大 6 個のフォークで実行可能です。
調節が可能な他の値:
task_mem_request=2 - This is the amount of memory to dedicate (in gigabytes).
この値は以下の方法で Tower のキャパシティーを設定するのに使用します。
((task_mem_request * 1024) / 100)
つまり、メモリーベースのアルゴリズムで設定されている場合には、デフォルトで Tower は同時に最大 40 個のフォークで稼働できます。
デフォルトのリソース要求については、「roles/kubernetes/defaults/main.yml」を参照してください。
合計で、単一の Tower Pod 向けの要求リソースはデフォルトで以下のようになります。
CPU コア 3 個
メモリー 6 GB
Tower を実行する OpenShift インストーラーは、最低でも上記に一致する必要があります。デフォルト値を変更した場合は、新しい要件に合わせてシステムを更新する必要があります。
注釈
OpenShift インストーラーで他の Pod を実行しているか、システムが小さすぎてこれらの要件を満たせない場合には、どこからも Tower を実行できません。詳細は、「Capacity Algorithm」を参照してください。
8.5. データベースの設定および用途¶
OpenShift で実行する Tower に Tower PostgreSQL データベースを設定する方法は 2 種類あります。
(推奨) 外部管理のデータベース (Tower の設定 Playbook でインストールしていない)。PostgreSQL サーバーは、Openshift クラスター内外を問わず Tower をインストールする前にインストールしてから、このサーバーを参照するように Tower を設定するようにしてください。
PostgreSQL は、事前に作成した
PersistentVolumeClaimを指定し、これに Tower のインストール Playbook のインベントリーファイルをpg_pvc_nameとして指定して、Tower インストーラーで OpenShift にインストールします。
Tower をデモ/評価目的でインストールする場合には、openshift_pg_emptydir=true を設定してください。これにより、OpenShift は Pod が使用できるように一時ボリュームを作成します。
警告
このボリュームは、デモ/評価目的のみの一時的なもので、Pod が停止されると削除されます。
8.6. バックアップとリストア¶
アップグレード前に同じバージョンでバックアップして復元する必要があります。バックアップと復元のプロセスは、従来の Tower のプロセスに似ています。インストーラーディレクトリーの Root から以下を実行します。
./setup_openshift.sh -b # Backup
./setup_openshift.sh -r # Restore
注釈
configmap は、インベントリーファイルの値から再作成されます。インベントリーファイルは、バックアップの tarball に含まれています。
8.7. アップグレード¶
アップグレード実行前に、同じバージョンでバックアップして復元する必要があります。OpenShift での Tower デプロイメントをアップグレードするには、http://releases.ansible.com/ansible-tower/setup_openshift から最新のインストーラーをダウンロードします。従来の Tower のインストールと同様に、ダウンタイムが予想されます。
8.8. 移行¶
Tower は、以下の説明のように従来の設定から OpenShift の設定への移行をサポートします。
まず、通常のアップグレード手順を使用して、従来の Tower 設定を Ansible Tower の最新バージョン (または、最低でもバージョン 3.3 ) にアップグレードします。
OpenShift インストーラーをダウンロードします。
inventoryファイルを編集し、従来の Tower 設定から、アップグレードした Tower のデータベースを参照するように、pg_username、pg_password、pg_databaseおよびpg_portを変更します。通常通りに OpenShift インストーラーを実行します。
警告
pg_password で特殊文字を使用しないでください。セットアップが失敗する場合があります。
8.9. カスタムの仮想環境の構築¶
ベースのコンテナーイメージを上書きして、カスタムの仮想環境 (virtualenvs) を構築することができます。カスタマイズまたはカスタムの virtualen か、ローカルのミラーリングには、ベースのコンテナーの上書きを使用します。OpenShift にデプロイされた Tower で、カスタムの仮想環境を使用する場合には、Tower で使用するコンテナーイメージをカスタマイズする必要があります。
例として使用可能な Dockerfile を紹介します。これは、Ansible をカスタムの仮想環境にインストールします。
FROM registry.redhat.io/ansible-tower-38/ansible-tower-rhel7
USER root
RUN yum install -y gcc python-devel openssl-devel
RUN umask 0022
RUN virtualenv /var/lib/awx/venv/ansible2.7
RUN /var/lib/awx/venv/ansible2.7/bin/pip install psutil python "ansible==2.7.9"
他の python の依存関係 (カスタムモジュール用など) をインストールする必要がある場合には、仮想環境をアクティベートする Docker ファイルに RUN コマンドを追加して、pip を呼び出してください。
イメージが構築されたら、そのイメージがレジストリー内にあり、OpenShift クラスターとインストーラーからアクセスできることを確認します。
OpenShift インストーラーの group_vars/all の以下の変数を上書きして、レジストリーにプッシュしたイメージを参照するようにします。
kubernetes_web_image: registry.example.com/my-custom-tower
kubernetes_task_image: registry.example.com/my-custom-tower
vanilla Red Hat イメージをミラーリングする場合:
kubernetes_web_image: registry.example.com/ansible-tower
kubernetes_task_image: registry.example.com/ansible-tower