12. Tower 日志记录和聚合¶
日志记录是 Ansible Tower 3.1.0 中引入的一个独立功能,它能够将详细的日志发送到多种第 3 方外部日志聚合服务。可以连接到此数据的服务将可以了解 Tower 的使用情况或技术倾向。这些数据可用于分析基础架构中的事件、监控异常以及将一个服务中的事件与另一个服务中的事件相关联。对于 Tower 非常有用的数据类型是作业事实 (fact) 数据、作业事件/作业运行、活动流数据和日志消息。此数据以 JSON 格式通过 HTTP 连接发送,使用自定义处理程序中设计的最小服务特定微调或者通过导入的库实现。如果日志记录聚合器关闭,则 Tower 弃用所有未捕获的数据。
12.1. 日志记录器¶
以下是特殊的日志记录器(除了 awx,它提供通用的服务器日志),它以可预测的结构或半结构格式提供大量信息,其结构与从 API 获取数据时所需的结构相同:
job_events:提供从 Ansible 回调模块返回的数据activity_stream:显示 Ansible Tower 应用中对象的更改记录system_tracking:提供由扫描作业模板运行的 Ansible 扫描模块收集的数据awx:提供通用服务器日志,其中包括通常要写入文件的日志。它包含了所有日志都具有的标准元数据,除了它只有来自日志语句的消息。
这些日志记录器只使用 INFO 的日志级别,但 awx logger 除外,它可能是任意给定级别。
另外,标准的 Tower 日志可以通过同样的机制来提供。它包括如何启用或禁用这五个数据源中的每个源,而无需在本地设置文件中操作复杂的字典,以及调整标准 Tower 日志消耗的日志级别。
要在 Ansible Tower 中配置各种日志记录组件,请在左侧导航栏中的 (![]() ) 菜单中选择 System。
) 菜单中选择 System。
12.1.1. 日志消息 schema¶
所有日志记录器的通用 schema:
cluster_host_id:Tower 集群中主机的唯一标识符level:标准的 python 日志级别,它大致反映了事件的重要性。作为该功能的一部分,所有的数据日志记录器都使用 INFO 级别,但其他 Tower 日志会根据情况使用不同的级别logger_name:在设置中使用的日志记录器的名称,例如:“activity_stream”@timestamp:日志时间path:日志生成的代码中的文件路径
12.1.2. 活动流 schema¶
(通用):这使用以上列出的所有日志记录器通用的所有字段
actor:日志中记录的执行操作的用户的用户名changes:字段更改的 JSON 概述,及其旧/新值。operation:活动流中已更改的日志的基本类别,例如:“关联”。object1:有关操作的主要对象的信息,与活动流中显示的内容一致object2:如果适用,涉及该操作的第二个对象
12.1.3. 作业事件 schema¶
该日志记录器反映了保存到作业事件中的数据,除非它们可能与来自日志记录器的预期标准字段冲突,在这种情况下,字段被嵌套。特别是,job_event 模型上的字段主机给定为 event_host。在有效负载中还有一个子字典字段 event_data,它包含不同的字段,具体取决于 Ansible 事件的具体情况。
这个日志记录器还包括通用字段。
12.1.4. 扫描/事实 (fact) /系统跟踪数据 schema¶
这些字段包括了服务、软件包或文件的详细字典类型字段。
(通用):这使用以上列出的所有日志记录器通用的所有字段
services:对于服务扫描,此字段会根据服务的名称包含并具有密钥。备注:周期通过弹性搜索名称来禁止,并通过我们的日志格式器替换为“_”package:对软件包扫描中的日志消息包含在内files:对文件扫描的日志消息包含在内host:主机扫描的名称适用于inventory_id:清单 id 主机位于其中
12.1.5. 作业状态更改¶
与作业事件相比,这具有较少的数据,用来提供有关作业状态变化的信息。它还旨在捕获对基于作业模板的作业以外的统一作业类型的更改。
除了常见字段外,这些日志还包含作业模型中存在的字段。
12.1.6. Tower 日志¶
除了通用字段外,这还包含带日志消息的字段 msg。错误包含一个单独的字段 traceback。这些日志可以在 Configure Tower 用户界面 ENABLE EXTERNAL LOGGING 设置中启用或禁用。
12.1.7. 日志记录聚合器服务¶
日志记录聚合器服务用于以下监控和数据分析系统:
12.1.7.1. Splunk¶
Ansible Tower 的 Splunk 日志记录集成使用 Splunk HTTP 收集器。在配置 SPLUNK 日志记录聚合器时,将完整 URL 添加到 HTTP 事件收集器主机,如下例所示:
https://yourtowerfqdn.com/api/v2/settings/logging
{
"LOG_AGGREGATOR_HOST": "https://yoursplunk:8088/services/collector/event",
"LOG_AGGREGATOR_PORT": null,
"LOG_AGGREGATOR_TYPE": "splunk",
"LOG_AGGREGATOR_USERNAME": "",
"LOG_AGGREGATOR_PASSWORD": "$encrypted$",
"LOG_AGGREGATOR_LOGGERS": [
"awx",
"activity_stream",
"job_events",
"system_tracking"
],
"LOG_AGGREGATOR_INDIVIDUAL_FACTS": false,
"LOG_AGGREGATOR_ENABLED": true,
"LOG_AGGREGATOR_TOWER_UUID": ""
}
Splunk HTTP 事件收集器默认在 8088 上侦听,因此需要提供完整的 HEC 事件 URL(附带端口),以便成功处理传入请求。这些值在以下示例中输入:
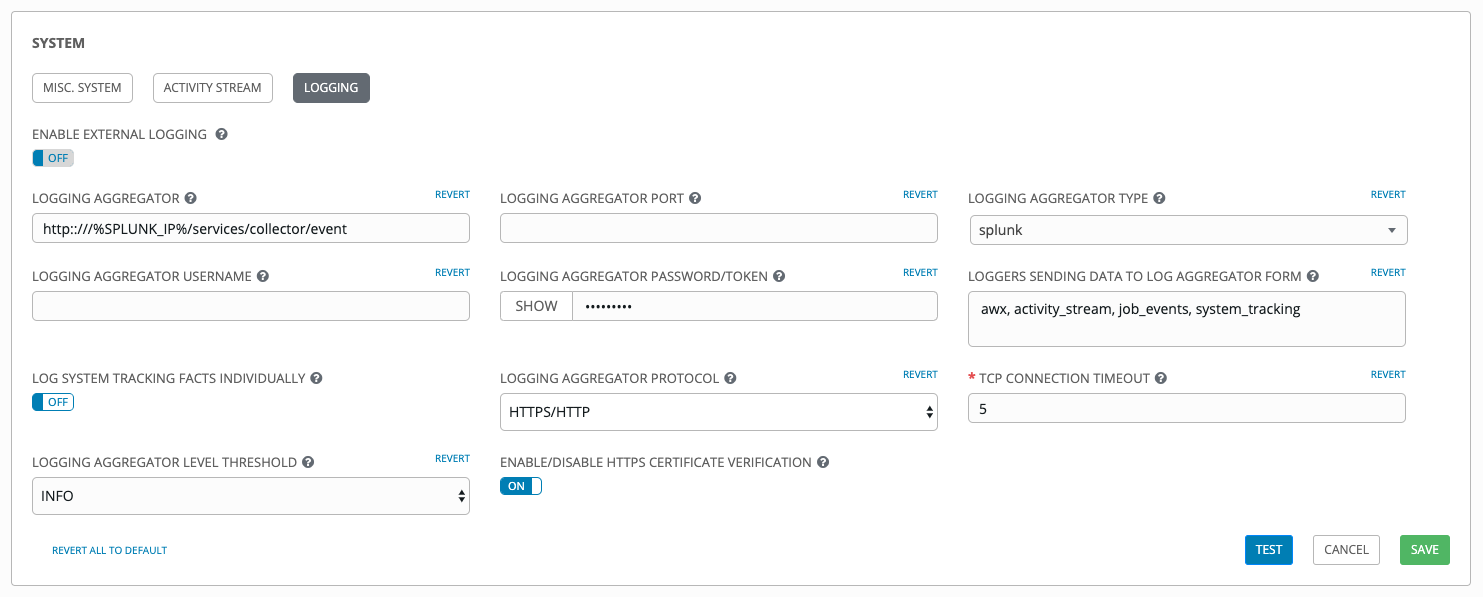
有关配置 HTTP 事件收集器的进一步说明,请参阅 Splunk documentation。
12.1.7.2. Loggly¶
要通过 Loggly 的 HTTP 端点来设置日志的发送,请参阅 https://www.loggly.com/docs/http-endpoint/. Loggly 使用 http://logs-01.loggly.com/inputs/TOKEN/tag/http/ 描述的 URL 惯例。在下例中,它已被输入到 Logging Aggregator 字段中:

12.1.7.4. 弹性堆栈(以前称为 ELK 堆栈)¶
如果从头开始,基于您自己版本的弹性堆栈,您唯一需要的修改是将以下几行添加到 logstash logstash.conf 文件中:
filter {
json {
source => "message"
}
}
注解
在 Elastic 5.0.0 中引入了向后兼容的更改,且可能需要根据所使用的版本进行不同的配置。
12.2. 使用 Tower 设置日志记录¶
将日志记录设置为任何聚合器类型:
点击左侧导航栏中的 Settings (
 ) 图标。
) 图标。
选择 System。
在系统屏幕中,选择 Logging 选项卡。
从提供的字段中设置可配置选项:
Enable External Logging:如果要将日志发送到外部日志聚合器,请点击切换按钮切换到 ON。
Logging Aggregator:输入您要发送日志的主机名或 IP 地址。
Logging Aggregator Port:如果聚合器需要端口,请为其指定端口。
注解
当连接类型为 HTTPS 时,您可以输入主机名作为带有端口号的 URL,因此不需要再次输入端口。但 TCP 和 UDP 连接由主机名和端口号组合决定,而不是 URL 决定。如果是 TCP/UDP 连接,则在指定字段中提供端口。如果在 host 字段(Logging aggregator 字段)中输入 URL,则其主机名部分将被提取为实际主机名。
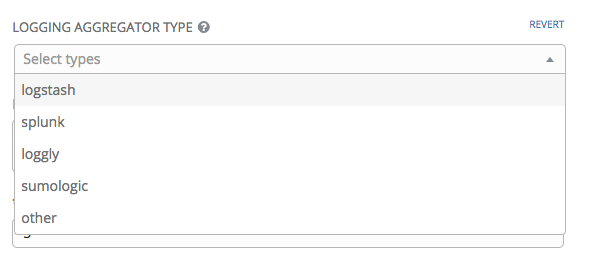
Logging Aggregator Type:点击可从下拉菜单中选择聚合器服务:
Logging Aggregator Username:如果需要,请输入日志聚合器的用户名。
Logging Aggregator Password/Token:如果需要,请输入日志聚合器的密码。
Loggers to Send Data to the Log Aggregator Form:所有四类数据都是默认预先填充。点击字段旁的工具提示
 图标可查看每种数据类型的附加信息。删除您不想要的数据类型。
图标可查看每种数据类型的附加信息。删除您不想要的数据类型。
Log System Tracking Facts Individually:点击工具提示
图标可查看是否要打开的附加信息,或者默认保持关闭。Logging Aggregator Protocol:点击选择一个连接类型(协议)与日志聚合器通信。后续选项根据所选协议的不同而有所变化。
TCP Connection Timeout:以秒为单位指定连接超时时间。此选项仅适用于 HTTPS 和 TCP 日志聚合协议。
Logging Aggeregator Level Threshold:选择希望日志处理器报告的严重性级别。
Enable/Disable HTTPS Certificate Verification:HTTPS 日志协议默认启用证书验证。如果您不希望日志处理器在建立连接前验证由外部日志聚合器发送的 HTTPS 证书,请点击切换按钮切换到 OFF。
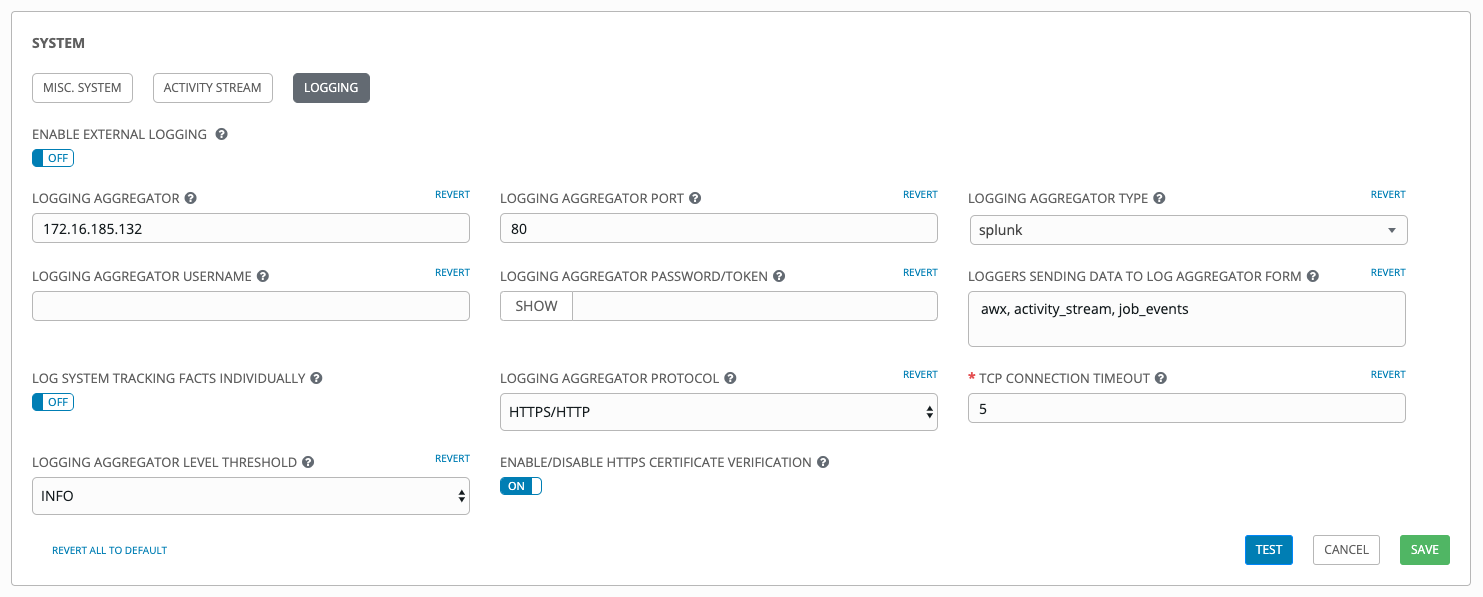
检查您选择的日志记录聚合的条目。以下是为 Splunk 设置的示例:
要验证您的配置是否正确设置,请点击**Test**。这可以通过发送测试日志消息并检查响应代码来验证日志配置是否正确。
完成后,点击 Save 应用设置,或者点 Cancel 取消更改。