7. 클러스터링¶
클러스터링은 호스트 간에 부하를 공유하는 것입니다. 각 인스턴스가 UI 및 API 액세스를 위한 진입점 역할을 할 수 있어야 합니다. 이렇게 하면 컨트롤러 관리자가 원하는 만큼 많은 인스턴스 앞에 로드 밸런서를 사용하고 적절한 데이터 가시성을 유지할 수 있습니다.
참고
부하 분산은 선택 사항이며, 필요에 따라 하나 또는 모든 인스턴스에 들어올 수 있습니다.
각 인스턴스가 컨트롤러 클러스터에 참여하여 작업 실행 능력을 확장할 수 있어야 합니다. 작업이 실행 위치로 전송되는 대신, 어디에서나 실행될 수 있고 실행되는 간단한 시스템입니다. 또한 클러스터형 인스턴스를 :ref:`ag_instance_groups`라는 다양한 풀/큐로 그룹화할 수 있습니다.
|aap|에서는 Kubernetes를 사용하는 컨테이너 기반 클러스터를 지원하므로 기능상의 변형이나 전환 없이도 이 플랫폼에 새 컨트롤러 인스턴스를 설치할 수 있습니다. Kubernetes 컨테이너를 가리키는 인스턴스 그룹을 생성할 수 있습니다. 자세한 내용은 컨테이너 및 인스턴스 그룹 섹션을 참조하십시오.
지원되는 운영 체제
클러스터형 환경 설정이 지원되는 운영 체제는 다음과 같습니다.
Red Hat Enterprise Linux 7 이상(RHEL8 권장, RHEL 7 또는 Centos 7 인스턴스 중 하나일 수 있음)
참고
OpenShift에서 |at|를 실행하는 경우 격리된 인스턴스는 지원되지 않습니다.
7.1. 설정 고려 사항¶
이 섹션에서는 클러스터의 초기 설정에 대해서만 설명합니다. 기존 클러스터를 업그레이드하는 경우 |atumg|의 :ref:`Upgrade Planning <upgrade-migration-guide:upgrade_planning>`을 참조하십시오.
새로운 클러스터링 환경에서 주목해야 할 중요한 고려 사항은 다음과 같습니다.
PostgreSQL은 여전히 독립 실행형 인스턴스이며 클러스터형이 아닙니다. 컨트롤러는 복제본 구성 또는 데이터베이스 장애 조치를 관리하지 않습니다(사용자가 대기 복제본을 구성하는 경우).
클러스터를 실행할 때 데이터베이스 노드는 독립 실행형 서버여야 하며, 컨트롤러 노드 중 하나에 PostgreSQL을 설치하지 않아야 합니다.
한 클러스터에 지원되는 최대 인스턴스 수는 20개입니다.
모든 인스턴스가 다른 모든 인스턴스에서 연결 가능해야 하며, 데이터베이스에 연결할 수 있어야 합니다. 또한 호스트가 안정적인 주소 및/또는 호스트 이름을 갖는 것이 중요합니다(컨트롤러 호스트 구성 방법에 따라 다름).
모든 인스턴스가 동일한 지역에 배치되어야 하며, 인스턴스 간에 대기 시간이 짧고 안정적인 연결이 있어야 합니다.
클러스터형 환경으로 업그레이드하려면 기본 인스턴스가 인벤토리의
default그룹에 속해야 합니다. 또한default그룹에 나열된 첫 번째 호스트여야 합니다.수동 프로젝트는 고객이 모든 인스턴스에 수동으로 동기화해야 하며, 한 번에 모든 인스턴스에서 업데이트해야 합니다.
플랫폼 배포를 위한
inventory파일을 저장/유지해야 합니다. 새 인스턴스를 프로비저닝해야 하는 경우 설치 프로그램이 암호 및 구성 옵션과 호스트 이름을 사용할 수 있어야 합니다.
7.2. 설치 및 구성¶
새 인스턴스를 프로비저닝하려면 inventory 파일을 업데이트하고 설정 플레이북을 다시 실행해야 합니다. 클러스터 또는 다른 인스턴스를 설치할 때 사용되는 모든 암호와 정보가 포함된 inventory 파일을 재구성할 수 있다는 것이 중요합니다. inventory 파일 인벤토리에는 ``automationcontroller``라는 단일 인벤토리 그룹이 포함되어 있습니다.
참고
모든 인스턴스가 작업 스케줄링과 관련된 다양한 하우스키핑 작업(예: 작업 시작 위치 확인, 플레이북 이벤트 처리, 주기적 정리)을 담당합니다.
[automationcontroller]
hostA
hostB
hostC
[instance_group_east]
hostB
hostC
[instance_group_west]
hostC
hostD
참고
리소스에 대해 선택한 그룹이 없으면 automationcontroller 그룹이 사용되지만, 다른 그룹을 선택하면 automationcontroller 그룹은 어떤 방식으로도 사용되지 않습니다.
database 그룹은 외부 PostgreSQL을 지정하기 위해 남아 있습니다. 데이터베이스 호스트가 별도로 프로비저닝된 경우 이 그룹은 비어 있어야 합니다.
[automationcontroller]
hostA
hostB
hostC
[database]
hostDB
플레이북이 클러스터의 개별 컨트롤러 인스턴스에서 실행되는 경우 해당 플레이북의 출력이 컨트롤러의 websocket 기반 스트리밍 출력 기능의 일부로 다른 모든 노드에 브로드캐스트됩니다. 인벤토리의 각 노드에 대해 라우팅 가능한 개인 주소를 지정하여 내부 주소 지정을 통해 이 데이터 브로드캐스트를 처리하는 것이 가장 좋습니다.
[automationcontroller] hostA routable_hostname=10.1.0.2 hostB routable_hostname=10.1.0.3 hostC routable_hostname=10.1.0.4
참고
이전 automation controller 버전에서는 rabbitmq_host``라는 변수 이름을 사용했습니다. 이전 버전의 플랫폼에서 업그레이드하는 중이며 이전에 인벤토리에서 ``rabbitmq_host``를 지정한 경우 업그레이드하기 전에 ``rabbitmq_host 이름을 ``routable_hostname``으로 변경하기만 하면 됩니다.
7.3. 상태 및 브라우저 API를 통한 모니터링¶
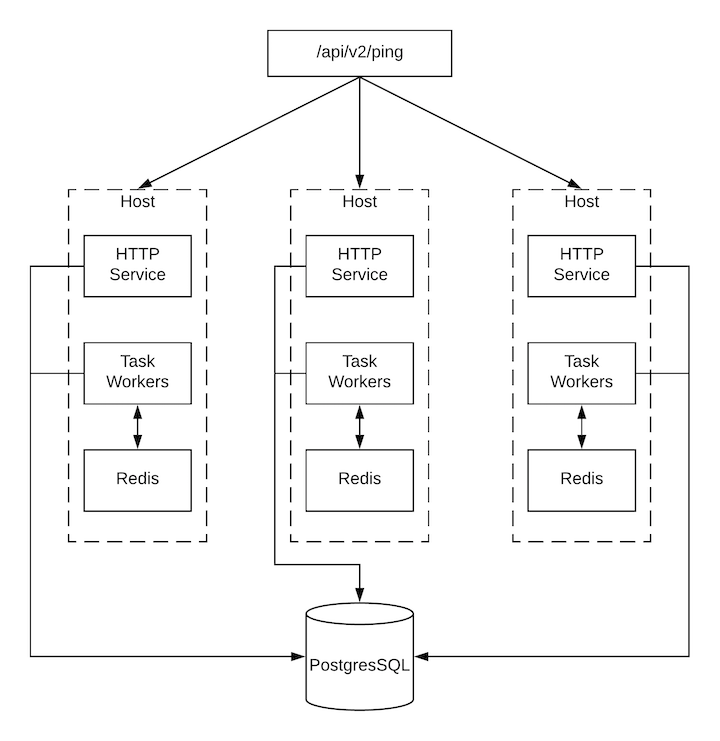
컨트롤러는 다음을 비롯한 클러스터의 상태 검증을 위해 ``/api/v2/ping``에서 검색 가능 API를 통해 가능한 만큼 많은 상태를 자체적으로 보고합니다.
HTTP 요청을 처리하는 인스턴스
클러스터에 있는 다른 모든 인스턴스의 마지막 하트비트 타임스탬프
인스턴스 그룹 및 해당 그룹의 인스턴스 멤버십
실행 중인 작업과 멤버십 정보를 포함하여 인스턴스 및 인스턴스 그룹에 대한 자세한 내용은 /api/v2/instances/ 및 ``/api/v2/instance_groups/``에서 살펴보십시오.
7.4. 인스턴스 서비스 및 실패 동작¶
각 컨트롤러 인스턴스는 공동으로 작업하는 여러 서비스로 이루어져 있습니다.
HTTP 서비스 - 컨트롤러 애플리케이션 자체와 외부 웹 서비스가 포함됩니다.
콜백 수신기 - 실행 중인 Ansible 작업에서 작업 이벤트를 수신합니다.
디스패처 - 모든 작업을 처리하고 실행하는 작업자 큐입니다.
Redis - 이 키 값 저장소는 ansible-playbook에서 애플리케이션으로 전파되는 이벤트 데이터의 큐로 사용됩니다.
rsyslog - 다양한 외부 로깅 서비스에 로그를 전달하는 데 사용되는 로그 처리 서비스입니다.
컨트롤러는 이러한 서비스 또는 구성 요소 중 하나라도 실패할 경우 모든 서비스가 다시 시작되는 방식으로 구성되어 있습니다. 짧은 시간에 충분히 자주 실패할 경우 예기치 않은 동작을 유발하지 않고 수정할 수 있도록 전체 인스턴스가 자동화된 방식으로 오프라인 상태로 전환됩니다.
클러스터형 환경 백업 및 복원은 클러스터형 환경의 백업 및 복원 섹션을 참조하십시오.
7.5. 작업 런타임 동작¶
작업이 실행되고 컨트롤러의 〈일반〉 사용자에게 보고되는 방식은 변경되지 않습니다. 시스템 측면에서는 다음과 같은 몇 가지 차이점이 있습니다.
API 인터페이스에서 작업이 제출되면 디스패처 큐로 푸시됩니다. 각 컨트롤러 인스턴스는 특정 스케줄링 알고리즘을 사용하여 해당 큐에 연결하고 작업을 수신합니다. 클러스터의 모든 인스턴스가 동일하게 작업을 수신하고 실행할 가능성이 있습니다. 작업을 실행하는 동안 인스턴스가 실패할 경우 해당 작업은 영구적으로 실패한 것으로 표시됩니다.
작업을 실행할 수 있는 모든 인스턴스에서 프로젝트 업데이트가 성공적으로 실행됩니다. 프로젝트는 작업을 실행하기 직전에 인스턴스의 올바른 버전에 자신을 동기화합니다. 필요한 버전이 이미 로컬에서 검사되었으며 Galaxy 또는 Collections 업데이트가 필요하지 않은 경우에는 동기화가 수행되지 않을 수도 있습니다.
동기화가 발생하면
launch_type = sync및 ``job_type = run``을 사용하여 프로젝트 업데이트로 데이터베이스에 기록됩니다. 프로젝트 동기화는 프로젝트의 상태 또는 버전을 변경하지 않습니다. 대신, 동기화가 실행되는 인스턴스의 소스 트리*만* 업데이트합니다.Galaxy 또는 Collections의 업데이트가 필요한 경우 필수 역할을 다운로드하는 동기화가 수행되며, /tmp 파일의 더 많은 공간이 사용됩니다. 큰 프로젝트(약 10GB)가 있는 경우 ``/tmp``의 디스크 공간이 문제가 될 수 있습니다.
7.5.1. 작업 실행¶
기본적으로 작업이 컨트롤러 큐에 제출되면 작업자 중 하나가 선택할 수 있습니다. 그러나 작업이 실행되는 인스턴스 제한과 같이 특정 작업이 실행되는 위치를 제어할 수 있습니다.
임시로 인스턴스를 오프라인 상태로 전환할 수 있도록 각 인스턴스에 활성화된 속성이 정의되어 있습니다. 이 속성을 비활성화하면 해당 인스턴스에는 작업이 할당되지 않습니다. 기존 작업은 완료되지만 새 작업이 할당되지 않습니다.
7.6. 인스턴스 프로비저닝 해제¶
현재 클러스터는 의도적으로 또는 오류로 인해 오프라인 상태로 전환된 인스턴스를 구분하지 않으므로 설정 플레이북을 다시 실행해도 인스턴스 프로비저닝이 자동으로 해제되지는 않습니다. 대신 컨트롤러 인스턴스에서 모든 서비스를 종료한 다음, 다른 인스턴스에서 프로비저닝 해제 툴을 실행합니다.
automation-controller-service stop명령을 사용하여 인스턴스를 종료하거나 서비스를 중지합니다.다른 인스턴스에서 프로비저닝 해제 명령 ``$ awx-manage deprovision_instance –hostname=<name used in inventory file>``을 실행하여 컨트롤러 클러스터에서 제거합니다.
예:
awx-manage deprovision_instance --hostname=hostB
마찬가지로, 컨트롤러에서 인스턴스 그룹 프로비저닝을 해제해도 인스턴스 그룹이 자동으로 프로비저닝 해제되거나 제거되지는 않습니다. 자세한 내용은 인스턴스 그룹 프로비저닝 해제 섹션을 참조하십시오.