27. 유용성 분석 및 데이터 수집¶
Usability data collection is included with automation controller to collect data to better understand how controller users specifically interact with it, to help enhance future releases, and to continue streamlining your user experience.
Only users installing a trial of Red Hat Ansible Automation Platform or a fresh installation of automation controller are opted-in for this data collection.
이 분석 수집에 참여하는 방법을 변경하려는 경우 왼쪽 탐색 모음에서 **설정**을 클릭하여 **사용자 인터페이스 설정**에서 설정을 옵트아웃하거나 변경할 수 있습니다.
Automation controller collects user data automatically to help improve the product. You can control the way the controller collects data by setting your participation level in the User Interface settings in the Settings menu.
사용자 분석 추적 상태 드롭다운 목록에서 원하는 데이터 수집 수준을 선택합니다.
해제: 모든 데이터 수집을 차단합니다.
익명: 특정 사용자 데이터 없이 데이터 수집을 활성화합니다.
세부 정보: 특정 사용자 데이터를 포함하여 데이터 수집을 활성화합니다.
자세한 내용은 https://www.redhat.com/en/about/privacy-policy에서 Red Hat 개인 정보 취급 방침을 참조하십시오.
27.1. 자동화 분석¶
라이센스를 처음 가져올 때 Ansible Automation Platform 서브스크립션에 포함된 클라우드 서비스인 |AA|를 지원하는 데이터 수집과 관련된 옵션이 제공되었습니다. |AA| 옵트인이 적용되려면 automation controller 인스턴스가 |rhel|에서 실행되고 있어야 합니다.
Red Hat Insights와 마찬가지로 |AA|는 필요한 최소한의 데이터만 수집하도록 빌드되었습니다. 인증 정보 시크릿, 개인 데이터, 자동화 변수 또는 작업 출력은 수집되지 않습니다. 자세한 내용은 아래의 `Details of data collection`_를 참조하십시오.
이 기능을 활성화하려면 |AA|에 대해 데이터 수집을 켜고 설정 메뉴에 있는 시스템 구성 옵션 목록의 **기타 시스템 설정**에서 Red Hat 고객 인증 정보를 입력합니다.
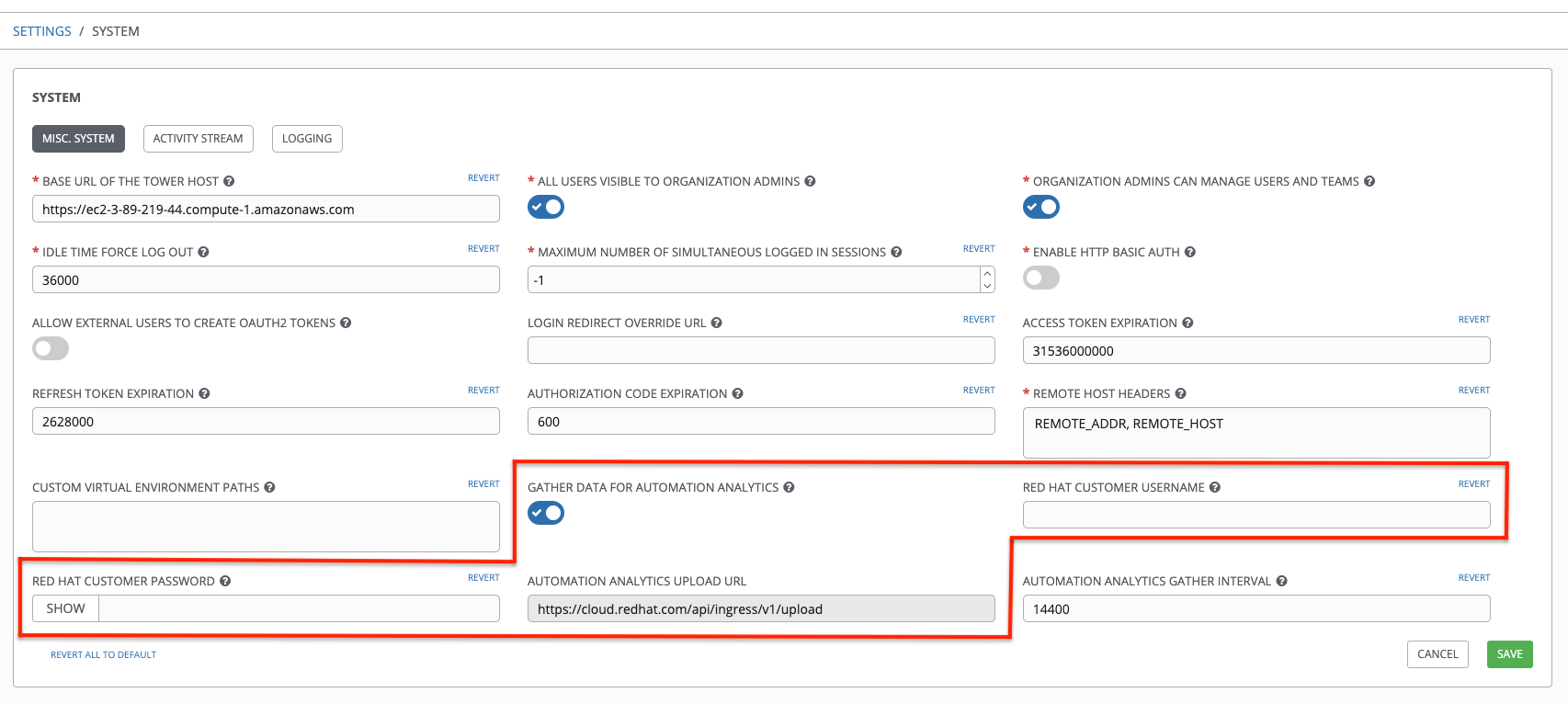
자동화 분석 업로드 URL 필드는 인사이트 데이터 수집이 업로드되는 위치로 미리 채워져 있습니다.
기본적으로 Automation Analytics 데이터는 4시간마다 수집되며, 기능을 활성화할 경우 최대 1개월 이전까지(또는 이전 수집까지) 데이터가 수집됩니다. 언제든지 시스템 구성 창의 **기타 시스템 설정**에서 이 데이터 수집을 끌 수 있습니다.
다음 끝점 중 하나에서 ``INSIGHTS_TRACKING_STATE = True``를 지정하여 API를 통해 이 설정을 활성화할 수도 있습니다.
api/v2/settings/allapi/v2/settings/system
이 데이터 수집에서 생성된 |AA|는 Red Hat Cloud Services 포털에 있습니다.
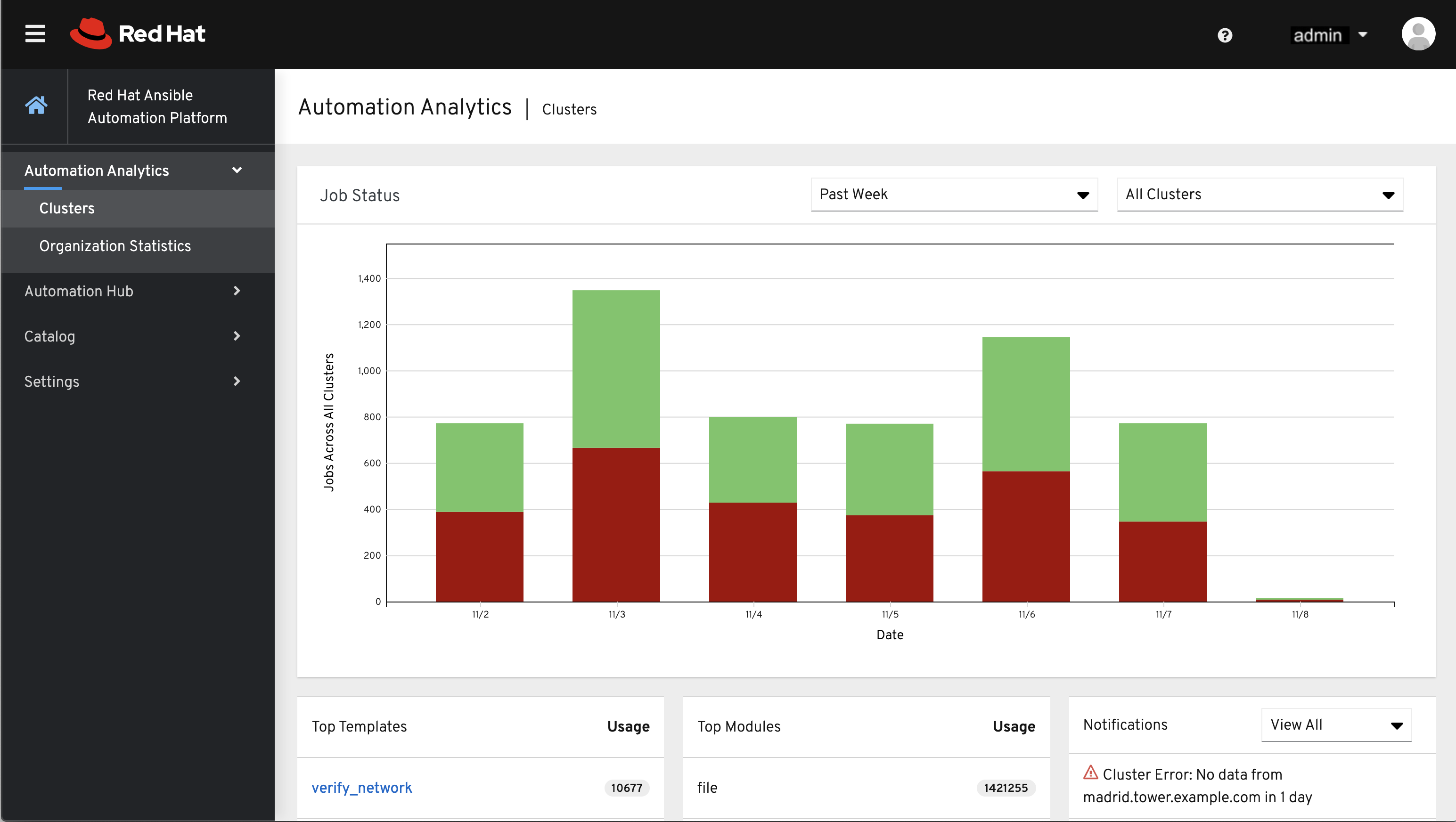
클러스터 데이터가 기본 뷰입니다. 이 그래프는 일정 기간 동안 모든 컨트롤러 클러스터가 작업 실행 수를 나타냅니다. 위 예제에서는 성공적으로 실행된 작업 수(녹색)와 실패한 작업 수(빨간색)로 구성된 누적 막대형 차트로 1주 기간을 표시합니다.
또는 단일 클러스터를 선택하여 해당 작업 상태 정보를 볼 수 있습니다.
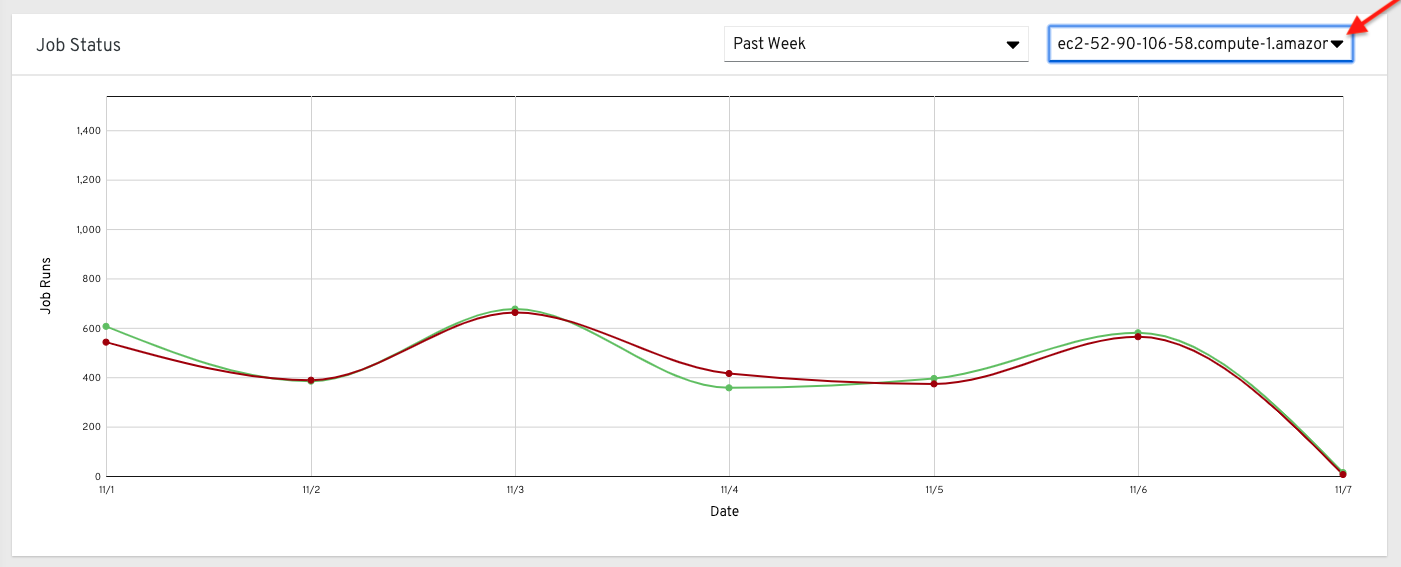
이 멀티 꺾은선형 차트는 지정된 기간 동안 단일 컨트롤러 클러스터가 작업 실행 수를 나타냅니다. 이 예제에서는 성공적으로 실행 중인 작업 수(녹색)와 실패한 작업 수(빨간색)로 구성된 1주 기간을 표시합니다. 1주, 2주, 월간 증분 기간에 선택한 클러스터에 대한 성공한 작업 실행 수와 실패한 작업 실행 수를 지정할 수 있습니다.
왼쪽 탐색 창에서 **조직 통계**를 클릭하여 다음 정보를 확인합니다.
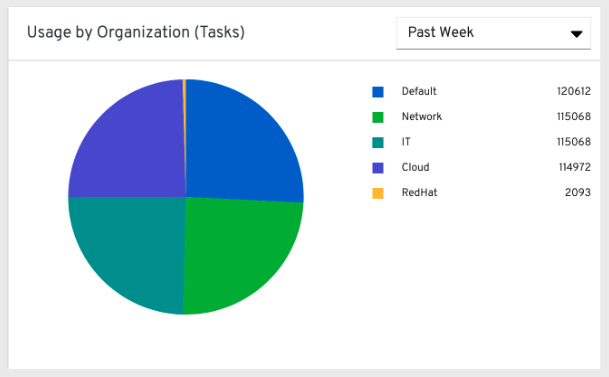
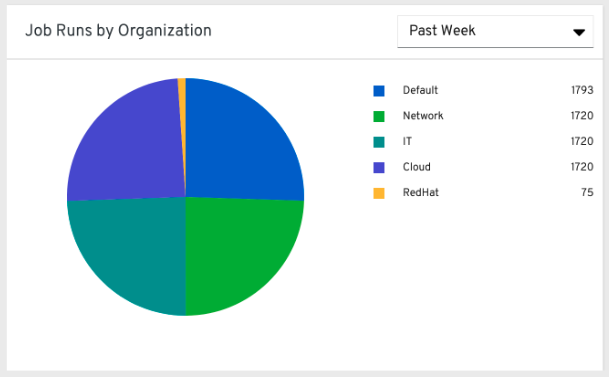
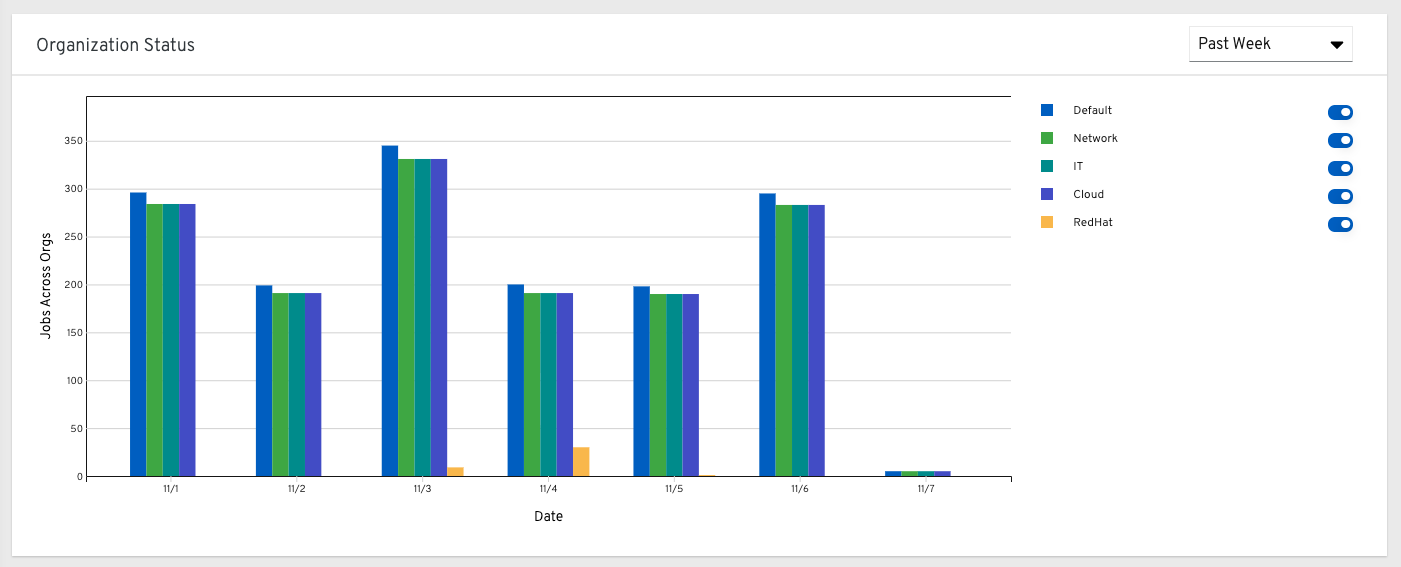
27.1.3. 조직 상태¶
이 가로 막대형 차트는 조직에서 특정 날짜에 실행한 작업 수로 계산되는, 조직 및 날짜별 컨트롤러 사용량을 나타냅니다. 또는 1주, 2주, 월간 증분 기간의 조직별 작업 실행 수를 표시하도록 지정할 수 있습니다.
27.2. 데이터 수집 세부 정보¶
|AA|는 |at|에서 특정 데이터 클래스를 수집합니다.
활성화되는 기능 및 사용 중인 운영 체제와 같은 기본 구성
용량과 상태를 포함한 컨트롤러 환경과 호스트의 토폴로지 및 상태
자동화 리소스 수:
조직, 팀, 사용자
인벤토리 및 호스트
인증 정보(유형별로 인덱싱됨)
프로젝트(유형별로 인덱싱됨)
템플릿
스케줄
활성 세션
실행 중인 작업 및 보류 중인 작업
작업 실행 세부 정보(시작 시간, 완료 시간, 시작 유형, 성공)
자동화 작업 세부 정보(성공, 호스트 ID, 플레이북/역할, 작업 이름, 사용된 모듈)
데이터 수집 요구 사항을 충족할 수 있도록 awx-manage gather_analytics``(–ship`` 제외)를 사용하여 컨트롤러에서 전송하는 데이터를 검사할 수 있습니다. 이렇게 하면 Red Hat으로 전송되는 분석 데이터가 포함된 tarball이 생성됩니다.
이 파일에는 여러 JSON 및 CSV 파일이 포함되어 있습니다. 파일마다 다른 분석 데이터 세트가 포함됩니다.
27.2.1. manifest.json¶
manifest.json은 분석 데이터 매니페스트입니다. 컬렉션에 포함된 각 파일과 포함된 해당 파일의 스키마 버전을 설명합니다. 예제 매니페스트는 다음과 같습니다.
{
"config.json": "1.1",
"counts.json": "1.0",
"cred_type_counts.json": "1.0",
"events_table.csv": "1.1",
"instance_info.json": "1.0",
"inventory_counts.json": "1.2",
"job_counts.json": "1.0",
"job_instance_counts.json": "1.0",
"org_counts.json": "1.0",
"projects_by_scm_type.json": "1.0",
"query_info.json": "1.0",
"unified_job_template_table.csv": "1.0",
"unified_jobs_table.csv": "1.0",
"workflow_job_node_table.csv": "1.0",
"workflow_job_template_node_table.csv": "1.0"
}
27.2.2. config.json¶
config.json 파일에는 클러스터의 구성 끝점 /api/v2/config 서브 세트가 포함되어 있습니다. 예제 config.json은 다음과 같습니다.
{
"ansible_version": "2.9.1",
"authentication_backends": [
"social_core.backends.azuread.AzureADOAuth2",
"django.contrib.auth.backends.ModelBackend"
],
"external_logger_enabled": true,
"external_logger_type": "splunk",
"free_instances": 1234,
"install_uuid": "d3d497f7-9d07-43ab-b8de-9d5cc9752b7c",
"instance_uuid": "bed08c6b-19cc-4a49-bc9e-82c33936e91b",
"license_expiry": 34937373,
"license_type": "enterprise",
"logging_aggregators": [
"awx",
"activity_stream",
"job_events",
"system_tracking"
],
"pendo_tracking": "detailed",
"platform": {
"dist": [
"redhat",
"7.4",
"Maipo"
],
"release": "3.10.0-693.el7.x86_64",
"system": "Linux",
"type": "traditional"
},
"total_licensed_instances": 2500,
"controller_url_base": "https://ansible.rhdemo.io",
"controller_version": "3.6.3"
}
수집되는 필드의 참조:
- ansible_version
호스트의 시스템 Ansible 버전
- authentication_backends
사용 가능한 사용자 인증 백엔드. 자세한 내용은 소셜 인증 설정 및 :ref:`ag_auth_ldap`를 참조하십시오.
- external_logger_enabled
외부 로깅 활성화 여부
- external_logger_type
활성화된 경우 사용 중인 로깅 백엔드. 자세한 내용은 :ref:`ag_logging`을 참조하십시오.
- logging_aggregators
외부 로깅으로 전송되는 로깅 카테고리. 자세한 내용은 :ref:`ag_logging`을 참조하십시오.
- free_instances
라이센스에서 사용할 수 있는 호스트 수. 값이 0이면 클러스터가 라이센스를 완전히 사용하고 있습니다.
- install_uuid
설치 UUID(모든 클러스터 노드에 동일)
- instance_uuid
인스턴스 UUID(클러스터 노드마다 다름)
- license_expiry
라이센스 만료 시간(초)
- license_type
Type of the license (should be 〈enterprise〉 for most cases)
- pendo_tracking
:ref:`usability_data_collection`의 상태
- platform
클러스터를 실행 중인 운영 체제
- total_licensed_instances
라이센스의 총 호스트 수
- controller_url_base
클라이언트에서 사용하는 클러스터의 기본 URL(|AA|에 표시)
- controller_version
클러스터의 소프트웨어 버전
27.2.3. instance_info.json¶
instance_info.json 파일에는 클러스터를 구성하는 인스턴스에 대한 자세한 정보가 인스턴스 UUID별로 포함되어 있습니다. 예제 instance_info.json은 다음과 같습니다.
{
"bed08c6b-19cc-4a49-bc9e-82c33936e91b": {
"capacity": 57,
"cpu": 2,
"enabled": true,
"last_isolated_check": "2019-08-15T14:48:58.553005+00:00",
"managed_by_policy": true,
"memory": 8201400320,
"uuid": "bed08c6b-19cc-4a49-bc9e-82c33936e91b",
"version": "3.6.3"
}
"c0a2a215-0e33-419a-92f5-e3a0f59bfaee": {
"capacity": 57,
"cpu": 2,
"enabled": true,
"last_isolated_check": "2019-08-15T14:48:58.553005+00:00",
"managed_by_policy": true,
"memory": 8201400320,
"uuid": "c0a2a215-0e33-419a-92f5-e3a0f59bfaee",
"version": "3.6.3"
}
}
수집되는 필드의 참조:
- capacity
인스턴스의 작업 실행 용량. 계산 방법에 대한 자세한 내용은 <link>을(를) 참조하십시오.
- cpu
인스턴스의 CPU 코어
- memory
인스턴스의 메모리
- enabled
인스턴스가 활성화되어 작업을 수락하는지 여부
- managed_by_policy
인스턴스 그룹의 인스턴스 멤버십이 정책으로 관리되는지 또는 수동으로 관리되는지 여부
- version
인스턴스의 소프트웨어 버전
27.2.4. counts.json¶
counts.json 파일에는 클러스터의 각 관련 카테고리에 대한 총 오브젝트 수가 포함되어 있습니다. 예제 count.json은 다음과 같습니다.
{
"active_anonymous_sessions": 1,
"active_host_count": 682,
"active_sessions": 2,
"active_user_sessions": 1,
"credential": 38,
"custom_inventory_script": 2,
"custom_virtualenvs": 4,
"host": 697,
"inventories": {
"normal": 20,
"smart": 1
},
"inventory": 21,
"job_template": 78,
"notification_template": 5,
"organization": 10,
"pending_jobs": 0,
"project": 20,
"running_jobs": 0,
"schedule": 16,
"team": 5,
"unified_job": 7073,
"user": 28,
"workflow_job_template": 15
}
활성 세션 수를 제외한 이 파일의 각 항목은 ``/api/v2``의 해당 API 오브젝트를 나타냅니다.
27.2.5. org_counts.json¶
org_counts.json 파일에는 클러스터의 각 조직 및 해당 조직과 연결된 사용자 및 팀 수가 포함되어 있습니다. 예제 org_counts.json은 다음과 같습니다.
{
"1": {
"name": "Operations",
"teams": 5,
"users": 17
},
"2": {
"name": "Development",
"teams": 27,
"users": 154
},
"3": {
"name": "Networking",
"teams": 3,
"users": 28
}
}
27.2.6. cred_type_counts.json¶
cred_type_counts.json 파일에는 클러스터의 다양한 인증 정보 유형 및 각 유형의 인증 정보 수에 대한 정보가 포함되어 있습니다. 예제 cred_type_counts.json은 다음과 같습니다.
{
"1": {
"credential_count": 15,
"managed_by_controller": true,
"name": "Machine"
},
"2": {
"credential_count": 2,
"managed_by_controller": true,
"name": "Source Control"
},
"3": {
"credential_count": 3,
"managed_by_controller": true,
"name": "Vault"
},
"4": {
"credential_count": 0,
"managed_by_controller": true,
"name": "Network"
},
"5": {
"credential_count": 6,
"managed_by_controller": true,
"name": "Amazon Web Services"
},
"6": {
"credential_count": 0,
"managed_by_controller": true,
"name": "OpenStack"
},
...
27.2.7. inventory_counts.json¶
inventory_counts.json 파일에는 클러스터의 다양한 인벤토리에 대한 정보가 포함되어 있습니다. 예제 inventory_counts.json은 다음과 같습니다.
{
"1": {
"hosts": 211,
"kind": "",
"name": "AWS Inventory",
"source_list": [
{
"name": "AWS",
"num_hosts": 211,
"source": "ec2"
}
],
"sources": 1
},
"2": {
"hosts": 15,
"kind": "",
"name": "Manual inventory",
"source_list": [],
"sources": 0
},
"3": {
"hosts": 25,
"kind": "",
"name": "SCM inventory - test repo",
"source_list": [
{
"name": "Git source",
"num_hosts": 25,
"source": "scm"
}
],
"sources": 1
}
"4": {
"num_hosts": 5,
"kind": "smart",
"name": "Filtered AWS inventory",
"source_list": [],
"sources": 0
}
}
27.2.8. projects_by_scm_type.json¶
projects_by_scm_type.json 파일은 클러스터의 모든 프로젝트를 소스 제어 유형별로 분석합니다. 예제 projects_by_scm_type.json은 다음과 같습니다.
{
"git": 27,
"hg": 0,
"insights": 1,
"manual": 0,
"svn": 0
}
27.2.9. query_info.json¶
query_info.json 파일은 데이터 수집 시기와 방법에 대한 세부 정보를 제공합니다. 예제 query_info.json은 다음과 같습니다.
{
"collection_type": "manual",
"current_time": "2019-11-22 20:10:27.751267+00:00",
"last_run": "2019-11-22 20:03:40.361225+00:00"
}
collection_type은 《manual》 또는 《automatic》 중 하나입니다.
27.2.10. job_counts.json¶
job_counts.json 파일은 클러스터의 작업 기록에 대한 세부 정보를 제공하며 작업 시작 방법과 완료 상태를 설명합니다. 예제 job_counts.json은 다음과 같습니다.
{
"launch_type": {
"dependency": 3628,
"manual": 799,
"relaunch": 6,
"scheduled": 1286,
"scm": 6,
"workflow": 1348
},
"status": {
"canceled": 7,
"failed": 108,
"successful": 6958
},
"total_jobs": 7073
}
27.2.11. job_instance_counts.json¶
job_instance_counts.json 파일은 job_counts.json과 동일한 세부 정보를 인스턴스별로 분석하여 제공합니다. 예제 job_instance_counts.json은 다음과 같습니다.
{
"localhost": {
"launch_type": {
"dependency": 3628,
"manual": 770,
"relaunch": 3,
"scheduled": 1009,
"scm": 6,
"workflow": 1336
},
"status": {
"canceled": 2,
"failed": 60,
"successful": 6690
}
}
}
이 파일의 인스턴스는 instance_info에 있으므로 UUID가 아닌 호스트 이름별로 구성되어 있습니다.
27.2.12. unified_job_template_table.csv¶
unified_job_template_table.csv 파일은 시스템의 작업 템플릿에 대한 정보를 제공합니다. 각 행에는 작업 템플릿에 대한 다음 필드가 포함되어 있습니다.
- id
작업 템플릿 ID
- name
작업 템플릿 이름
- polymorphic_ctype_id
템플릿 유형 ID
- model
템플릿의 polymorphic_ctype_id 이름. 예를 들어 〈project〉, 〈systemjobtemplate〉, 〈jobtemplate〉, 〈inventorysource〉, 〈workflowjobtemplate〉 등이 있습니다.
- created
템플릿이 생성된 시간
- modified
템플릿이 마지막으로 업데이트된 시간
- created_by_id
템플릿을 생성한 userid. 시스템에서 수행한 경우 비어 있습니다.
- modified_by_id
템플릿을 마지막으로 수정한 userid. 시스템에서 수행한 경우 비어 있습니다.
- current_job_id
템플릿에 대해 현재 실행 중인 작업 ID(있는 경우)
- last_job_id
마지막 작업 실행
- last_job_run
마지막 작업 실행 시간
- last_job_failed
last_job_id가 실패했는지 여부
- status
last_job_id 상태
- next_job_run
다음 스케줄링된 템플릿 실행(있는 경우)
- next_schedule_id
next_job_run의 스케줄 ID(있는 경우)
27.2.13. unified_jobs_table.csv¶
unified_jobs_table.csv 파일은 시스템에서 실행하는 작업에 대한 정보를 제공합니다. 각 행에는 작업에 대한 다음 필드가 포함되어 있습니다.
- id
작업 ID
- name
작업 이름(템플릿)
- polymorphic_ctype_id
작업 유형 ID
- model
작업의 polymorphic_ctype_id 이름. 예를 들어 〈job〉, 〈worfklow〉 등이 있습니다.
- organization_id
작업의 조직 ID
- organization_name
organization_id 이름
- created
작업 레코드가 생성된 시간
- started
작업 실행이 시작된 시간
- finished
작업이 완료된 시간
- elapsed
작업 경과 시간(초)
- unified_job_template_id
이 작업의 템플릿
- launch_type
《manual》, 《scheduled》, 《relaunched》, 《scm》, 《workflow》 또는 《dependnecy》 중 하나
- schedule_id
작업을 시작한 스케줄 ID(있는 경우)
- instance_group_id
작업을 실행한 인스턴스 그룹
- execution_node
작업을 실행한 노드(호스트 이름, UUID 아님)
- controller_node
격리된 작업으로 또는 컨테이너 그룹에서 실행된 경우 작업의 컨트롤러 노드
- cancel_flag
작업이 취소되었는지 여부
- status
작업 상태
- failed
작업이 실패했는지 여부
- job_explanation
제대로 실행되지 않은 작업에 대한 추가 세부 정보
27.2.14. workflow_job_template_node_table.csv¶
workflow_job_template_node_table.csv는 시스템의 워크플로우 작업 템플릿에 정의된 노드에 대한 정보를 제공합니다.
각 행에는 워크플로우 작업 템플릿 노드에 대한 다음 필드가 포함되어 있습니다.
- id
노드 ID
- created
노드가 생성된 시간
- modified
노드가 마지막으로 업데이트된 시간
- unified_job_template_id
이 노드에 대한 작업 템플릿, 프로젝트, 인벤토리 또는 기타 상위 리소스의 ID
- workflow_job_template_id
이 노드가 포함된 워크플로우 작업 템플릿
- inventory_id
이 노드에서 사용하는 인벤토리
- success_nodes
이 노드가 성공한 후 트리거되는 노드
- failure_nodes
이 노드가 실패한 후 트리거되는 노드
- always_nodes
이 노드가 완료된 후 항상 트리거되는 노드
- all_parents_must_converge
이 노드를 시작하기 위해 모든 상위 조건이 충족되어야 하는지 여부
27.2.15. workflow_job_node_table.csv¶
workflow_job_node_table.csv는 시스템에서 워크플로우의 일부로 실행된 작업에 대한 정보를 제공합니다.
각 행에는 워크플로우의 일부로 실행된 작업에 대한 다음 필드가 포함되어 있습니다.
- id
노드 ID
- created
노드 레코드가 생성된 시간
- modified
노드 레코드가 마지막으로 업데이트된 시간
- job_id
이 노드에 대한 작업 실행의 작업 ID
- unified_job_tempalte_id
이 작업 실행에 대한 작업 템플릿, 프로젝트, 인벤토리 또는 기타 상위 리소스의 ID
- workflow_job_id
이 작업 실행에 대한 상위 워크플로우 작업
- inventory_id
이 작업에서 사용하는 인벤토리
- success_nodes
이 노드가 성공한 후 트리거된 노드
- failure_nodes
이 노드가 실패한 후 트리거된 노드
- always_nodes
이 노드가 완료된 후 트리거된 노드
- do_not_run
시작 조건이 트리거되지 않아 워크플로우에서 실행되지 않은 노드
- all_parents_must_converge
이 노드를 시작하기 위해 모든 상위 조건이 충족되어야 했는지 여부
27.2.16. events_table.csv¶
events_table.csv 파일은 시스템의 모든 작업 실행에서 발생한 모든 작업 이벤트에 대한 정보를 제공합니다. 각 행에는 작업 이벤트에 대한 다음 필드가 포함되어 있습니다.
- id
이벤트 ID
- uuid
이벤트 UUID
- created
이벤트가 생성된 시간
- parent_uuid
이 이벤트의 상위 UUID(있는 경우)
- event
Ansible 이벤트 유형(예: runner_on_failed)
- task_action
이 이벤트와 연결된 모듈(있는 경우)(예: 〈command〉 또는 〈yum〉)
- failed
이벤트에서 《failed》가 반환되었는지 여부
- changed
이벤트에서 《changed》가 반환되었는지 여부
- playbook
이벤트와 연결된 플레이북
- play
플레이북의 플레이 이름
- task
플레이북의 작업 이름
- role
플레이북의 역할 이름
- job_id
이 이벤트가 발생한 작업 ID
- host_id
이 이벤트가 연결된 호스트 ID(있는 경우)
- host_name
이 이벤트가 연결된 호스트 이름(있는 경우)
- start
작업 시작 시간
- end
작업 종료 시간
- duration
작업 기간
- warnings
작업/모듈의 경고
- deprecations
작업/모듈의 중단 경고