6. クラスタリング¶
Ansible Tower 3.1 では、冗長化の代わりのアプローチとしてクラスタリングが導入され、プライマリーインスタンスとセカンダリーインスタンスを使用する active-passive ノードで設定されていた冗長化ソリューションの後継となります。3.1 より前のバージョンは、以前のバージョンの Ansible Tower Administration Guide のクラスタリングの章を参照してください。
クラスタリングでは、ホスト間で負荷が共有されます。各インスタンスは、UI および API アクセスのエントリーポイントとして機能します。これにより、Tower の管理者が複数のインスタンスの手前でロードバランサーを使用できるようになり、データの可視性が向上されるはずです。
注釈
負荷分散はオプションで、必要に応じて 1 つまたはすべてのインスタンスで受信することも可能です。
各インスタンスは、Tower のクラスターに参加して、ジョブの実行機能を拡張することができます。これは、ジョブの実行場所を指定するのではなく、ジョブをどこでも実行できる簡単なシステムです。Ansible Tower 3.2 では、クラスターインスタンスを異なるプール/キューにグループ化する機能が導入されました。
インスタンスは、1 つまたは複数のインスタンスグループにグループ化することができます。インスタンスグループは、以下に記載のリソース 1 つまたは複数に割り当てることができます。
- 組織
- インベントリー
- ジョブテンプレート
リソースの 1 つに関連付けられているジョブが実行されると、そのリソースに関連付けられているインスタンスグループに割り当てられます。実行プロセス中に、インベントリーに関連付けられたインスタンスグループではなく、ジョブテンプレートに関連付けられたインスタンスグループが先に確認されます。同様に、インベントリーに関連付けられているインスタンスグループは、組織に関連付けられているインスタンスグループよりも先に確認されます。そのため、3 つのリソースのインスタンスグループの割り当てには、Job Template > Inventory > Organization の階層が形成されます。
サポート対象のオペレーティングシステム
クラスター環境の確立には、以下のオペレーティングシステムがサポートされます。
- RHEL-7 (RHEL-7 または Centos-7 のインスタンス)
- Ubuntu 16
- 今回のリリースでは、分離インスタンスは、RHEL-7 のみにインストールできます。
6.1. 設定の留意事項¶
新規クラスタリング環境における重要な留意事項:
- PostgreSQL はまだスタンドアロンのインスタンスで、クラスター化されていません。Tower はレプリカ設定やデータベースのフェイルオーバーを管理しません (ユーザーが待機レプリカを設定した場合)。
- クラスターのインスタンス数は常に奇数でなければならず、クラスター内には Tower インスタンスを最低でも 3 つ用意することを 強く推奨します。
- 全インスタンスは、他のすべてのインスタンスから到達でき、データベースにアクセスできる必要があります。ホストに安定したアドレスおよび/またはホスト名を指定することも重要です (Tower ホストの設定方法により異なる)。
- 全インスタンスは、インスタンス間でレイテンシーが低く信頼性のある接続で地理的に配置する必要があります。
- RabbitMQ は、Tower のクラスタリングシステムには不可欠です。設定要件や動作の多くは、それぞれのニーズにより決まるので、Tower の設定 Playbook に含まれないカスタマイズには制約があります。各 Tower インスタンスには、RabbitMQ のデプロイメントが含まれており、他のインスタンスの RabbitMQ インスタンスと合わせてクラスタリングされます。
- 既存の旧式の HA デプロイメントは、アップグレードプロセス中に、自動的に新しい HA システムに移行されます。
- クラスター環境にアップグレードするには、プライマリーのインスタンスがインベントリーの
towerグループに所属し、さらにtowerグループの最初のホストとしてリストされる必要があります。 - 手動のプロジェクトでは、顧客が手動で全インスタンスを同期して、一度に全インスタンスを更新する必要があります。
- 新しい Tower システムにはプライマリー/セカンダリーのコンセプトはありません。システムはすべてプライマリーです。
- 設定 Playbook は RabbitMQ を設定したり、ホストが使用するネットワークタイプを提供したり変化します。
- Tower デプロイメントの
inventoryファイルは保存/永続化する必要があります。新規インスタンスをプロビジョニングする場合は、パスワード、設定オプション、ホスト名をインストーラーで利用できるようにしなければなりません。 instance_group_towerという名前のグループは作成しないでください。- インスタンスにグループ名と同じ名前を指定しないでください。
6.2. インストールおよび設定¶
新規インスタンスのプロビジョニングは、inventory ファイルを更新して、設定 Playbook を再実行します。この inventory ファイルには、クラスターのインストール時に使用するすべてのパスワードと情報が含まれていることが重要です。含まれていない場合には、他のインスタンスが再設定される場合があります。現在のスタンドアロンのインスタンス設定は、3.1 以降のデプロイメントでは変更はありません。inventory ファイルには重要な変更が含まれています。
- プライマリー/セカンダリーの設定がないので、このようなインベントリーグループはなくなり、単一のインベントリーグループ
towerに置き換えられました。 - オプションで、これらのグループで他のグループやグループインスタンスを定義することができます。これらのグループには、
instance_group_のプレフィックスを指定する必要があります。インスタンスは、instance_group_グループ以外に Tower のグループに所属する必要はありませんが、towerグループには必ず 1 つインスタンスが存在している 必要があります。特定のグループが特定のリソースに関連付けられていない場合には、ジョブの実行は必ずtowerグループに戻ります。
tower グループのインスタンスは、ジョブの起動場所の決定や Playbook のイベントの処理などハウスキーピングタスクを行います。さらに、Tower インスタンスグループのメンバーに障害が発生すると、ジョブは実行できず、Playbook イベントが記述される可能性があります。そのため、ハウスキーピングタスクの処理だけでなく、障害時のバックアップとして機能できるように、tower グループに十分な数のクラスターインスタンスを設定することが重要です。
[tower]
hostA
hostB
hostC
[instance_group_east]
hostB
hostC
[instance_group_west]
hostC
hostD
注釈
リソースにグループが選択されていない場合には、tower グループが使用されますが、他のグループが選択されている場合は tower グループは使用されません。
database グループは、外部の Postgres を指定します。データベースホストが別にプロビジョニングされる場合には、このグループは空にしておく必要があります。
[tower]
hostA
hostB
hostC
[database]
hostDB
外部の Tower インスタンスをプロビジョニングにするのは一般的ですが、内部のアドレスで参照するのが最適です。これは、特に外部インターフェースでサービスが利用できない RabbitMQ クラスタリングにおいては最も重要です。そのため、RabittMQ に内部アドレスを割り当てる必要があります。
[tower]
hostA rabbitmq_host=10.1.0.2
hostB rabbitmq_host=10.1.0.3
hostC rabbitmq_host=10.1.0.3
注釈
クラスターのインスタンス数は常に奇数でなければならず、クラスター内には Tower インスタンスを最低でも 3 つ用意することを 強く推奨します。
redis_passwordフィールドは[all:vars]から削除されています。RabbitMQ のフィールドは以下のとおりです。
rabbitmq_port=5672: RabbitMQ は、各インスタンスにインストールされ、オプションではありません。またこれは外部に設定することはできません。この設定により、どのポートをリッスンするのかを指定します。rabbitmq_vhost=tower: Tower が RabbitMQ virtualhost を構成して分離するための設定を制御します。rabbitmq_username=towerおよびrabbitmq_password=tower: 各インスタンスおよびインスタンス毎の Tower インスタンスがこれらの値で設定されます。これは、Tower で他に使用するユーザー名/パスワードと似ています。rabbitmq_cookie=<somevalue>: この値は、スタンドアロンのデプロイメントでは使用されませんが、クラスターのデプロイメントには必要不可欠です。これは、RabbitMQ クラスターのメンバーがお互いを識別できるように、シークレットキーとして機能します。rabbitmq_use_long_names: RabbitMQ は、各インスタンスの名称に厳密に反応しますが、Tower は柔軟性が高く、FQDN (host01.example.com)、短い名前 (host01) または ip アドレス (192.168.5.73) に対応できます。インベントリーファイルで各ホストの特定に使用する方法によって、この値は変化する可能性があります。- FQDN および IP アドレスの場合は、この値は
trueです。 - 短い名前の場合は、値を
falseに設定します。 - localhost を使用する場合は、
rabbitmq_use_long_name=falseのデフォルト設定を true に変更しないでください。 - 外部のアドレスではなく、他のインスタンスの内部の参照先に、インスタンスがプロビジョニングされる場合には、長い名前の値は内部のアドレス形式に準拠する必要があります (前述の
rabbitmq_hostを参照)。
- FQDN および IP アドレスの場合は、この値は
rabbitmq_enable_manager: RabbitMQ 管理 Web コンソールを各インスタンスに公開するには、これを True に設定します。
6.2.1. RabbitMQ デフォルト設定¶
以下の設定は、RabbitMQ のデフォルト設定です。
rabbitmq_port=5672
rabbitmq_vhost=tower
rabbitmq_username=tower
rabbitmq_password=''
rabbitmq_cookie=cookiemonster
注釈
rabbitmq_cookie は機密の値です。Tower の secret key のように取り扱うようにしてください。
6.2.2. Tower が使用するインスタンスおよびポート¶
Tower が使用するポートとインスタンスは以下のとおりです。
- 80、443 (通常の Tower ポート)
- 22 (ssh)
- 5432 (データベースインスタンス: データベースが外部インスタンスにインストールされた場合は、Tower インスタンスに対してこのポートを開放する必要があります。)
クラスタリング/RabbitMQ ポート:
- 4369、25672 (クラスターの管理に RabbitMQ 専用で使用するポート。各インスタンス間でこのポートを開放する必要があります)
- 15672 (RabbitMQ 管理インターフェースが有効化されている場合には、このポートを開放する必要があります (任意))
6.3. 分離インスタンスグループ¶
Ansible Tower バージョン 3.2 以降では、オプションでセキュリティーの制限があるネットワークゾーン内に分離グループを定義して、そのゾーンからジョブやアドホックのコマンドを実行する機能が追加されました。これらのグループ内のインスタンスには、Tower のシステム環境は完全ではなく、ジョブ実行に使用するユーティリティーが最小限となっています。分離グループは、プレフィックスが isolated_group_ のインベントリーファイルに指定する必要があります。以下は、分離インスタンスグループのインベントリーファイルの例です。
[tower]
towerA
towerB
towerC
[instance_group_security]
towerB
towerC
[isolated_group_govcloud]
isolatedA
isolatedB
[isolated_group_govcloud:vars]
controller=security
分離グループモデルでは、「コントローラー」インスタンスは、SSH 経由で一連の Ansible Playbook を使用して「分離」インスタンスと対話します。インストール時には、デフォルトで RSA 鍵が無作為に作成され、認証キーとしてすべての「分離」インスタンスに配布されます。その鍵に対応する秘密鍵は暗号化され、Tower データベースに保存されます。この鍵はジョブの実行時に、「コントローラー」インスタンスから「分離」インスタンスへの認証を行う際に使用します。
ジョブが「分離」インスタンスで実行されるように予定されている場合:
- 「コントローラー」インスタンスは、ジョブの実行に必要なメタデータをコンパイルし、「分離」インスタンスにコピーします。
- メタデータが、分離ホストに同期されたら、「コントローラー」インスタンスは「分離」インスタンスでプロセスを開始し、メタデータを使って
ansible/ansible-playbookの実行を開始します。Playbook が実行されると、(標準出力やジョブインベントなど) ジョブのアーティファクトが「分離」インスタンスのディスクに書き込まれます。 - ジョブが「分離」インスタンスで実行されると、「コントローラー」インスタンスは「分離」インスタンスから定期的に (標準出力やジョブイベントなど) ジョブのアーティファクトをコピーし、「分離」インスタンスでジョブが完了するまで、ジョブのアーティファクトを使用します。
分離グループ (ノード) は、コントローラーグループに所属するインスタンスだけのアクセスを許可するセキュリティールールを持つ VPC の内部でのみ存在できるように作成されます。「コントローラー」インスタンスから「分離」インスタンスへの SSH 経由の受信トラフィックのみが必要です。分離ノードをプロビジョニングする場合は、インストールマシンは分離ノードに接続できる必要があります。分離ノードに直接アクセスできないが、他のホスト経由で間接的に到達できる場合には、SSH 設定で ProxyCommand を使用して「ジャンプホスト」を指定して、インストーラーを実行してください。
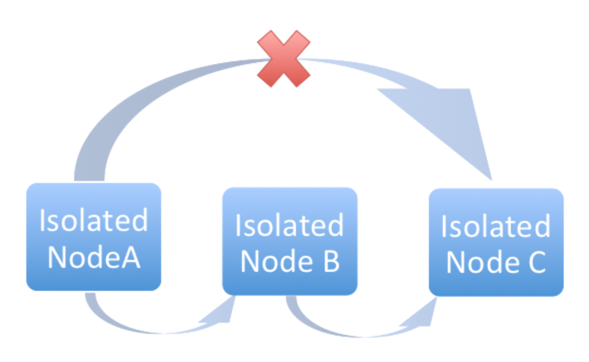
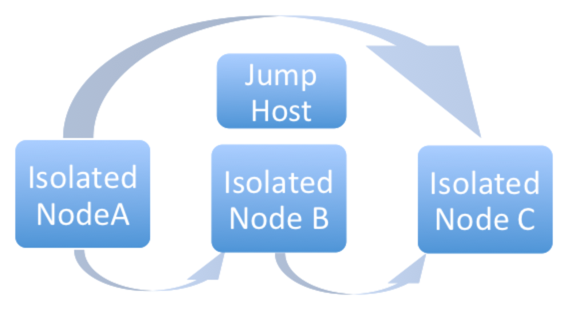
分離グループの推奨のシステム設定は以下のとおりです。
isolated_group_towerという名前のグループは作成しないでください。- Tower グループや他の一般的なインスタンスグループに分離インスタンスを配置しないでください。
- コントローラー変数を分離グループの全インスタンスのグループ変数またはホスト変数として定義します。この変数については、同じグループ内にある分離インスタンスに異なる値を割り当てられないようにしてください。割り当ててしまうと、予期せぬ動作が発生する可能性があります。
- 複数の分離グループに分離インスタンスを配置しないでください。
- 通常のグループや分離グループにはインスタンスを配置しないでください。
- 分離インスタンスでファクトのキャッシュを使用しないでください。
6.3.1. オプションの SSH 認証¶
(内部で管理するパスワードなしの SSH 鍵など) Tower 以外のシステムを介して、「コントローラー」ノードから「分離ノード」への SSH 認証を管理する場合、Tower のインストールに使用するインベントリーファイルでオフにすることで、この動作を無効にすることができます。
[tower]
towerA
towerB
towerC
[instance_group_security]
towerB
towerC
[isolated_group_govcloud]
isolatedA
isolatedB
[isolated_group_govcloud:vars]
controller=security
# Isolated Tower nodes automatically generate an RSA key for authentication;
# To disable this behavior, set this value to false
isolated_key_generation=false
6.4. ブラウザーの API を使用したステータスの確認およびモニタリング¶
Tower は、/api/v2/ping で、クラスターのヘルスを検証するために Browsable API を使用してステータスをできるだけレポートします。以下に例を示します。
- HTTP 要求にサービスを提供するインスタンス
- クラスター内にある他の全インスタンスが出した最後のハートビートのタイムスタンプ
- インスタンスグループすべての状態
- これらのグループのインスタンスグループおよびインスタンスのメンバーシップ
実行中のジョブやメンバー情報など、インスタンスおよびインスタンスグループに関する詳細情報は、/api/v2/instances/ および /api/v2/instance_groups/ を参照してください。
6.5. インスタンスサービスおよび障害時の動作¶
各 Tower インスタンスは、複数の異なるサービスで構成されており、これらのサービスは連携しています。
- HTTP サービス: これには、Tower アプリケーション自体と外部の Web サービスが含まれます。
- Callback Receiver: 実行中の Ansible ジョブからジョブイベントを受信します。
- Celery: 全ジョブを処理、実行するワーカーキュー
- RabbitMQ: このメッセージブローカーは、Celery のシグナルメカニズムおよびアプリケーションに伝搬するイベントデータとして使用されます。
- Memcached: サービスが配置されているインスタンスのローカルキャッシュサービス
サービスやコンポーネントに障害が発生すると、全サービスが再起動されるように Tower は構成されています。サービスやコンポーネントが短期間で何度も機能しなくなった場合には、予期せぬ動作を起こさずに修正できるように自動的に全インスタンスがオフラインに切り替えられます。
クラスター環境のバックアップおよび復元については、「クラスター環境のバックアップおよび復元」のセクションを参照してください。
6.6. ジョブランタイムの動作¶
ジョブの実行や、Tower の「通常」ユーザーへレポートする方法は変更されません。システム側には、注目すべき相違点が複数あります。
- ジョブが API インターフェースから送信されると、RabbitMQ の Celery キューにプッシュされます。単一の RabbitMQ インスタンスは個別キューをまとめるマスターとなり、各 Tower ノードは特定のスケジュールアルゴリズムを使用してキューに接続し、そのキューからジョブを受信します。クラスター内のいずれのインスタンスも、同じ確率でジョブを受信してタスクを実行します。ジョブの実行時にインスタンスが失敗すると、ジョブは永続的に「失敗」とマークされます。
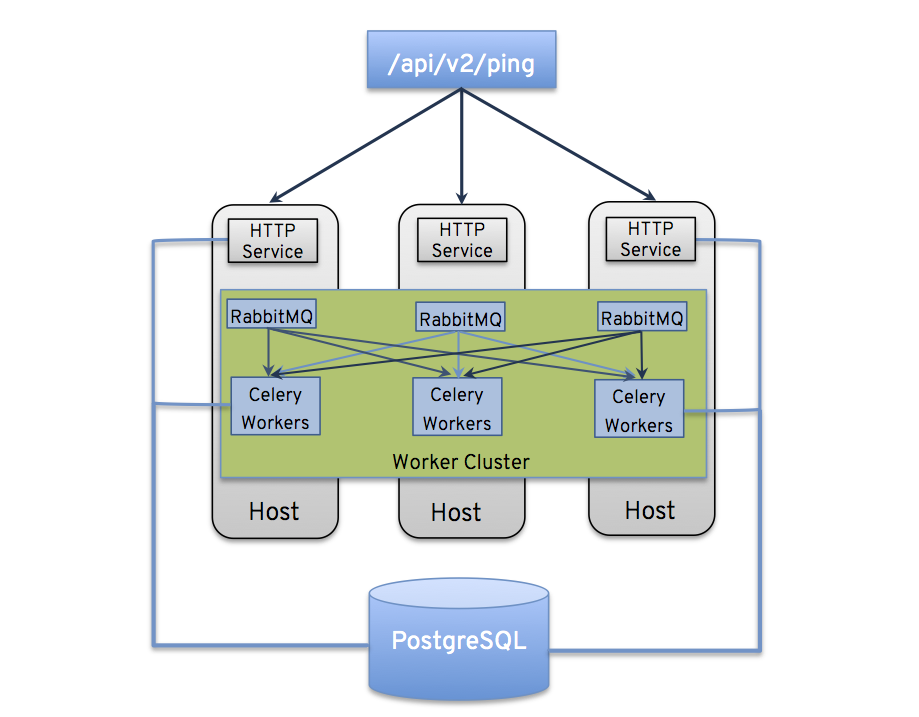
クラスターを複数のインスタンスグループに分類する場合は、クラスター全体の動作と類似します。インスタンス 2 台がグループに割り当てられると、同じグループ内の他のインスタンスと同様に、いずれかのインスタンスがジョブを受信する可能性が高いです。
Tower インスタンスがオンラインになると、Tower システムの作業容量が効率的に拡張されます。これらのインスタンスがインスタンスグループにも配置されている場合には、グループの容量も拡張されます。複数のグループの所属するインスタンスが作業を実行する場合は、所属する全グループから容量が減少します。インスタンスのプロビジョニングを解除すると、インスタンスの割当先のクラスターから容量がなくなります。詳細は、次のセクションの「インスタンスおよびインスタンスグループのプロビジョニング解除 」を参照してください。
注釈
すべてのインスタンスを同じ容量でプロビジョニングする必要はありません。
プロジェクトの更新は、以前とは動作が異なります。以前のリリースでは、単一のインスタンスで実行される通常のジョブでした。今回のリリースでは、ジョブを実行可能なインスタンスであればどこでも正常に実行できることが重要です。プロジェクトは、ジョブの実行直前に、インスタンス上で正しいバージョンに同期されます。
インスタンスグループが設定されているにも拘らず、そのグループ内のインスタンスがすべてオフラインまたは利用不可の場合には、そのグループのみを対象として起動されたジョブは、インスタンスが利用できるようになるまで待機状態となります。このようなシナリオが発生した場合の作業を処理できるように、フォールバックまたはバックアップ用のリソースをプロビジョニングする必要があります。
6.6.1. ジョブ実行場所の制御¶
デフォルトでは、ジョブが Tower のキューに送信されると、どのワーカーでもそのジョブを取得することができますが、ジョブを実行するインスタンスを制限するなど特定のジョブを実行するように制御することができます。ジョブテンプレート、インベントリー、または組織にインスタンスグループが割り当てられている場合には、対象のジョブテンプレートから実行されたジョブはデフォルトの動作を実行する資格はありません。つまり、これら 3 つのリソースに関連付けられたインスタンスグループに所属する全インスタンスに十分な容量がない場合には、ジョブは、容量を利用できるようになるまで待機状態のままになります。
ジョブの送信先のインスタンスグループを決定する場合の優先順位は、以下のとおりです。
- ジョブテンプレート
- インベントリー
- 組織 (プロジェクトの形式)
インスタンスグループがジョブテンプレートと関連付けられており、いずれも許容容量内である場合には、ジョブはインベントリーで指定したインスタンスグループ、次に組織で指定したインスタンスグループに送信されます。リソースがあるので、ジョブはこれらのグループ内で、任意の順番で実行してください。
グローバルの tower グループは、Playbook で定義されるカスタムのインスタンスグループと同様に、リソースと関連付けることができます。これは、ジョブテンプレートやインベントリーに希望のインスタンスグループを指定するのに使用できますが、容量が足りない場合にはジョブは別のインスタンスに送信できます。
6.6.1.1. ジョブ実行の例¶
たとえば、ジョブテンプレートと group_a を関連付けたり、インベントリーと tower グループを関連付けたりすることで、group_a の容量が足りなくなると、 tower グループをフォールバックとして使用できるようになります。
さらに、インスタンスグループにリソースを関連付けずに、フォールバックとして別のリソースを指定することができます。たとえば、ジョブテンプレートにインスタンスグループを割り当てずに、インベントリーや組織のインスタンスグループにフォールバックするように設定できます。
この設定には、優れたユースケースが他に 2 つあります。
- (ジョブテンプレートをインスタンスグループに割り当てずに) インスタンスグループにインベントリーを関連付けることで、特定のインベントリーに対して実行される Playbook が関連付けられたグループでのみ実行されるようにすることができます。これらのインスタンスのみが管理ノードに直接関連付けられている場合に非常に便利です。
- 管理者は、インスタンスグループに組織を割り当てることができます。これにより、管理者はインフラストラクチャー全体をセグメントに分け、各組織が他の組織のジョブ実行機能を妨げずに、ジョブを実行できるように保証します。
同様に、以下のシナリオのように、管理者は希望に合わせて複数のグループを各組織に割り当てることもできます。
- A、B、C の 3 つのインスタンスグループがあり、Org1 および Org2 の 2 つの組織がある場合
- 管理者が Org1 にグループ A を、Org2 にグループ B を、容量が余分に必要となる可能性があるのでオーバーフロー用として Org1 および Org2 両方にグループ C を割り当てる場合
- 組織の管理者が自由にインベントリーまたはジョブテンプレートを希望のグループに割り当てる (か、組織からのデフォルトの順番を継承する) 場合
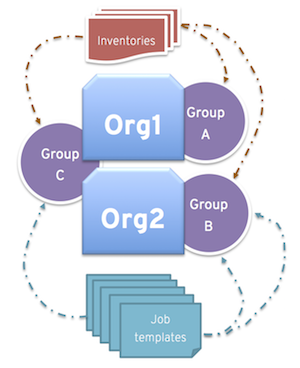
このような方法でリソースを割り当てると柔軟性が高くなります。また、インスタンスが 1 つしか含まれないインスタンスグループを作成することができるので、Tower クラスターの固有のホストに作業を割り当てることができるようになります。
6.7. インスタンスおよびインスタンスグループのプロビジョニング解除¶
Tower のプロビジョニングを解除すると、自動的にインスタンスのプロビジョニングが解除されるわけではありません。これは現在、インスタンスがオフラインになった理由が意図的なのか、障害が原因なのかをクラスターでは識別できないためです。代わりに、Tower インスタンスの全サービスをシャットダウンしてから、他のインスタンスからプロビジョニング解除ツールを実行します。
ansible-tower-service stopのコマンドで、インスタンスをシャットダウンするか、サービスを停止します。別のノードから
$ awx-manage deprovision_instance —-hostname=<name used in inventory file>のプロビジョニング解除のコマンドを実行して、Tower のクラスターレジストリーと、RabbitMQ クラスターレジストリーから削除します。例:
awx-manage deprovision_instance -—hostname=hostB
同様に、再プロビジョニングの際には通常、Tower のインスタンスグループが使用されないにも拘らず、Tower のインスタンスグループのプロビジョニングを解除しても、インスタンスグループが自動的に削除されたり、プロビジョニングが解除されたりしません。そのまま API エンドポイントに表示されたり、統計が監視されたりする可能性があります。これらのグループは、以下のコマンドを使用すると、削除することができます。
例:awx-manage unregister_queue --queuename=<name>