30. Tower Tips and Tricks¶
30.1. Using the Tower CLI Tool¶
Ansible Tower has a full-featured command line interface. Refer to AWX CLI Ansible Tower documentation for configuration and usage instructions.
30.2. Changing the Tower Admin Password¶
During the installation process, you are prompted to enter an administrator password which is used for the admin superuser/first user created in Tower. If you log into the instance via SSH, it will tell you the default admin password in the prompt. If you need to change this password at any point, run the following command as root on the Tower server:
awx-manage changepassword admin
Next, enter a new password. After that, the password you have entered will work as the admin password in the web UI.
To set policies at creation time for password validation using Django, see Django password policies for detail.
30.3. Creating a Tower Admin from the commandline¶
Once in a while you may find it helpful to create an admin (superuser) account from the commandline. To create an admin, run the following command as root on the Tower server and enter in the admin information as prompted:
awx-manage createsuperuser
30.4. Setting up a jump host to use with Tower¶
Credentials supplied by Tower will not flow to the jump host via ProxyCommand. They are only used for the end-node once the tunneled connection is set up.
To make this work, configure a fixed user/keyfile in the AWX user’s SSH config in the ProxyCommand definition that sets up the connection through the jump host. For example:
Host tampa
Hostname 10.100.100.11
IdentityFile [privatekeyfile]
Host 10.100..
Proxycommand ssh -W [jumphostuser]@%h:%p tampa
Note
You must disable PRoot by default if you need to use a jump host. You can disable PRoot through the Configure Tower user interface by setting the Enable Job Isolation toggle to OFF from the Jobs tab:
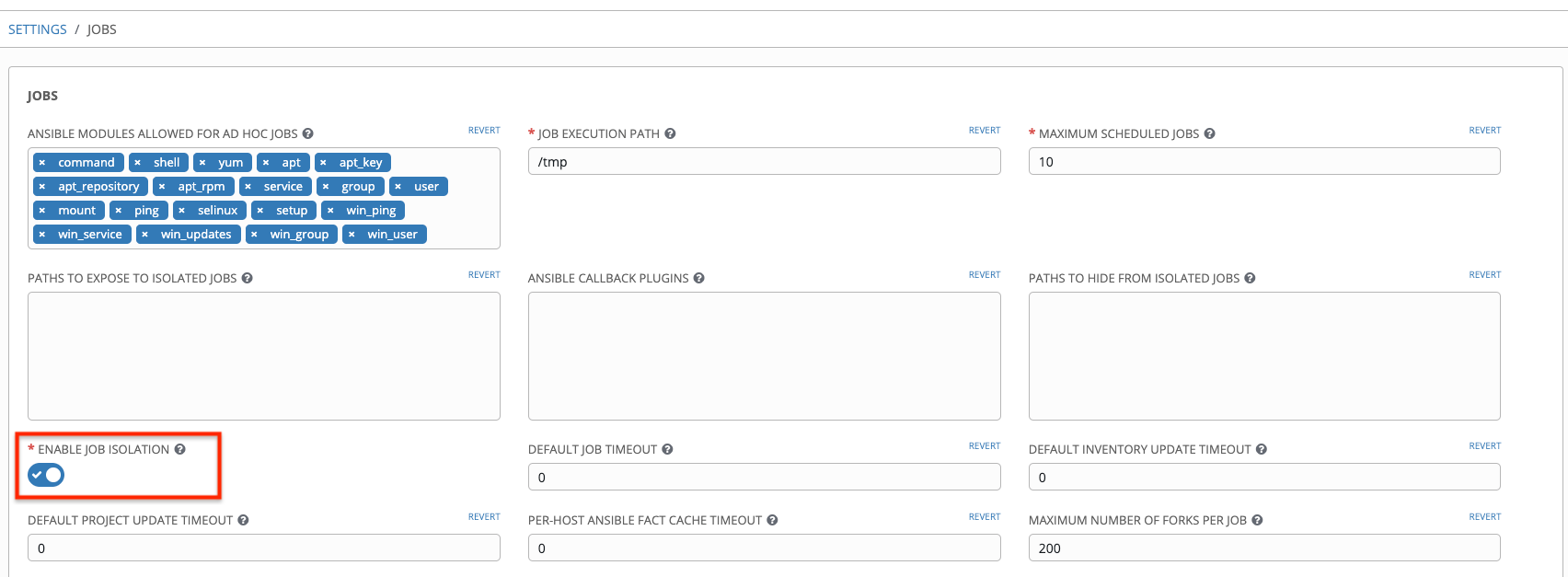
You can also add a jump host to your Tower instance through Inventory variables. These variables can be set at either the inventory, group, or host level. To add this, navigate to your inventory and in the variables field of whichever level you choose, add the following variables:
ansible_user: <user_name>
ansible_connection: ssh
ansible_ssh_common_args: '-o ProxyCommand="ssh -W %h:%p -q <user_name>@<jump_server_name>"'
30.5. View Ansible outputs for JSON commands when using Tower¶
When working with Ansible Tower, you can use the API to obtain the Ansible outputs for commands in JSON format.
To view the Ansible outputs, browse to:
https://<tower server name>/api/v2/jobs/<job_id>/job_events/
30.6. Locate and configure the Ansible configuration file¶
While Ansible does not require a configuration file, OS packages often include a default one in /etc/ansible/ansible.cfg for possible customization. In order to use a custom ansible.cfg file, place it at the root of your project. Ansible Tower runs ansible-playbook from the root of the project directory, where it will then find the custom ansible.cfg file. An ansible.cfg anywhere else in the project will be ignored.
To learn which values you can use in this file, refer to the configuration file on github.
Using the defaults are acceptable for starting out, but know that you can configure the default module path or connection type here, as well as other things.
Tower overrides some ansible.cfg options. For example, Tower stores the SSH ControlMaster sockets, the SSH agent socket, and any other per-job run items in a per-job temporary directory, secured by multi-tenancy access control restrictions via PRoot.
30.7. View a listing of all ansible_ variables¶
Ansible by default gathers “facts” about the machines under its management, accessible in Playbooks and in templates. To view all facts available about a machine, run the setup module as an ad hoc action:
ansible -m setup hostname
This prints out a dictionary of all facts available for that particular host. For more information, refer to: https://docs.ansible.com/ansible/playbooks_variables.html#information-discovered-from-systems-facts
30.8. The ALLOW_JINJA_IN_EXTRA_VARS variable¶
Setting ALLOW_JINJA_IN_EXTRA_VARS = template only works for saved job template extra variables. Prompted variables and survey variables are excluded from the ‘template’. This parameter has three values: template to allow usage of Jinja saved directly on a job template definition (the default), never to disable all Jinja usage (recommended), and always to always allow Jinja (strongly discouraged, but an option for prior compatibility).
30.9. Using virtualenv with Ansible Tower¶
Virtualenv creates isolated Python environments to avoid problems caused by conflicting dependencies and differing versions. Virtualenv works by simply creating a folder which contains all of the necessary executables and dependencies for a specific version of Python. Ansible Tower creates two virtualenvs during installation–one is used to run Tower, while the other is used to run Ansible. This allows Tower to run in a stable environment, while allowing you to add or update modules to your Ansible Python environment as necessary to run your playbooks. For more information on virtualenv, see the Python Guide to Virtual Environments and the Python virtualenv project itself.
By default, the virtualenv is located at /var/lib/awx/venv/ansible on the file system but you can create your own custom directories and use them in inventory imports. This allows you to choose how you run your inventory imports, as inventory sources use custom virtual environments.
Tower also pre-installs a variety of third-party library/SDK support into this virtualenv for its integration points with a variety of cloud providers (such as EC2, OpenStack, Azure, etc.) Periodically, you may want to add additional SDK support into this virtualenv, which is described in further detail below.
Note
It is highly recommended that you run umask 0022 before installing any packages to the virtual environment. Failure to properly configure permissions can result in Tower service failures. An example follows:
# source /var/lib/awx/venv/ansible/bin/activate
# umask 0022
# pip install --upgrade pywinrm
# deactivate
In addition to adding modules to the virtualenv that Tower uses to run Ansible, you can create new virtualenvs as described below.
30.9.1. Preparing a new custom virtualenv¶
You can specify a different virtualenv for running Job Templates in Tower. In order to do so, you must specify which directories those venvs reside. You could choose to keep custom venvs inside /var/lib/awx/venv/, but it is highly recommended that a custom directory be created. The following examples use a placeholder directory /opt/my-envs/, but you can replace this with a directory path of your choice anywhere this is specified.
Preparing a new custom virtualenv requires the virtualenv package to be pre-installed:
$ sudo yum install python-virtualenv
Create a directory for your custom venvs:
$ sudo mkdir /opt/my-envs
Make sure to give your directory the appropriate write permission, execution permission and ownership:
$ sudo chmod 0755 /opt/my-envs
$ sudo chown awx:awx /opt/my-envs
Optionally, you can specify in Tower which directory to look for custom venvs by adding this directory to the
CUSTOM_VENV_PATHSsetting as follows:
$ curl -X PATCH 'https://user:password@tower.example.org/api/v2/settings/system/' \
-d '{"CUSTOM_VENV_PATHS": ["/opt/my-envs/"]}' -H 'Content-Type:application/json'
If you have venvs spanned over multiple directories, add all the paths and Tower will aggregate venvs from them:
$ curl -X PATCH 'https://user:password@tower.example.org/api/v2/settings/system/' \
-d '{"CUSTOM_VENV_PATHS": ["/path/1/to/venv/", "/path/2/to/venv/", "/path/3/to/venv/"]}' \
-H 'Content-Type:application/json'
Now that a venv directory has been set up, create a virtual environment in that location:
$ sudo virtualenv /opt/my-envs/custom-venv
Note
Multiple versions of Python are supported, but the syntax for creating virtualenvs in Python 3 has changed slightly: $ sudo python3 -m venv /opt/my-envs/custom-venv
Next, install gcc so that
psutilcan be compiled:
$ yum install gcc
Python header files are needed to compile
psutil. The package needed to successfully compile psutil on RHEL 8 systems isplatform-python-devel:
$ yum install platform-python-devel
Your newly created virtualenv needs a few base dependencies to properly run playbooks (eg., fact gathering):
$ sudo /opt/my-envs/custom-venv/bin/pip install psutil
From here, you can install additional Python dependencies that you care about, such as a per-virtualenv version of Ansible itself:
$ sudo /opt/my-envs/custom-venv/bin/pip install -U "ansible == X.Y.Z"
Or you can add an additional third-party SDK that is not included with the base Tower installation:
$ sudo /opt/my-envs/custom-venv/bin/pip install -U python-digitalocean
If you want to copy them, the libraries included in Tower’s default virtualenv can be found using pip freeze:
$ sudo /var/lib/awx/venv/ansible/bin/pip freeze
In a clustered Tower installation, you need to ensure that the same custom virtualenv exists on every local file system at /opt/my-envs/. Custom virtualenvs are supported on isolated instances. If you are using a custom virtual environment, it needs to also be copied or replicated on any isolated node you would be using, not just on the Tower node. For setting up custom virtual environments in containers, refer to the OpenShift Deployment and Configuration section of the Ansible Tower Administration Guide.
30.9.2. Assigning custom virtualenvs¶
Once you have created a custom virtualenv, you can assign it at the Organization, Project, or Job Template level to use it in job runs. You can set the custom venv on an inventory source to run inventory updates in that venv. Jobs using that inventory follow their own rules and will not use this venv. If an SCM inventory source does not have a venv selected, it can use the venv of its linked project. You can assign a custom venv on the organization, but if you do, it will not be used by inventory updates in the organization, as it is only used in job runs.
The following shows the proper way to assign a custom venv at the desired level.
PATCH https://awx-host.example.org/api/v2/organizations/N/
PATCH https://awx-host.example.org/api/v2/projects/N/
PATCH https://awx-host.example.org/api/v2/job_templates/N/
PATCH https://awx-host.example.org/api/v2/inventory_sources/N/
Content-Type: application/json
{
'custom_virtualenv': '/opt/my-envs/custom-venv'
}
An HTTP GET request to /api/v2/config/ provides a list of detected installed virtualenvs:
{
"custom_virtualenvs": [
"/opt/my-envs/custom-venv",
"/opt/my-envs/my-other-custom-venv",
],
...
}
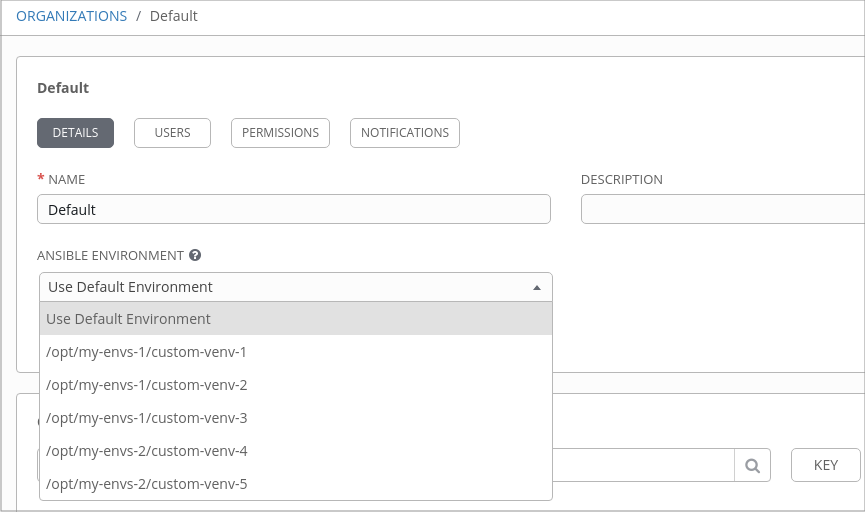
You can also specify the virtual environment to assign to an Organization, Project, and Job Template from their respective edit screens in the Ansible Tower User Interface. Select the virtualenv from the Ansible Environment drop-down menu, as shown in the example below:
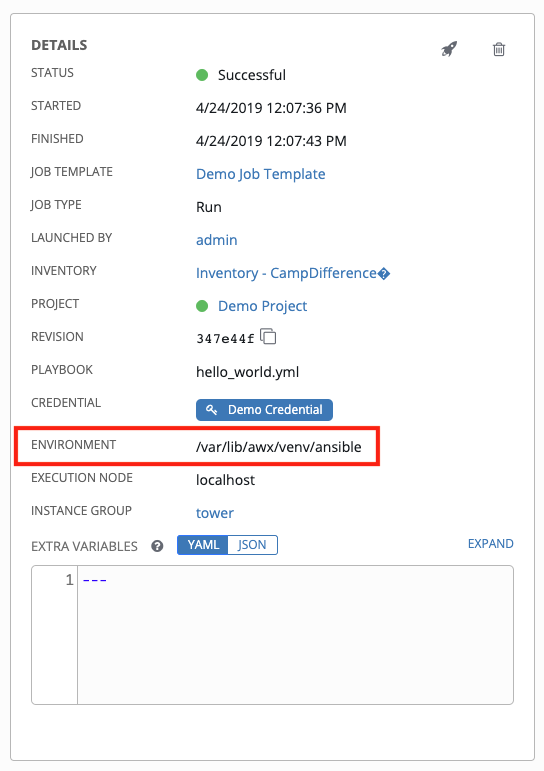
When you launch a job template, you will also see the virtualenv specified in the Job Details pane:
30.10. Configuring the towerhost hostname for notifications¶
In the System Settings, you can replace https://tower.example.com in the Base URL of The Tower Host field with your preferred hostname to change the notification hostname.

Refreshing your Tower license also changes the notification hostname. New installations of Ansible Tower should not have to set the hostname for notifications.
30.11. Launching Jobs with curl¶
Launching jobs with the Tower API is simple. Here are some easy to follow examples using the curl tool.
Assuming that your Job Template ID is ‘1’, your Tower IP is 192.168.42.100, and that admin and awxsecret are valid login credentials, you can create a new job this way:
curl -f -k -H 'Content-Type: application/json' -XPOST \
--user admin:awxsecret \
http://192.168.42.100/api/v2/job_templates/1/launch/
This returns a JSON object that you can parse and use to extract the ‘id’ field, which is the ID of the newly created job.
You can also pass extra variables to the Job Template call, such as is shown in the following example:
curl -f -k -H 'Content-Type: application/json' -XPOST \
-d '{"extra_vars": "{\"foo\": \"bar\"}"}' \
--user admin:awxsecret http://192.168.42.100/api/v2/job_templates/1/launch/
You can view the live API documentation by logging into http://192.168.42.100/api/ and browsing around to the various objects available.
Note
The extra_vars parameter needs to be a string which contains JSON, not just a JSON dictionary, as you might expect. Use caution when escaping the quotes, etc.
30.12. Dynamic Inventory and private IP addresses¶
By default, Tower only shows instances in a VPC that have an Elastic IP (EIP) address associated with them. To view all of your VPC instances, perform the following steps:
In the Tower interface, select your inventory.
Click on the group that has the Source set to AWS, and click on the Source tab.
In the “Source Variables” box, enter:
vpc_destination_variable: private_ip_address
Save and trigger an update of the group. You should now be able to see all of your VPC instances.
Note
Tower must be running inside the VPC with access to those instances in order to usefully configure them.
30.13. Filtering instances returned by the dynamic inventory sources in Tower¶
By default, the dynamic inventory sources in Tower (AWS, Google, etc) return all instances available to the cloud credentials being used. They are automatically joined into groups based on various attributes. For example, AWS instances are grouped by region, by tag name and value, by security groups, etc. To target specific instances in your environment, write your playbooks so that they target the generated group names. For example:
---
- hosts: tag_Name_webserver
tasks:
...
You can also use the Limit field in the Job Template settings to limit a playbook run to a certain group, groups, hosts, or a combination thereof. The syntax is the same as the --limit parameter on the ansible-playbook command line.
You may also create your own groups by copying the auto-generated groups into your custom groups. Make sure that the Overwrite option is disabled on your dynamic inventory source, otherwise subsequent synchronization operations will delete and replace your custom groups.
30.14. Using an unreleased module from Ansible source with Tower¶
If there is a feature that is available in the latest Ansible core branch that you would like to leverage with your Tower system, making use of it in Tower is fairly simple.
First, determine which is the updated module you want to use from the available Ansible Core Modules or Ansible Extra Modules GitHub repositories.
Next, create a new directory, at the same directory level of your Ansible source playbooks, named /library.
Once this is created, copy the module you want to use and drop it into the /library directory–it will be consumed first over your system modules and can be removed once you have updated the the stable version via your normal package manager.
30.15. Using callback plugins with Tower¶
Ansible has a flexible method of handling actions during playbook runs, called callback plugins. You can use these plugins with Tower to do things like notify services upon playbook runs or failures, send emails after every playbook run, etc. For official documentation on the callback plugin architecture, refer to: http://docs.ansible.com/developing_plugins.html#callbacks
Note
Ansible Tower does not support the stdout callback plugin because Ansible only allows one, and it is already being used by Ansible Tower for streaming event data.
You may also want to review some example plugins, which should be modified for site-specific purposes, such as those available at: https://github.com/ansible/ansible/tree/devel/lib/ansible/plugins/callback
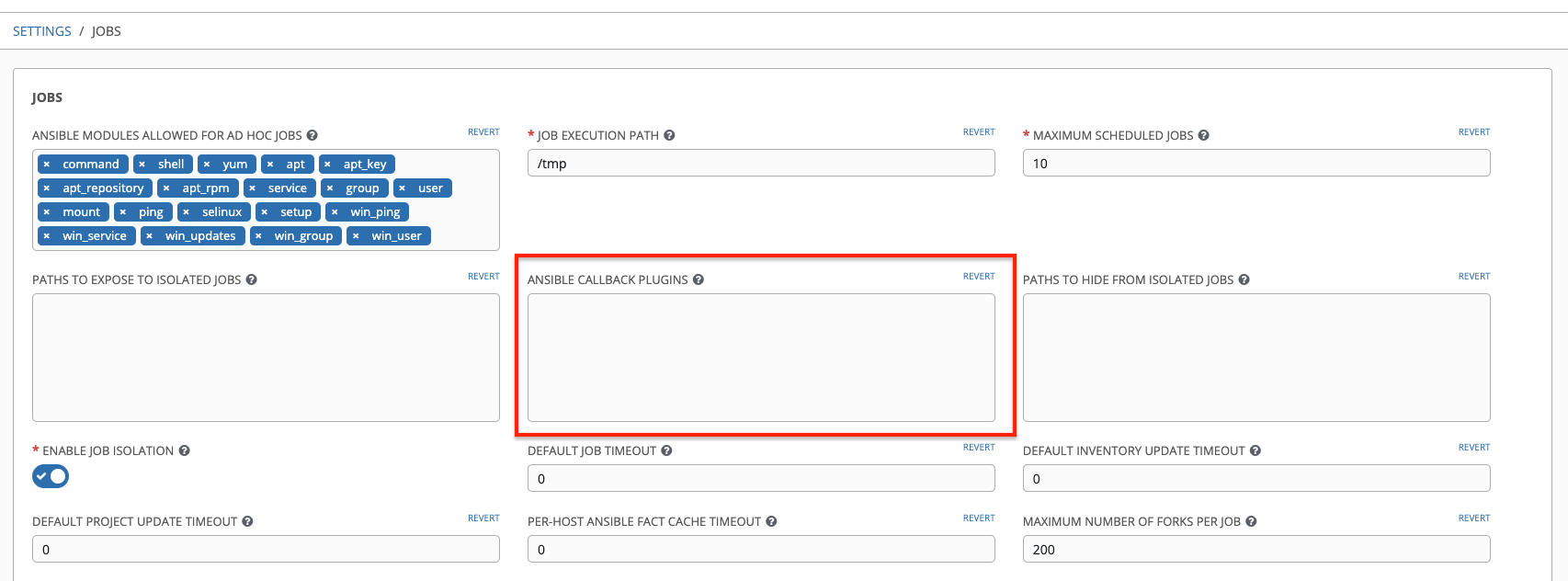
To use these plugins, put the callback plugin .py file into a directory called /callback_plugins alongside your playbook in your Tower Project. Then, specify their paths (one path per line) in the Ansible Callback Plugins field of the Configure Tower Job settings screen:
Note
To have most callbacks shipped with Ansible applied globally, you must add them to the callback_whitelist section of your ansible.cfg. If you have a custom callbacks, refer to the Ansible documentation for Enabling callback plugins.
30.16. Connecting to Windows with winrm¶
By default Tower attempts to ssh to hosts. You must add the winrm connection info to the group variables to which the Windows hosts belong. To get started, edit the Windows group in which the hosts reside and place the variables in the source/edit screen for the group.
To add winrm connection info:
Edit the properties for the selected group by clicking on the  button to the right of the group name that contains the Windows servers. In the “variables” section, add your connection information as such:
button to the right of the group name that contains the Windows servers. In the “variables” section, add your connection information as such: ansible_connection: winrm
Once done, save your edits. If Ansible was previously attempting an SSH connection and failed, you should re-run the job template.
30.17. Importing existing inventory files and host/group vars into Tower¶
To import an existing static inventory and the accompanying host and group vars into Tower, your inventory should be in a structure that looks similar to the following:
inventory/
|-- group_vars
| `-- mygroup
|-- host_vars
| `-- myhost
`-- hosts
To import these hosts and vars, run the awx-manage command:
awx-manage inventory_import --source=inventory/ \
--inventory-name="My Tower Inventory"
If you only have a single flat file of inventory, a file called ansible-hosts, for example, import it like the following:
awx-manage inventory_import --source=./ansible-hosts \
--inventory-name="My Tower Inventory"
In case of conflicts or to overwrite an inventory named “My Tower Inventory”, run:
awx-manage inventory_import --source=inventory/ \
--inventory-name="My Tower Inventory" \
--overwrite --overwrite-vars
If you receive an error, such as:
ValueError: need more than 1 value to unpack
Create a directory to hold the hosts file, as well as the group_vars:
mkdir -p inventory-directory/group_vars
Then, for each of the groups that have :vars listed, create a file called inventory-directory/group_vars/<groupname> and format the variables in YAML format.
Once broken out, the importer will handle the conversion correctly.