8. コンテナーおよびインスタンスグループ¶
コントローラーを使用すると、クラスターのメンバーで直接実行される Ansible Playbook を介してジョブを実行するか、コンテナーグループと呼ばれる必要なサービスアカウントがプロビジョニングされた Openshift クラスターの名前空間でジョブを実行できます。コンテナーグループ内のジョブは、プレイブックごとに必要な場合にのみ実行できます。詳細については、を参照してください。必要に応じて Playbook ごとにコンテナーグループでジョブを実行できます。詳細は、このセクションに後述されている「コンテナーグループ」を参照してください。
execution environments については、Automation Controller User Guide の「Execution Environments」を参照してください。
8.1. インスタンスグループ¶
インスタンスは、1 つまたは複数のインスタンスグループにグループ化することができます。インスタンスグループは、以下に記載のリソース 1 つまたは複数に割り当てることができます。
組織
インベントリー
ジョブテンプレート
リソースの 1 つに関連付けられているジョブが実行されると、そのリソースに関連付けられているインスタンスグループに割り当てられます。実行プロセス中に、インベントリーに関連付けられたインスタンスグループではなく、ジョブテンプレートに関連付けられたインスタンスグループが先に確認されます。同様に、インベントリーに関連付けられているインスタンスグループは、組織に関連付けられているインスタンスグループよりも先に確認されます。そのため、3 つのリソースのインスタンスグループの割り当てには、Job Template > Inventory > Organization の階層が形成されます。
インスタンスグループの使用時に考慮すべき事項を複数、以下に示します。
必要に応じて、これらのグループに他のグループおよびグループインスタンスを定義することができます。これらのグループには、
instance_group_のプレフィックスを指定する必要があります。インスタンスは、instance_group_グループと共にautomationcontrollerまたはexecution_nodesグループに含まれる必要があります。クラスター化された設定では、1 つ以上のインスタンスがautomationcontrollerグループに存在する 必要があります。これは、API インスタンスグループのcontrolplaneとして表示されます。シナリオの例は、:ref:`ag_automationcontroller_group_policies`を参照してください。defaultAPI インスタンスグループは、ジョブの実行が可能な全ノードで自動的に作成されます。技術的には、他のインスタンスグループと同様ですが、特定のインスタンスグループが特定のリソースに関連付けられていない場合に、ジョブ実行は常にdefaultインスタンスグループにフォールバックします。defaultインスタンスグループは常に存在します(削除または名前もできません)。名前が
instance_group_defaultのグループは作成しないでください。インスタンスにグループ名と同じ名前を指定しないでください。
8.1.1. automationcontroller グループのポリシー¶
ノードを定義する際には、以下の基準を使用します。
automationcontrollerグループのノードは、node_typehostvar をhybrid(デフォルト) またはcontrolに定義できます。execution_nodesグループのノードは、node_typehostvar をexecution(デフォルト) またはhopに定義できます。
instance_group_* を使用してグループに名前を付けることで、インベントリーファイルでカスタムグループを定義できます。* は API のグループの名前になります。または、インストールが完了した後に API でカスタムインスタンスグループを作成できます。
現在の動作では、instance_group_* のメンバーが automationcontroller または execution_nodes グループのメンバーであることを想定しています。このシナリオ例を挙げています。
[automationcontroller]
126-addr.tatu.home ansible_host=192.168.111.126 node_type=control
[automationcontroller:vars]
peers=execution_nodes
[execution_nodes]
[instance_group_test]
110-addr.tatu.home ansible_host=192.168.111.110 receptor_listener_port=8928
インストーラーを実行すると、以下のエラーが発生します。
TASK [ansible.automation_platform_installer.check_config_static : Validate mesh topology] ***
fatal: [126-addr.tatu.home -> localhost]: FAILED! => {"msg": "The host '110-addr.tatu.home' is not present in either [automationcontroller] or [execution_nodes]"}
これを修正するには、ボックス 110-addr.tatu.home を execution_node グループに移動します。
[automationcontroller]
126-addr.tatu.home ansible_host=192.168.111.126 node_type=control
[automationcontroller:vars]
peers=execution_nodes
[execution_nodes]
110-addr.tatu.home ansible_host=192.168.111.110 receptor_listener_port=8928
[instance_group_test]
110-addr.tatu.home
その結果、以下のようになります。
TASK [ansible.automation_platform_installer.check_config_static : Validate mesh topology] ***
ok: [126-addr.tatu.home -> localhost] => {"changed": false, "mesh": {"110-addr.tatu.home": {"node_type": "execution", "peers": [], "receptor_control_filename": "receptor.sock", "receptor_control_service_name": "control", "receptor_listener": true, "receptor_listener_port": 8928, "receptor_listener_protocol": "tcp", "receptor_log_level": "info"}, "126-addr.tatu.home": {"node_type": "control", "peers": ["110-addr.tatu.home"], "receptor_control_filename": "receptor.sock", "receptor_control_service_name": "control", "receptor_listener": false, "receptor_listener_port": 27199, "receptor_listener_protocol": "tcp", "receptor_log_level": "info"}}}
コントローラー 4.0 以前からアップグレードすると、レガシーの instance_group_ メンバーには awx コードがインストールされている可能性があります。これにより、ノードが automationcontroller グループに配置されます。
8.1.2. API からのインスタンスグループの設定¶
インスタンスグループは、システム管理者として /api/v2/instance_groups に POST 要求を出すことで作成できます。
インスタンスグループを作成したら、インスタンスをインスタンスグループに関連付けることができます。
HTTP POST /api/v2/instance_groups/x/instances/ {'id': y}`
インスタンスグループに追加したインスタンスは、自動的にグループの作業キューをリッスンするように再設定されます。詳細は、以下の「インスタンスグループのポリシー」セクションを参照してください。
8.1.3. インスタンスグループのポリシー¶
policy を定義することにより、オンラインになると自動的にインスタンスグループに参加するようにコントローラーインスタンスを設定できます。これらのポリシーは、新しいインスタンスがオンラインになるたびに評価されます。
インスタンスグループポリシーは、Instance Group の 3 つの任意フィールドにより制御されます。
policy_instance_percentage: これは、0 ~ 100 の間の数字で指定します。これにより、確実に、アクティブなコントローラーインスタンスの割合が対象のインスタンスグループに追加されるようになります。新しいインスタンスがオンラインになると、このグループのインスタンス数が、インスタンスの全体数に対して、指定の割合より少ない場合には、指定の割合の条件を満たすまで、新しいインスタンスが追加されます。policy_instance_minimum: このポリシーは、インスタンスグループに配置するように試行する最小インスタンス数を指定します。利用可能なインスタンス数がこの最小数よりも少ない場合には、すべてのインスタンスがこのインスタンスグループに配置されます。policy_instance_list: これは、このインスタンスグループに常に含めるインスタンス名の固定一覧です。
automation controller ユーザーインターフェースのインスタンスグループ一覧ビューでは、インスタンスグループのポリシーをもとにした各インスタンスグループのキャパシティーレベルの概要がわかります。
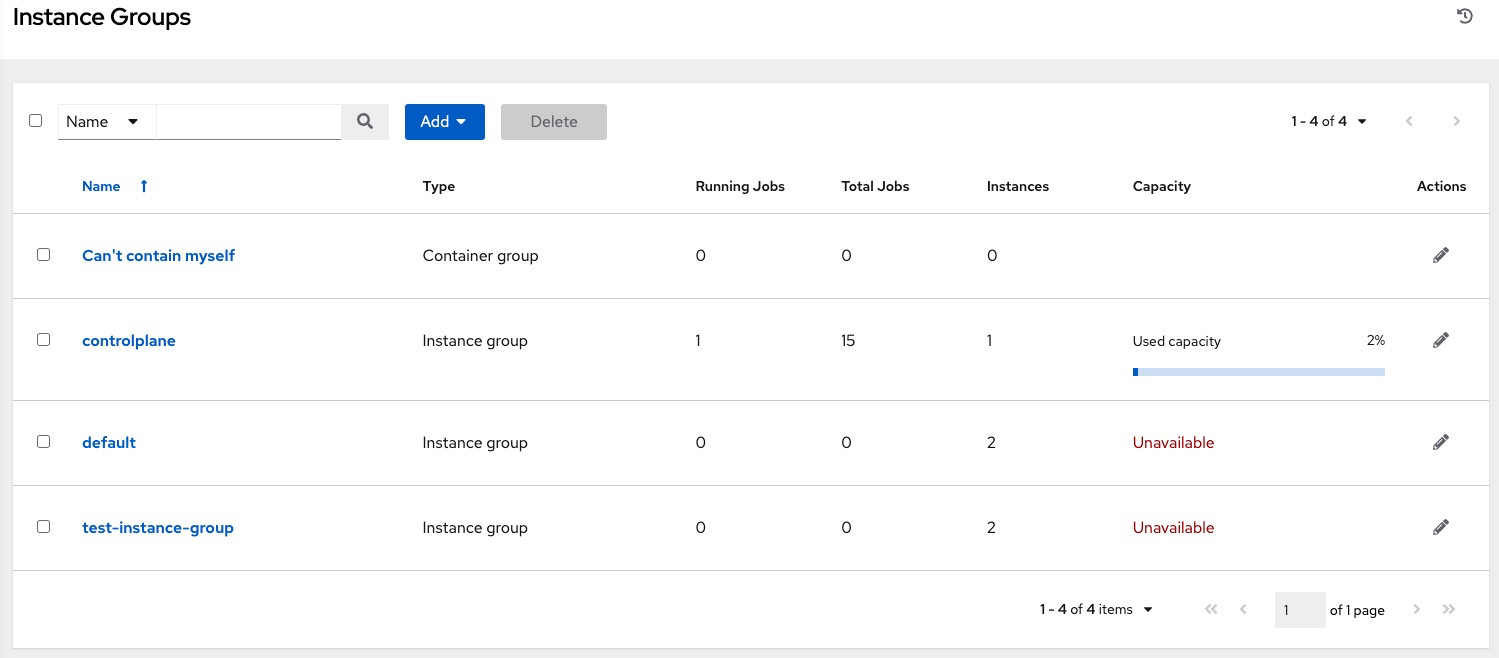
8.1.4. 主なポリシーの考慮事項¶
policy_instance_percentageおよびpolicy_instance_minimumはいずれも、最小割り当てレベルを指定します。このグループに割り当てる数が多いルールが適用されます。たとえば、policy_instance_percentageが 50%、policy_instance_minimumが 2 の場合に、6 台のインスタンスを起動すると、3 台がこのインスタンスグループに割り当てられます。クラスター内のインスタンス総数を 2 に減らすと、policy_instance_minimumの条件を満たすために、この 2 台のインスタンスがいずれも、インスタンスグループに割り当てられます。こうすることで、利用可能なリソースの制限に合わせて、低い値を設定できます。ポリシーは、自発的にインスタンスが複数のインスタンスグループに割り当てられないように規制するわけではありませんが、割合を合計すると 100 になるように指定すると実質的に、複数のインスタンスグループに割り当てないようにできます。インスタンスグループが 4 つあり、割合の値が 25 に割り当てると、インスタンスは重複することなく分散されます。
8.1.5. 固有のグループへのインスタンスの手動固定¶
インスタンスが特別で、特定のインスタンスグループだけに割り当てる必要があり、「percentage」または「minimum」のポリシーで他のグループに自動的に参加させない場合には、以下を行います。
インスタンスを 1 つまたは複数のインスタンスグループの
policy_instance_listに追加します。インスタンスの
managed_by_policyプロパティーをFalseに更新します。
こうすることで、割合や最小ポリシーをもとに、インスタンスが他のグループに自動的に追加されないようにします。手動で割り当てたグループにのみ所属するようになります。
HTTP PATCH /api/v2/instance_groups/N/
{
"policy_instance_list": ["special-instance"]
}
HTTP PATCH /api/v2/instances/X/
{
"managed_by_policy": False
}
8.1.6. ジョブランタイムの動作¶
インスタンスグループに関連付けられたジョブを実行する場合は、以下の動作に注意してください。
クラスターを複数のインスタンスグループに分類する場合は、クラスター全体の動作と類似します。インスタンス 2 台がグループに割り当てられると、同じグループ内の他のインスタンスと同様に、いずれかのインスタンスがジョブを受信する可能性が高いです。
コントローラーインスタンスがオンラインになると、システムの作業容量が効率的に拡張されます。これらのインスタンスがインスタンスグループにも置かれている場合、そのグループの容量も拡張されます。複数のグループに所属するインスタンスが作業を実行する場合は、所属する全グループから容量が削減されます。インスタンスのプロビジョニングを解除すると、インスタンスの割当先のクラスターから容量がなくなります。詳細については「インスタンスのプロビジョニング解除」のセクションを参照してください。
注釈
すべてのインスタンスを同じ容量でプロビジョニングする必要はありません。
8.1.7. ジョブ実行場所の制御¶
ジョブテンプレート、インベントリー、または組織にインスタンスグループが割り当てられている場合には、対象のジョブテンプレートから実行されたジョブはデフォルトの動作を実行する資格はありません。つまり、これら 3 つのリソースに関連付けられたインスタンスグループに所属する全インスタンスに十分な容量がない場合には、容量が使用可能になるまでジョブは保留状態のままになります。
ジョブの送信先のインスタンスグループを決定する場合の優先順位は、以下のとおりです。
ジョブテンプレート
インベントリー
組織 (プロジェクトの形式)
インスタンスグループがジョブテンプレートと関連付けられており、いずれも許容容量内である場合には、ジョブはインベントリーで指定したインスタンスグループ、次に組織で指定したインスタンスグループに送信されます。リソースがあるので、ジョブはこれらのグループ内で、任意の順番で実行してください。
グローバルの default グループは、Playbook で定義されるカスタムのインスタンスグループと同様に、リソースと関連付けることができます。これは、ジョブテンプレートやインベントリーに希望のインスタンスグループを指定するのに使用できますが、容量が足りない場合にはジョブは別のインスタンスに送信できます。
たとえば、ジョブテンプレートと group_a を関連付けたり、インベントリーと default``グループを関連付けたりすることで、``group_a の容量が足りなくなると、 default グループをフォールバックとして使用できるようになります。
さらに、インスタンスグループにリソースを関連付けずに、フォールバックとして別のリソースを指定することができます。たとえば、ジョブテンプレートにインスタンスグループを割り当てずに、インベントリーや組織のインスタンスグループにフォールバックするように設定できます。
この設定には、優れたユースケースが他に 2 つあります。
(ジョブテンプレートをインスタンスグループに割り当てずに) インスタンスグループにインベントリーを関連付けることで、特定のインベントリーに対して実行される Playbook が関連付けられたグループでのみ実行されるようにすることができます。これらのインスタンスのみが管理ノードに直接関連付けられている場合に非常に便利です。
管理者は、インスタンスグループに組織を割り当てることができます。これにより、管理者はインフラストラクチャー全体をセグメントに分け、各組織が他の組織のジョブ実行機能を妨げずに、ジョブを実行できるように保証します。
同様に、以下のシナリオのように、管理者は希望に合わせて複数のグループを各組織に割り当てることもできます。
A、B、C の 3 つのインスタンスグループがあり、Org1 および Org2 の 2 つの組織がある場合
管理者が Org1 にグループ A を、Org2 にグループ B を、容量が余分に必要となる可能性があるのでオーバーフロー用として Org1 および Org2 両方にグループ C を割り当てる場合
組織の管理者が自由にインベントリーまたはジョブテンプレートを希望のグループに割り当てる (か、組織からのデフォルトの順番を継承する) 場合
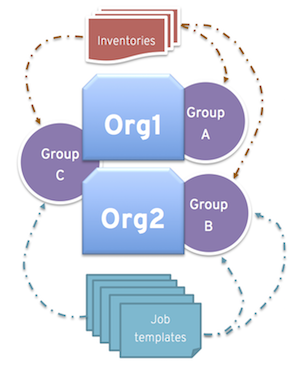
このような方法でリソースを割り当てると柔軟性が高くなります。また、インスタンスが 1 つしか含まれないインスタンスグループを作成することができるため、コントローラークラスターの固有のホストに作業を割り当てることができるようになります。
8.1.8. インスタンスグループのプロビジョニング解除¶
Playbook の設定を再実行しても、自動的にインスタンスのプロビジョニングが解除されるわけではありません。これは現在、インスタンスがオフラインになった理由が意図的なのか、障害が原因なのかをクラスターでは識別できないためです。代わりに、コントローラーインスタンスの全サービスをシャットダウンしてから、他のインスタンスからプロビジョニング解除ツールを実行します。
automation-controller-service stopのコマンドで、インスタンスをシャットダウンするか、サービスを停止します。別のインスタンスから、プロビジョニング解除のコマンド
$ awx-manage deprovision_instance --hostname=<name used in inventory file>を実行して、コントローラーのクラスターレジストリーから削除します。例:
awx-manage deprovision_instance --hostname=hostB
同様に、プロビジョニングを解除しても、多くの場合、コントローラーのインスタンスグループが使用されないにも関わらず、コントローラーのインスタンスグループのプロビジョニングを解除しても、インスタンスグループが自動的に削除されたり、プロビジョニングが解除されたりしません。そのまま API エンドポイントに表示されたり、統計が監視されたりする可能性があります。これらのグループは、以下のコマンドを使用すると、削除することができます。
例:
awx-manage unregister_queue --queuename=<name>
このインベントリーファイルのインスタンスグループから、インスタンスのメンバーシップを削除して、Playbook の設定を再実行しても、インスタンスがグループに再度追加されなくなるわけではありません。インスタンスがグループに追加されないようにするには、API 経由で削除し、インベントリーファイルからも削除するか、インベントリーファイルでインスタンスグループの定義をなくします。automation controller ユーザーインターフェースでインスタンスグループのトポロジーを管理することも可能です。UI でのインスタンスグループの管理に関する詳細は、『Automation Controller User Guide』の「Instance Groups」を参照してください。
注釈
以前のバージョンのコントローラー(3.8.x 以前)で作成したインスタンスグループを分離していて、それらを実行ノードに移行して、自動化メッシュアーキテクチャーと使用する際に互換性を持たせるようにするには、『Ansible Automation Platform Upgrade and Migration Guide』の「分離インスタンスの実行ノードへの移行」を参照してください。
8.2. コンテナーグループ¶
Ansible Automation Platform は、Container Groups をサポートしています。これにより、コントローラーがスタンドアロンとしてインストールされているか、仮想環境またはコンテナーにインストールされているかに関係なく、コントローラーでジョブを実行できます。コンテナーグループは、仮想環境内のリソースのプールとして機能します。OpenShift コンテナーを指すインスタンスグループを作成できます。これは、Playbook の実行中のみ存在する Pod としてオンデマンドでプロビジョニングされるジョブ環境です。これは一時的な実行モデルと呼ばれ、すべてのジョブ実行に対してクリーンな環境を確保します。
場合によっては、コンテナーグループを「常時オン」にしておくことが望ましいです。これは、インスタンスの作成時に設定されます。
注釈
automation controller 4.0 以前のバージョンからアップグレードしたコンテナーグループはデフォルトに戻り、古い Pod 定義を完全に削除して、移行中のすべてのカスタム Pod 定義を消去します。
execution environments はコンテナーイメージであり、仮想環境を使用しないという点で、execution environments とコンテナーグループは異なります。詳細については、『Automation Controller User Guide』の「Execution Environments」を参照してください。
8.2.1. コンテナーグループの作成¶
ContainerGroup は、OpenShift クラスターに接続できる認証情報が関連付けられた InstanceGroup です。コンテナーグループを設定するには、まず、以下が必要です。
起動の対象となる namespace (「default」 namespace はありますが、ほとんどの場合はお客様によって異なります)
この namespace で Pod を起動および管理可能なロールを持つサービスアカウント
プライベートレジストリーで execution environments を使用する場合は、オートメーションコントローラーでコンテナーレジストリー認証情報が関連付けられている場合、サービスアカウントには、名前空間で秘密を取得、作成、および削除するためのロールも必要です。これらのロールをサービスアカウントに付与したくない場合は、
ImagePullSecretsを事前に作成して、および ContainerGroup の Pod 仕様でそれらを指定します。この場合は、execution environment コンテナーレジストリー認証情報を関連付けないでください。関連付けられていない場合、コントローラーは名前空間に秘密を作成しようとします。そのサービスアカウントに関連付けられたトークン (OpenShift または Kubernetes Bearer トークン)
クラスターに関連付けられた CA 証明書
ここでは、サービスアカウントを作成し、automation controller: の設定に必要な情報を収集する例について説明します。
この例をダウンロード (containergroup sa <./containergroup-sa.yml>) して使用し、上記の認証情報を取得します。
containergroup-sa.yml:: から設定を適用します。oc apply -f containergroup-sa.yml
サービスアカウントに関連付けられているシークレット名を取得します:
export SA_SECRET=$(oc get sa containergroup-service-account -o json | jq '.secrets[0].name' | tr -d '"')
シークレットからトークンを取得します:
oc get secret $(echo ${SA_SECRET}) -o json | jq '.data.token' | xargs | base64 --decode > containergroup-sa.tokenCA 証明書を取得します:
oc get secret $SA_SECRET -o json | jq '.data["ca.crt"]' | xargs | base64 --decode > containergroup-ca.crt
containergroup-sa.tokenとcontainergroup-ca.crtの内容を使用して、コンテナーグループに必要な OpenShift または Kubernetes API Bearer トークン の情報を提供します。
コンテナーグループを作成するには、以下を実行します。
コントローラーのユーザーインタフェースを使用して、コンテナーグループで使用する OpenShift または Kubernetes API Bearer トークン 認証情報を作成します。詳細は、Automation Controller User Guide の 新規認証情報の追加 を参照してください。
左側のナビゲーションバーから インスタンスグループ をクリックして、インスタンスグループ設定ウィンドウに移動して、新しいコンテナーグループを作成します。
Add ボタンをクリックして、Create Container Group を選択します。
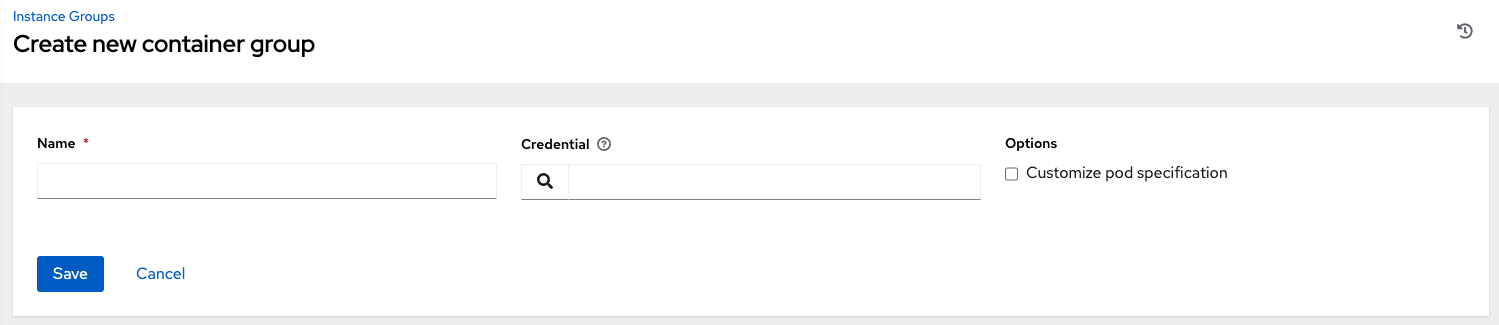
新しいコンテナーグループの名前を入力し、以前に作成した資格情報を選択して、コンテナーグループに割り当てます。
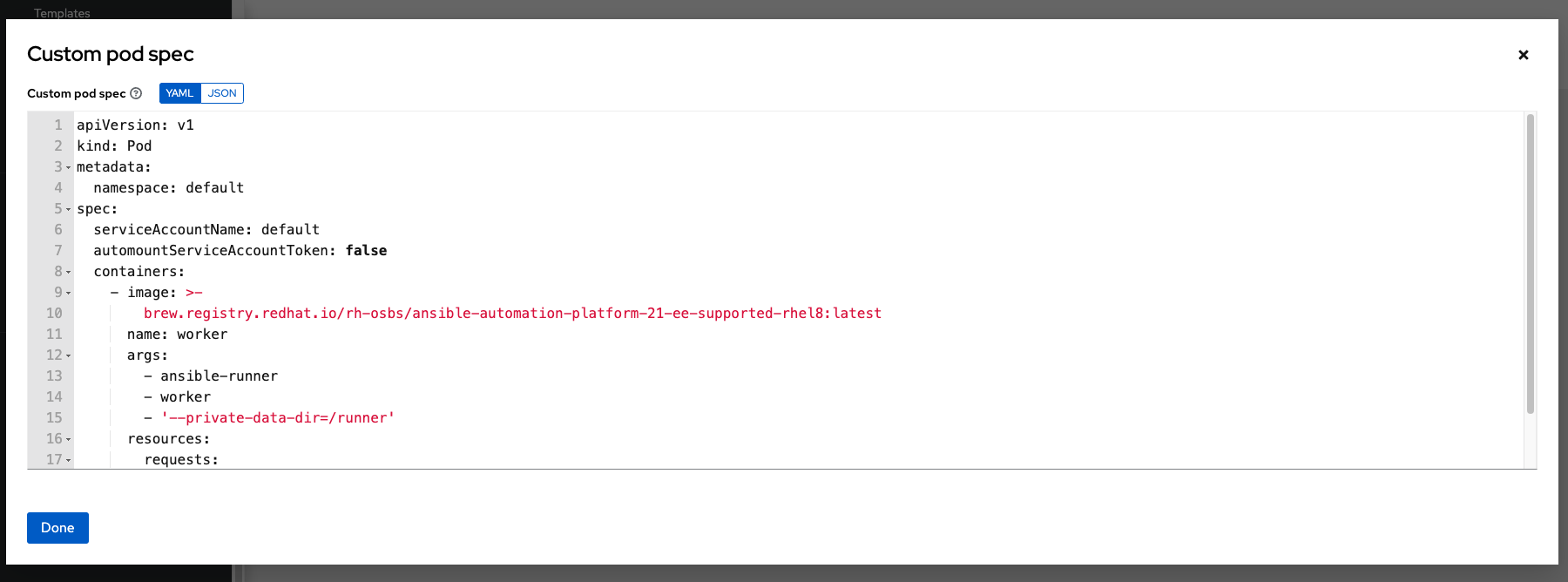
8.2.2. Pod 仕様のカスタマイズ¶
Ansible Automation Platform にはデフォルトのシンプルな Pod の仕様が用意されていますが、カスタムの YAML (または JSON) ドキュメントを指定して、デフォルトの Pod の仕様をオーバーライドすることができます。このフィールドでは、有効な Pod JSON または YAML として「シリアル化」できる任意のカスタムフィールド (つまり ImagePullSecrets) が使用可能です。オプションの完全な一覧は OpenShift documentation にあります。
Pod の仕様をカスタマイズするには、トグルを使用して Pod Spec Override フィールドで名前空間を指定し、Pod Spec Override フィールドを有効にして展開し、作業が完了したら Save をクリックします。
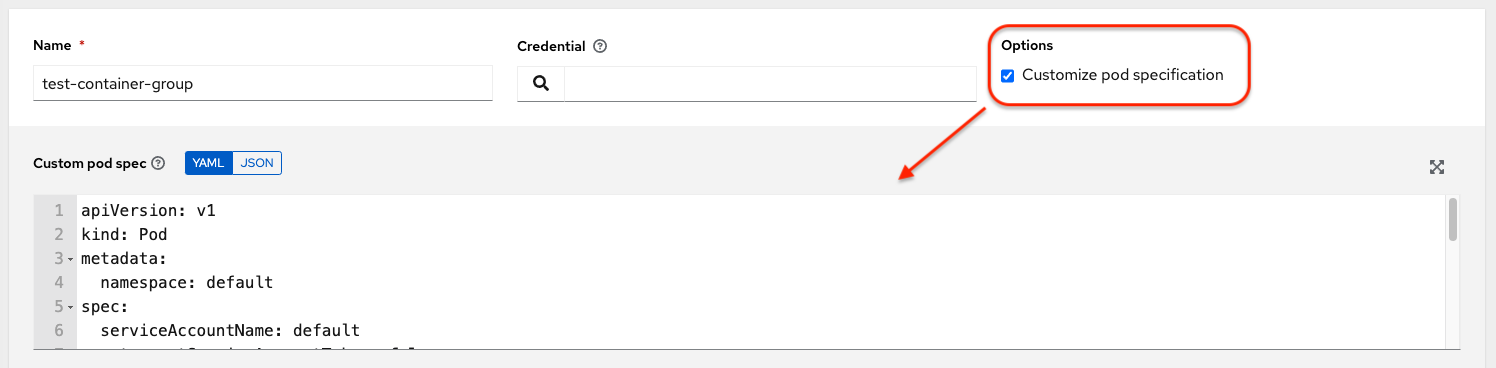
必要に応じて、追加のカスタマイズを指定できます。カスタマイズウィンドウ全体を表示するには、Expand をクリックします。
注釈
ジョブの起動時に使用されるイメージは、ジョブに関連付けられている execution environment によって決まります。コンテナーレジストリーの認証情報が execution environment に関連付けられている場合は、その後、コントローラーは ImagePullSecret を作成して、イメージをプルします。秘密を管理する権限をサービスアカウントに付与したくない場合は、ImagePullSecret を事前に作成して Pod 仕様に指定して、仕様する execution environment から認証情報を省略する必要があります。
イメージのプルシークレットを作成する方法は、Red Hat Container Registry Authentication article の「他のセキュアなレジストリーからのイメージを参照する pod の許可」を参照してください。
コンテナーグループが正常に作成されると、新規に作成されたコンテナーグループの Details タブがそのまま表示され、コンテナーグループの情報をレビューして編集することができます。これは、Instance Group リンクから編集 ( ) ボタンをクリックして開くメニューと同じです。また、Instances を編集して、このインスタンスグループに関連付けられた Jobs をレビューすることも可能です。
) ボタンをクリックして開くメニューと同じです。また、Instances を編集して、このインスタンスグループに関連付けられた Jobs をレビューすることも可能です。
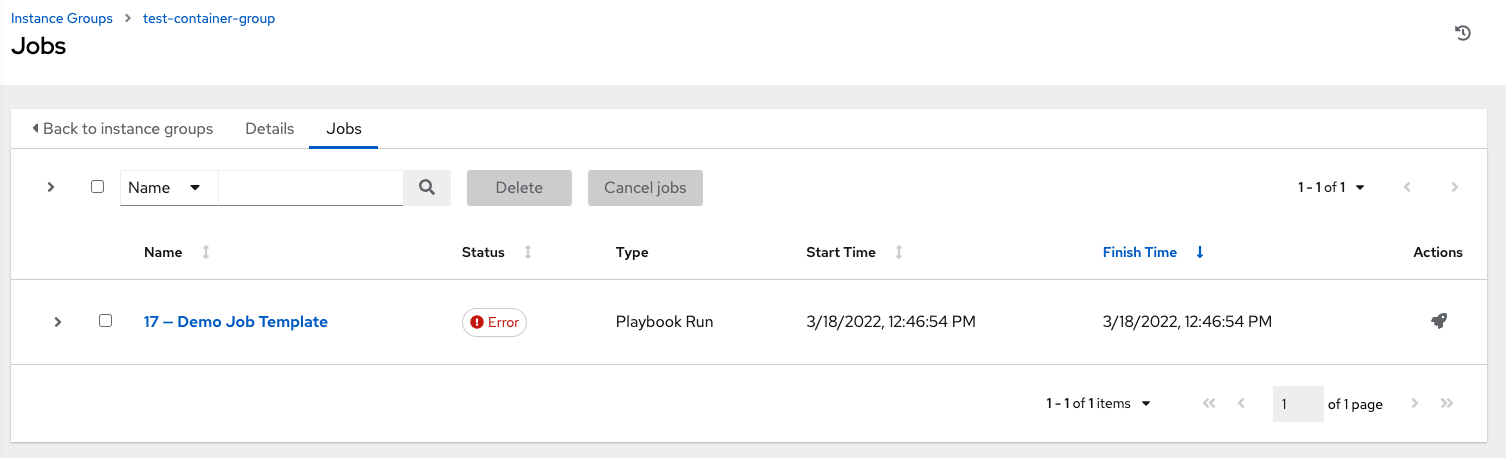
コンテナーグループとインスタンスグループは適宜ラベル付けされます。
注釈
カスタムの Pod 仕様を指定している場合でも、デフォルトの pod_spec が変更されていると、アップグレードが困難な場合があります。マニフェストの多くは任意の名前空間に適用することができますが、名前空間を個別に指定すると、大抵の場合はその名前空間をオーバーライドするだけですみます。同様に、デフォルトのジョブランナーコンテナーの各種バージョンに、プラットフォームの各種リリースのデフォルトイメージを固定する場合も注意が必要です。デフォルトイメージが Pod の仕様で指定されている場合は、デフォルトの Pod 仕様に対して行われた新しいデフォルトの変更は、アップグレードには反映されません。
8.2.3. コンテナーグループ機能の検証¶
コンテナーのデプロイと終了を確認するには、以下を実行します。
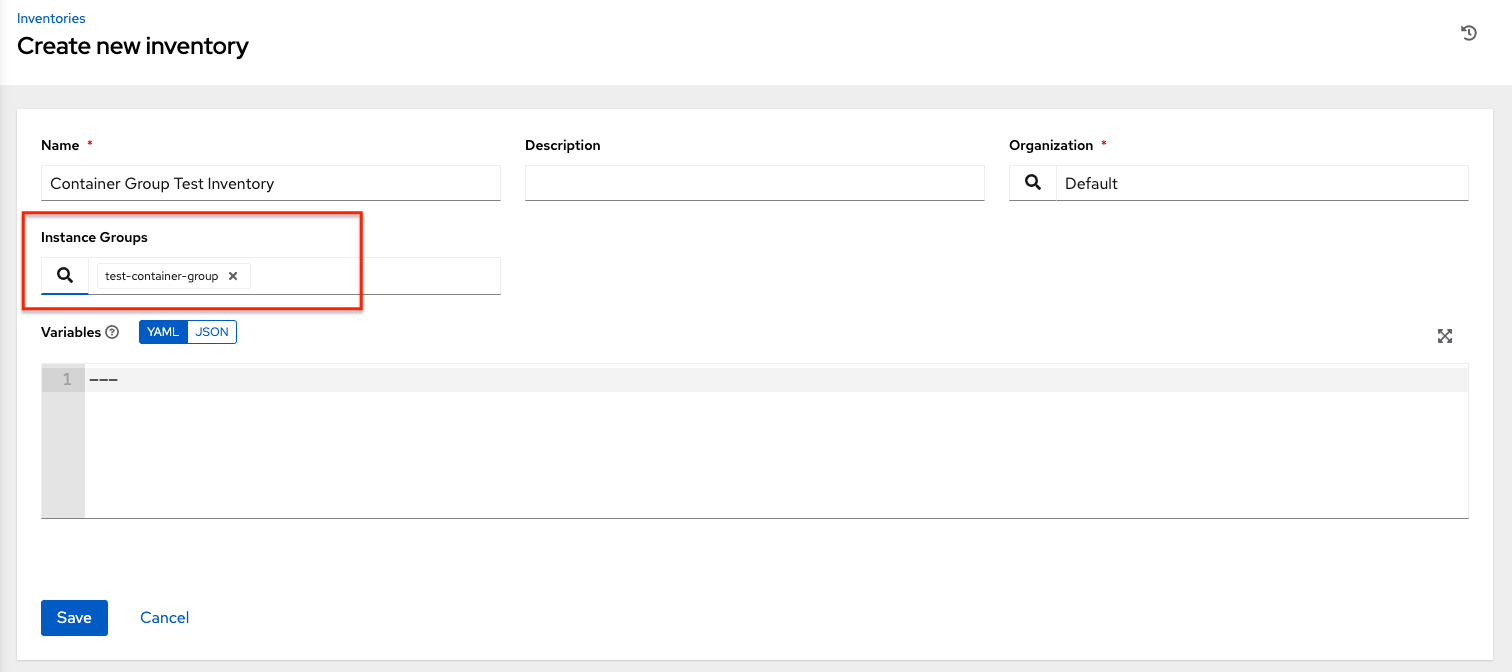
模擬インベントリーを作成し、インスタンスグループ フィールドにコンテナーグループの名前を入力してコンテナーグループをそのインベントリーに関連付けます。詳細については、『Automation Controller User Guide』の「新規インベントリーの追加」を参照してください。
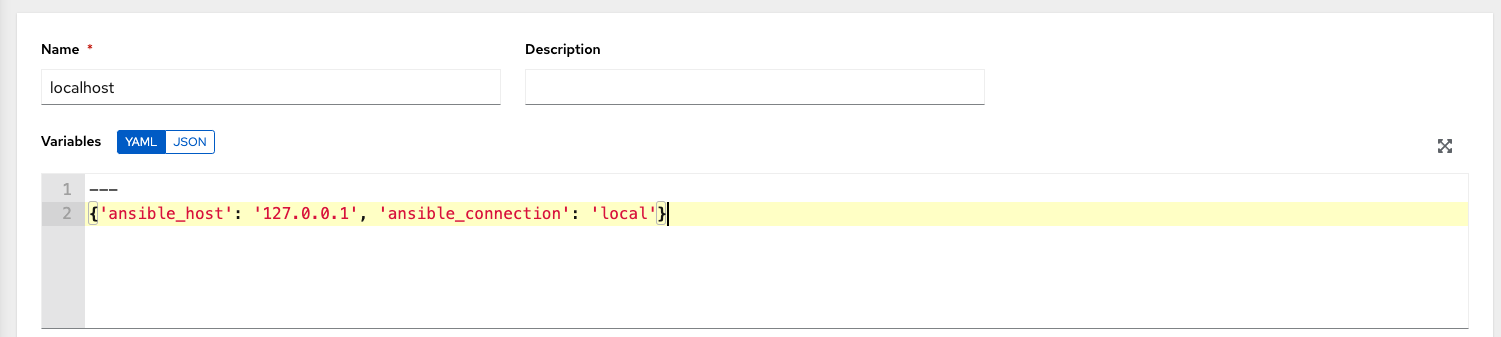
以下の変数を使用して、インベントリーに「localhost」ホストを作成します。
{'ansible_host': '127.0.0.1', 'ansible_connection': 'local'}
ping または setup モジュールを使用して、localhost に対してアドホックジョブを起動します。マシンの認証情報 フィールドは必須ですが、このシンプルなテストではどちらを選択してもかまいません。
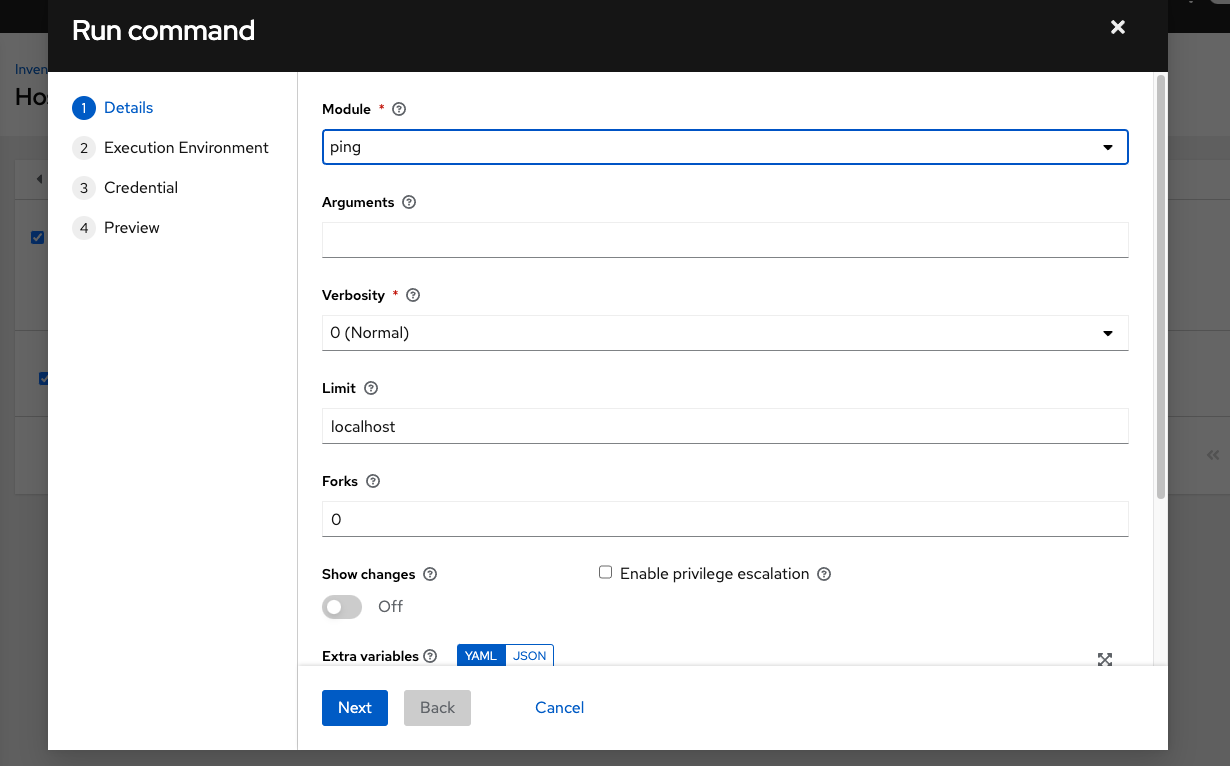
ジョブの詳細ビューに、アドホックジョブの 1 つを使用してコンテナーに正常に到達したことが表示されます。
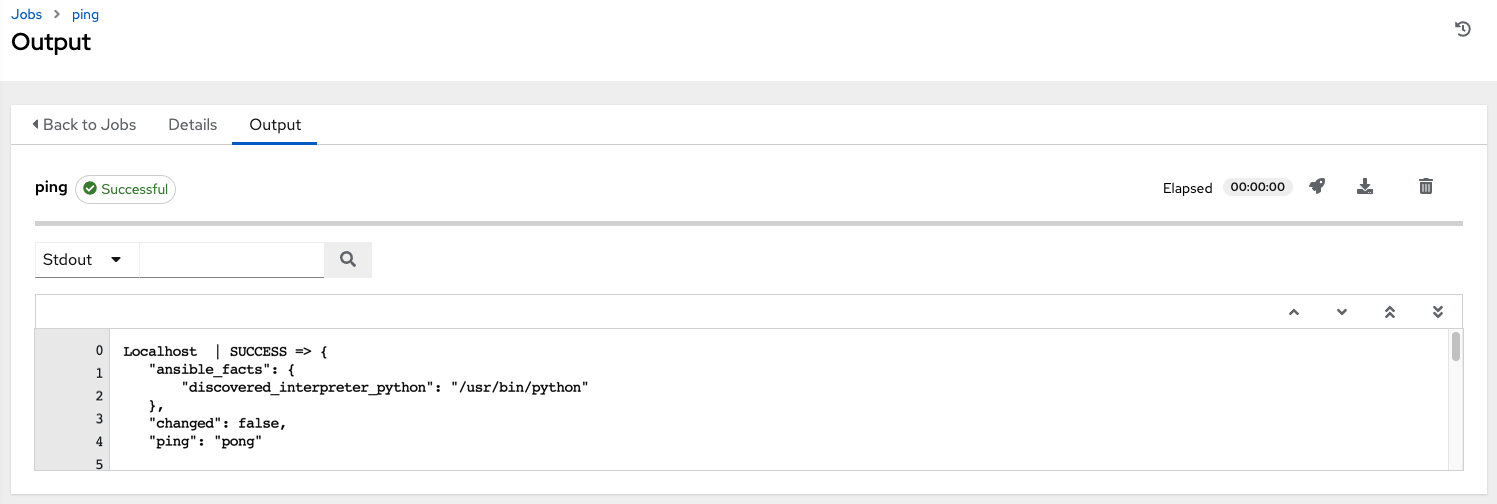
OpenShift UI を使用している場合には、Pod のデプロイ時や終了時に、Pod が表示されたり非表示になったりします。また、CLI を使用して namespace で get pod の操作を実行すると、これらの同じイベントがリアルタイムで発生することを確認できます。
8.2.4. コンテナーグループジョブの表示¶
コンテナーグループに関連付けられたジョブを実行すると、そのジョブの詳細を 詳細 ビューと、関連付けられたコンテナーグループ、および起動した実行環境で確認できます。
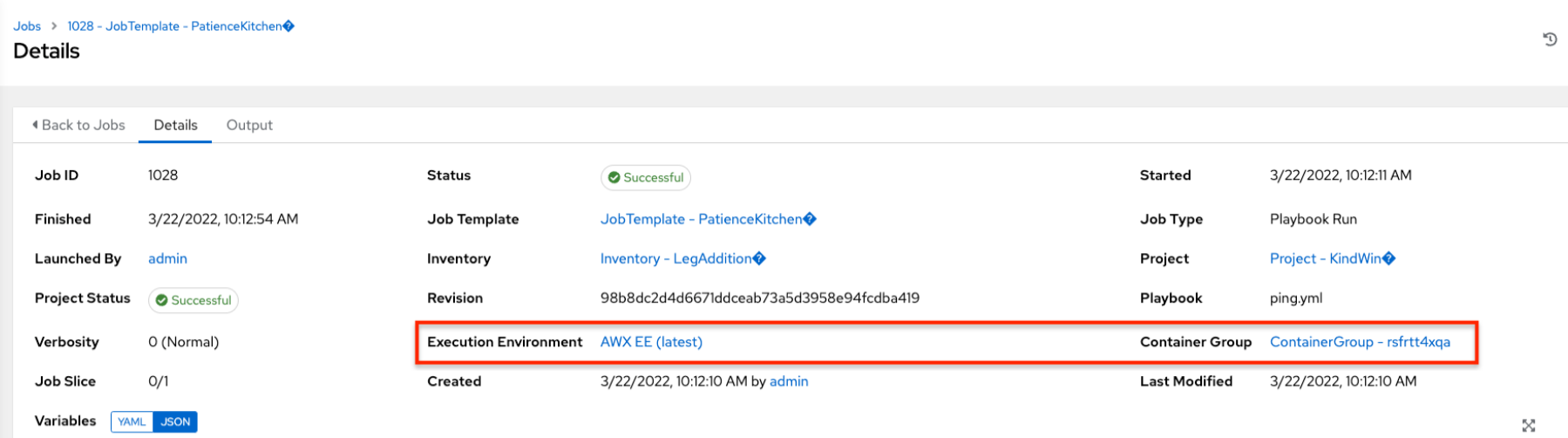
8.2.5. Kubernetes API の障害状態¶
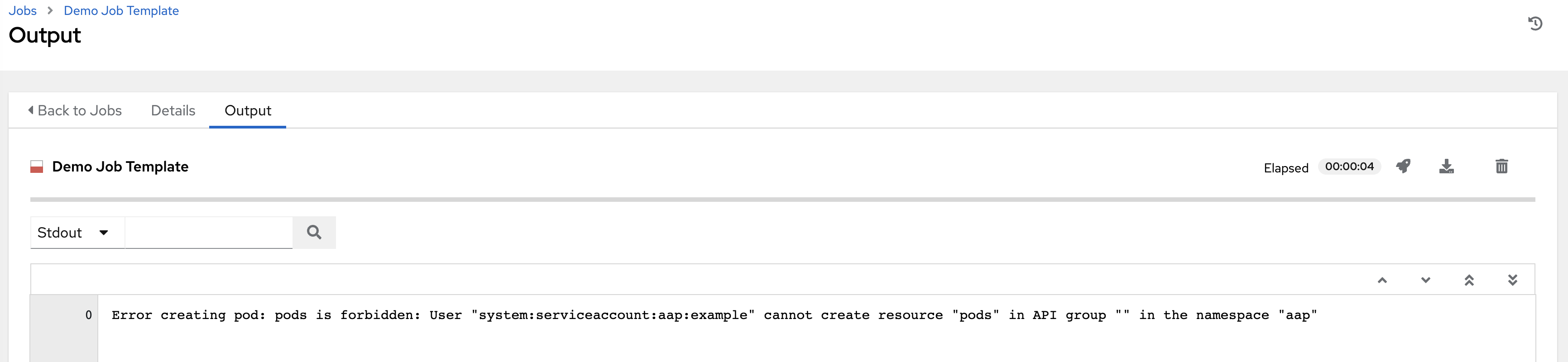
コンテナーグループを実行しており、Kubernetes API からリソースのクォータを超えたという応答があると、コントローラーはジョブを保留状態のままにします。他の障害では、以下の例のように、障害の理由を示す エラーの詳細 フィールドのトレースバックになります。
8.2.6. コンテナーの容量制限¶
コンテナーの容量制限と割り当ては、Kubernetes API のオブジェクトを介して定義されます。
特定の namespace 内のすべての Pod に制限を設定するには、
LimitRangeオブジェクトを使用します。Quotas and Limit Ranges に関しては、OpenShift のドキュメントを参照してください。コントローラーによって起動した Pod 定義に直接制限を設定するには、Customize the Pod spec を参照し、OpenShift のドキュメントを参照してオプションを compute resources に設定します。
注釈
コンテナーグループは、通常のノードが使用する容量アルゴリズムを使用しません。たとえば、フォークの数をジョブテンプレートレベルで明示的に設定する必要があります。コントローラーでフォークが構成されている場合、その設定はコンテナーに渡されます。