4. Inventory File Importing¶
The controller allows you to choose an inventory file from source control, rather than creating one from scratch. This function is the same as custom inventory scripts, except that the contents are obtained from source control instead of editing their contents browser. This means, the files are non-editable and as inventories are updated at the source, the inventories within the projects are also updated accordingly, including the group_vars and host_vars files or directory associated with them. SCM types can consume both inventory files and scripts, the overlap between inventory files and custom types in that both do scripts.
Any imported hosts will have a description of “imported” by default. This can be overridden by setting the _awx_description variable on a given host. For example, if importing from a sourced .ini file, you could add the following host variables:
[main]
127.0.0.1 _awx_description="my host 1"
127.0.0.2 _awx_description="my host 2"
Similarly, group descriptions also default to “imported”, but can be overridden by the _awx_description as well.
In order to use old inventory scripts in source control, see Export old inventory scripts in the Automation Controller User Guide for detail.
4.1. Custom Dynamic Inventory Scripts¶
A custom dynamic inventory script stored in version control can be imported and run. This makes it much easier to make changes to an inventory script — rather than having to copy and paste one into the controller, it is pulled directly from source control and then executed. The script must be written to handle any credentials needed for doing its work and you are responsible for installing any Python libraries needed by the script (which is the same requirement for custom dynamic inventory scripts). And this applies to both user-defined inventory source scripts and SCM sources as they are both exposed to Ansible virtualenv requirements related to playbooks.
You can specify environment variables when you edit the SCM inventory source itself. For some scripts, this will be sufficient, however, this is not a secure way to store secret information that gives access to cloud providers or inventory.
The better way is to create a new credential type for the inventory script you are going to use. The credential type will need to specify all the necessary types of inputs. Then, when you create a credential of this type, the secrets will be stored in an encrypted form. If you apply that credential to the inventory source, the script will have access to those inputs like environment variables or files.
For more detail, refer to Credential types.
4.1.1. Update on Project Update¶
If the inventory source contains static content, it may be desirable to automatically update its content whenever the SHA-1 hash of its source project changes. This can be done by configuring the inventory source to Update on Project Update.
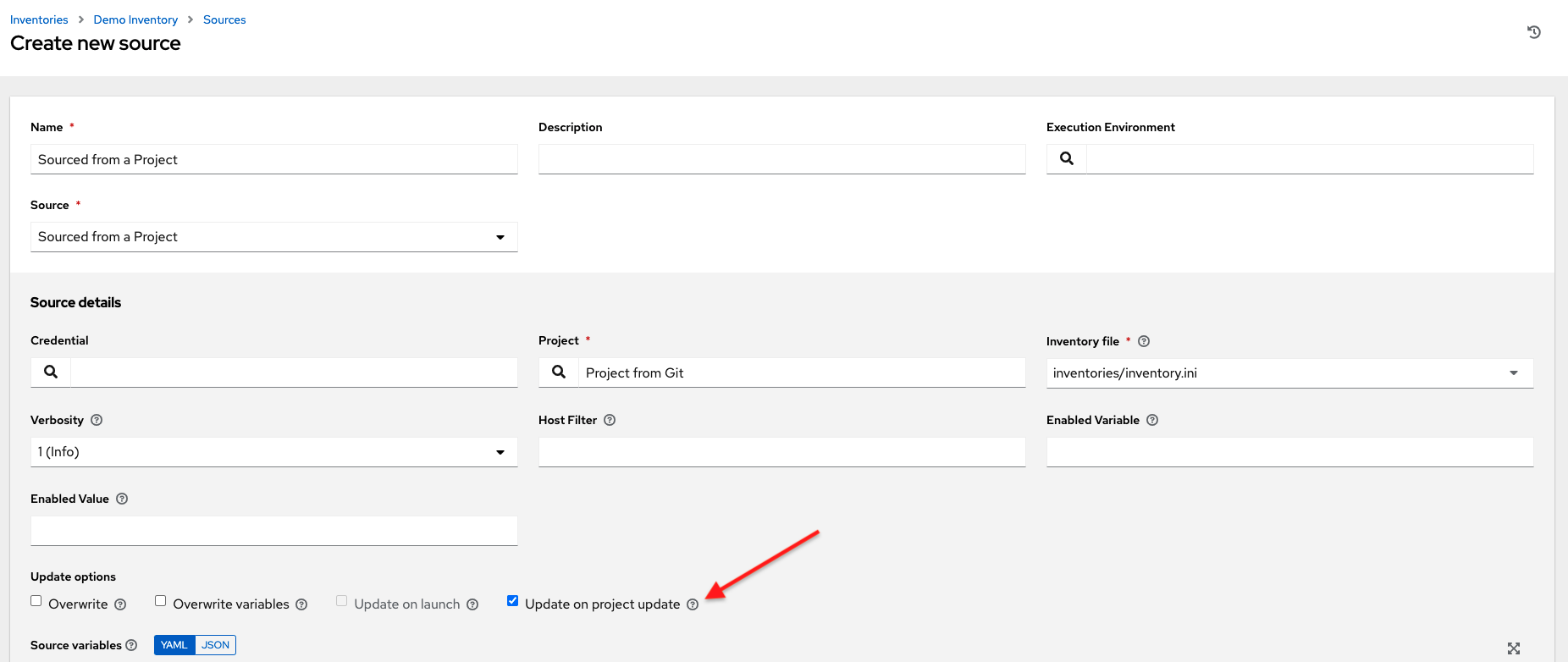
When this box is checked, the inventory source will not allow update-on-launch. Update-on-launch is important because some configurations require it. For example, when you set up a project that the inventory references to update in series before a Job Template runs, so that the inventory that the Job Template runs will have the updated form of that inventory. However, there are two other alternative ways to accomplish this:
You can make a job template that uses a project as well as an inventory that updates from that same project. In this case, you can set the project to
update_on_launch, in which case it will trigger an inventory update, if needed.If you must use a different project for the playbook than for the inventory source, then you can still place the project in a workflow and then have a job template run on success of the project update.
This is guaranteed to have the inventory update “on time” (meaning that the inventory changes are complete before the job template is launched), because the project does not transition to the completed state until the inventory update is finished.
Note
A failed inventory update does not mark the project as failed. Also, not every project update will trigger a corresponding inventory update. If the project revision has not changed and the inventory has not been edited, the inventory update will not execute.
Also, projects are not blocked from updating while a related job is running. In cases where you have a big project (around 10 GB), disk space on /tmp may be an issue.
4.2. SCM Inventory Source Fields¶
The source fields used are:
source_project: project to usesource_path: relative path inside the project indicating a directory or a file. If left blank, “” is still a relative path indicating the root directory of the projectsource_vars: if set on a “file” type inventory source then they will be passed to the environment vars when running
An update of the project automatically triggers an inventory update where it is used. An update of the project is scheduled immediately after creation of the inventory source. Neither inventory nor project updates are blocked while a related job is running. In cases where you have a big project (around 10 GB), disk space on /tmp may be an issue.
You can specify a location manually in the controller User Interface from the Create Inventory Source page. Refer to the Inventories section of the Automation Controller User Guide for instructions on creating an inventory source.
This listing should be refreshed to latest SCM info on a project update. If no inventory sources use a project as an SCM inventory source, then the inventory listing may not be refreshed on update.
For inventories with SCM sources, the Job Details page for inventory updates show a status indicator for the project update as well as the name of the project. The status indicator links to the project update job. The project name links to the project.
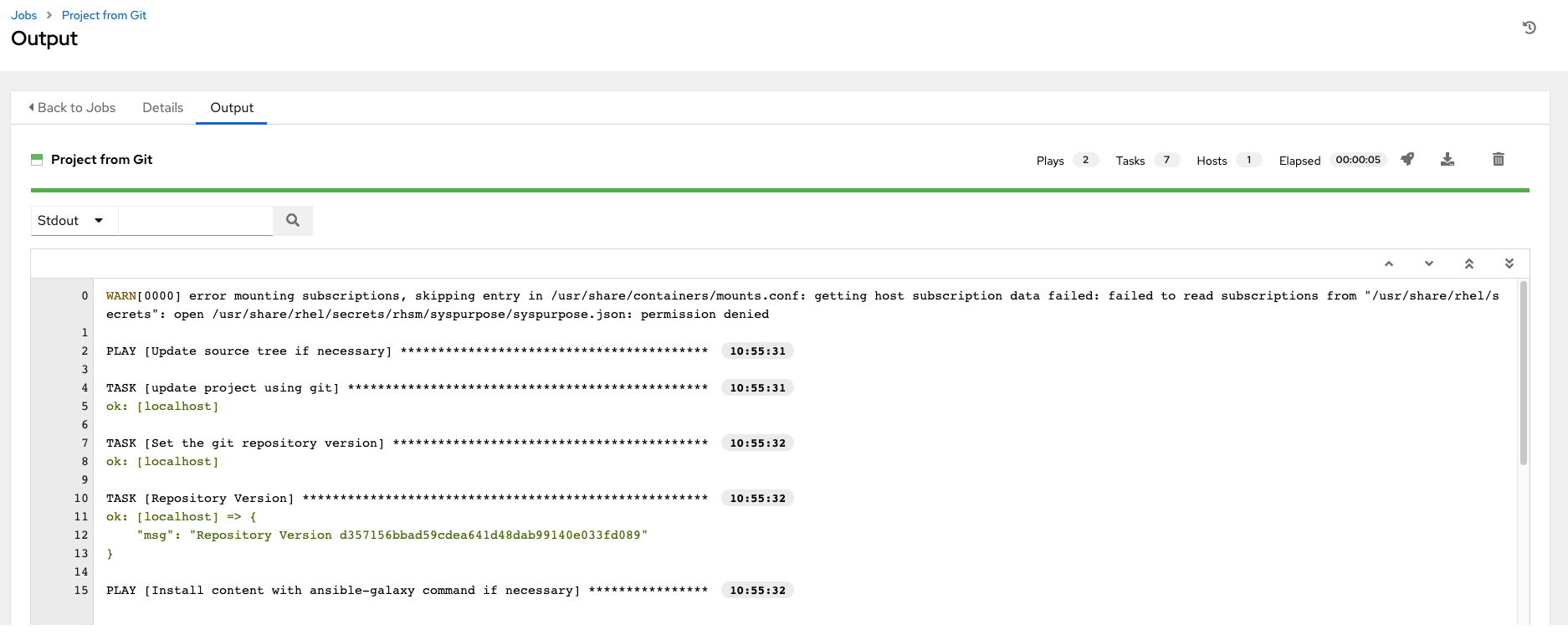
An inventory update can be performed while a related job is running.
4.2.1. Supported File Syntax¶
automation controller uses the ansible-inventory module from Ansible to process inventory files, and supports all valid inventory syntax that the controller requires.