16. Job Templates¶
A job template is a definition and set of parameters for running an Ansible job. Job templates are useful to execute the same job many times. Job templates also encourage the reuse of Ansible playbook content and collaboration between teams. While the REST API allows for the execution of jobs directly, Tower requires that you first create a job template.
The (![]() ) menu opens a list of the job templates that are currently available. The default view is collapsed (Compact), showing the template name, template type, and the statuses of the jobs that ran using that template, but you can click Expanded to view more information. This list is sorted alphabetically by name, but you can sort by other criteria, or search by various fields and attributes of a template.
) menu opens a list of the job templates that are currently available. The default view is collapsed (Compact), showing the template name, template type, and the statuses of the jobs that ran using that template, but you can click Expanded to view more information. This list is sorted alphabetically by name, but you can sort by other criteria, or search by various fields and attributes of a template.
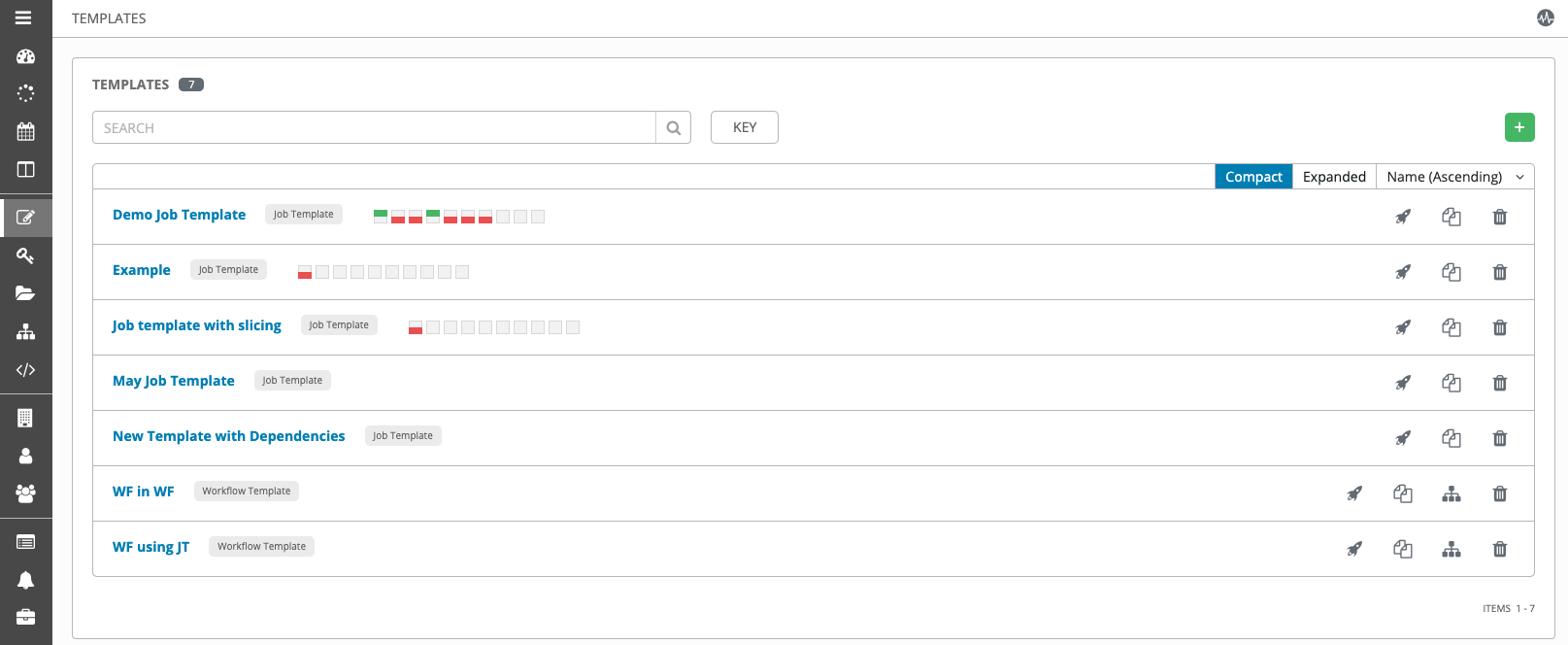
From this screen, you can launch ( ), copy (
), copy (  ), and remove (
), and remove (  ) a job template. Before deleting a job template, be sure it is not used in a workflow job template.
) a job template. Before deleting a job template, be sure it is not used in a workflow job template.
Note
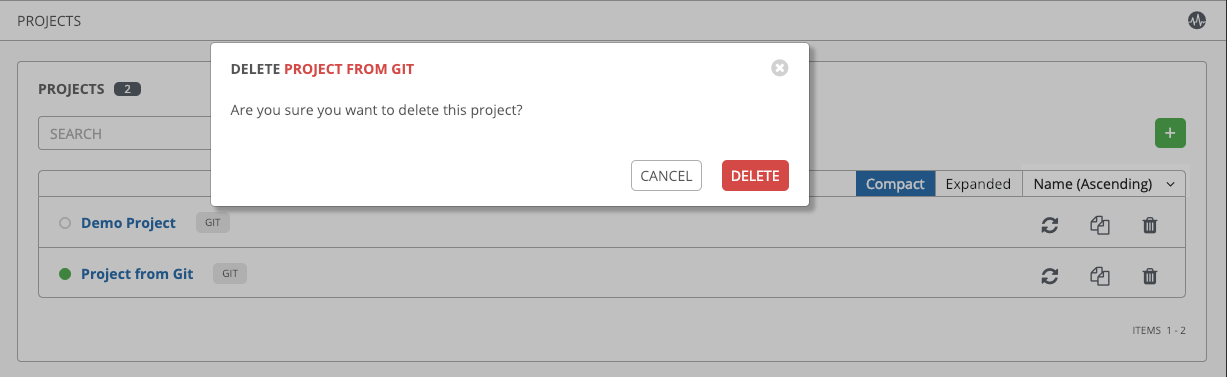
If deleting items that are used by other work items, a message opens listing the items are affected by the deletion and prompts you to confirm the deletion. Some screens will contain items that are invalid or previously deleted, so they will fail to run. Below is an example of such a message:
Note
Job templates can be used to build a workflow template. For templates that show the Workflow Visualizer (![]() ) icon next to them are workflow templates. Clicking it allows you to graphically build a workflow. Many parameters in a job template allow you to enable Prompt on Launch that can be modified at the workflow level, and do not affect the values assigned at the job template level. For instructions, see the Workflow Visualizer section.
) icon next to them are workflow templates. Clicking it allows you to graphically build a workflow. Many parameters in a job template allow you to enable Prompt on Launch that can be modified at the workflow level, and do not affect the values assigned at the job template level. For instructions, see the Workflow Visualizer section.
16.1. Create a Job Template¶
To create a new job template:
Click the
 button then select Job Template from the menu list.
button then select Job Template from the menu list.
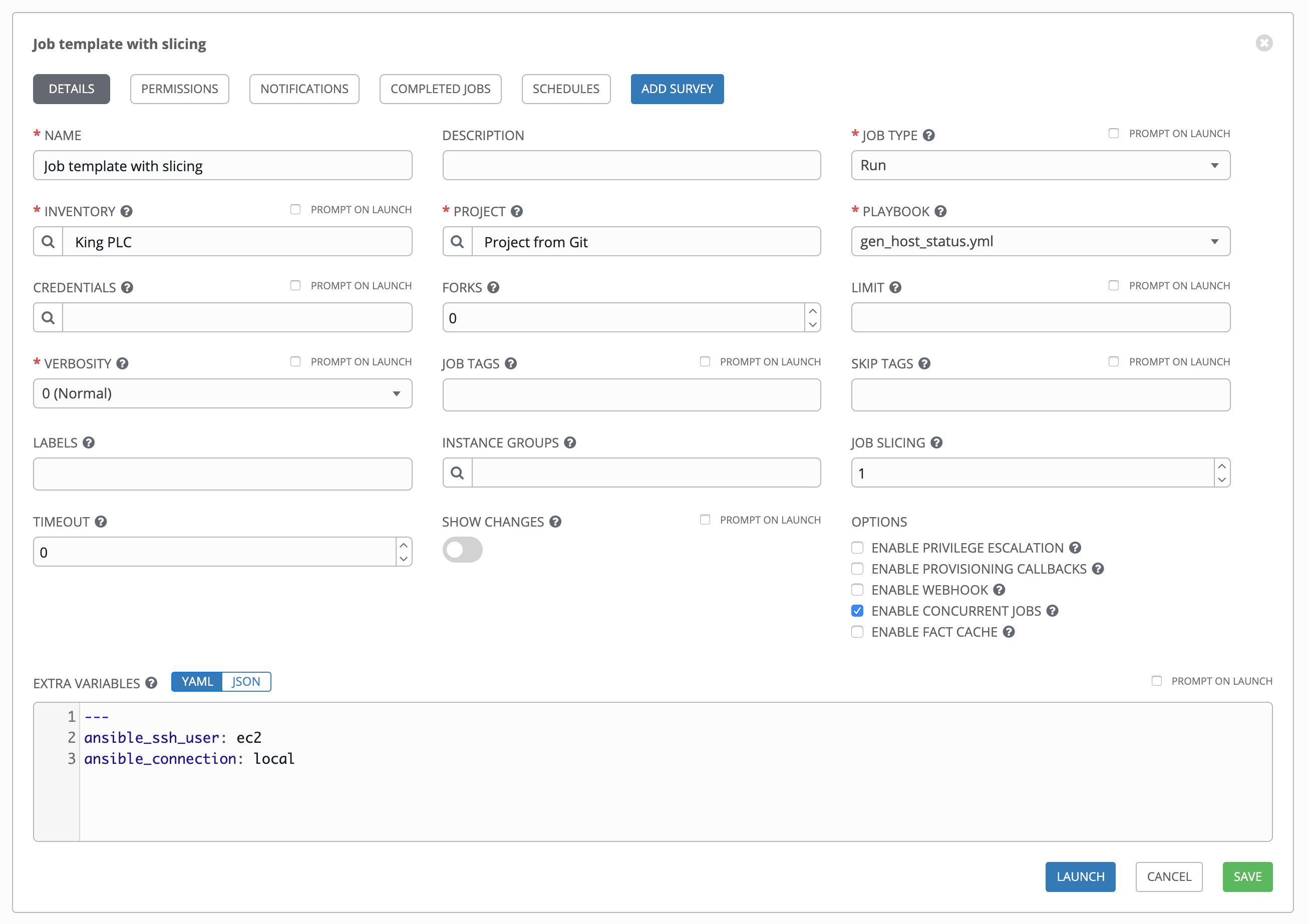
Enter the appropriate details into the following fields:
Name: Enter a name for the job.
Description: Enter an arbitrary description as appropriate (optional).
Job Type: Choose a job type:
Run: Execute the playbook when launched, running Ansible tasks on the selected hosts.
Check: Perform a “dry run” of the playbook and report changes that would be made without actually making them. Tasks that do not support check mode will be skipped and will not report potential changes.
Prompt on Launch: If selected, even if a default value is supplied, you will be prompted upon launch to choose a job type of run or check.
Note
More information on the Check job type, refer to Using check mode in the Ansible User Guide.
Inventory: Choose the inventory to be used with this job template from the inventories available to the currently logged in Tower user.
Prompt on Launch: If selected, even if a default value is supplied, you will be prompted upon launch to choose an inventory to run this job template against.
Project: Choose the project to be used with this job template from the projects available to the currently logged in Tower user.
SCM Branch: This field is only present if you chose a project that allows branch override. Specify the overriding branch to use in your job run. If left blank, the specified SCM branch (or commit hash or tag) from the project is used. For more detail, see job branch overriding.
Prompt on Launch: If selected, even if a default value is supplied, you will be prompted upon launch to choose an SCM branch.
Playbook: Choose the playbook to be launched with this job template from the available playbooks. This field automatically populates with the names of the playbooks found in the project base path for the selected project. Alternatively, you can enter the name of the playbook if it is not listed, such as the name of a file (like
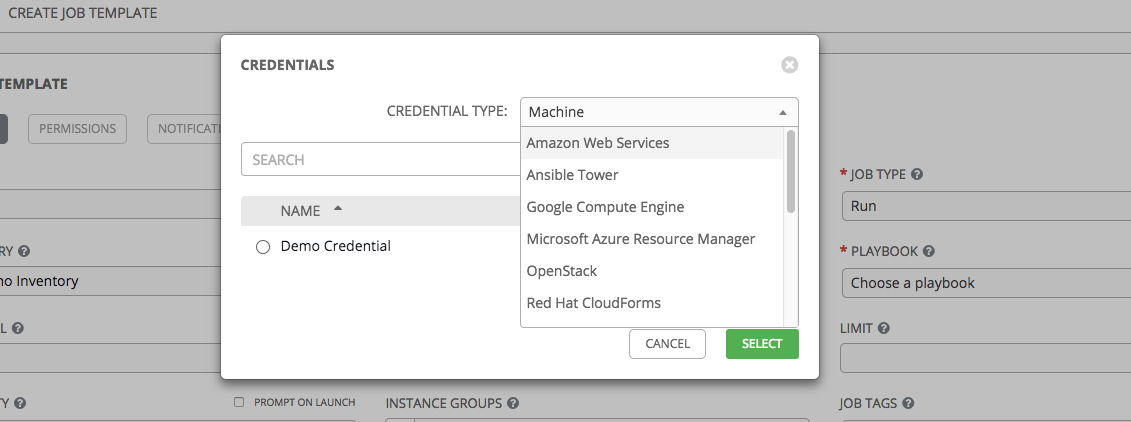
foo.yml) you want to use to run with that playbook. If you enter a filename that is not valid, the template will display an error, or cause the job to fail.Credentials: Click the
 button to open a separate window. Choose the credential from the available options to be used with this job template. Use the drop-down menu list to filter by credential type if the list is extensive.
button to open a separate window. Choose the credential from the available options to be used with this job template. Use the drop-down menu list to filter by credential type if the list is extensive.
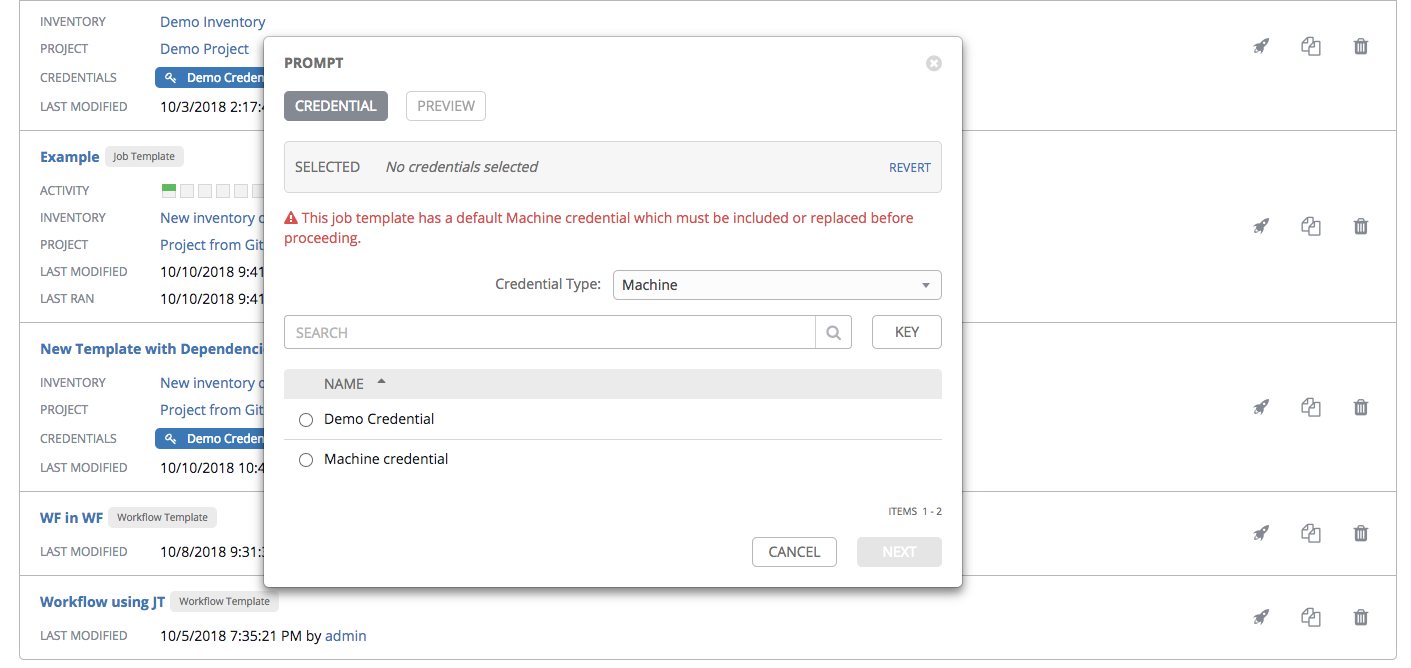
Prompt on Launch: If selected, upon launching a job template that has a default machine credential, you will not be able to remove the default machine credential in the Prompt dialog without replacing it with another machine credential before it can launch. Alternatively, you can add more credentials as you see fit. Below is an example of such a message:
Forks: The number of parallel or simultaneous processes to use while executing the playbook. A value of zero uses the Ansible default setting, which is 5 parallel processes unless overridden in
/etc/ansible/ansible.cfg.Limit: A host pattern to further constrain the list of hosts managed or affected by the playbook. Multiple patterns can be separated by colons (“:”). As with core Ansible, “a:b” means “in group a or b”, “a:b:&c” means “in a or b but must be in c”, and “a:!b” means “in a, and definitely not in b”.
Prompt on Launch: If selected, even if a default value is supplied, you will be prompted upon launch to choose a limit.
Note
For more information and examples refer to Patterns in the Ansible documentation.
Verbosity: Control the level of output Ansible produces as the playbook executes. Choose the verbosity from Normal to various Verbose or Debug settings. This only appears in the “details” report view. Verbose logging includes the output of all commands. Debug logging is exceedingly verbose and includes information on SSH operations that can be useful in certain support instances. Most users do not need to see debug mode output.
Warning
Verbosity 5 causes Tower to block heavily when jobs are running, which could delay reporting that the job has finished (even though it has) and can cause the browser tab to lock up.
Prompt on Launch: If selected, even if a default value is supplied, you will be prompted upon launch to choose a verbosity.
Job Tags: Provide a comma-separated list of playbook tags to specify what parts of the playbooks should be executed.
Prompt on Launch: If selected, even if a default value is supplied, you will be prompted upon launch to choose a job tag.
Skip Tags: Provide a comma-separated list of playbook tags to skip certain tasks or parts of the playbooks to be executed.
Prompt on Launch: If selected, even if a default value is supplied, you will be prompted upon launch to choose tag(s) to skip.
Note
For more information on tags and examples, refer to Tags in the Ansible documentation.
Labels: Supply optional labels that describe this job template, such as “dev” or “test”. Labels can be used to group and filter job templates and completed jobs in the Tower display.
Labels are created when they are added to the Job Template. Labels are associated to a single Organization using the Project that is provided in the Job Template. Members of the Organization can create labels on a Job Template if they have edit permissions (such as admin role).
Once the Job Template is saved, the labels appear in the Job Templates overview in the Expanded view.
Click on the “x” beside a label to remove it. When a label is removed, and is no longer associated with a Job or Job Template, the label is permanently deleted from the list of Organization labels.
Jobs inherit labels from the Job Template at the time of launch. If a label is deleted from a Job Template, it is also deleted from the Job.


Instance Groups: Click the
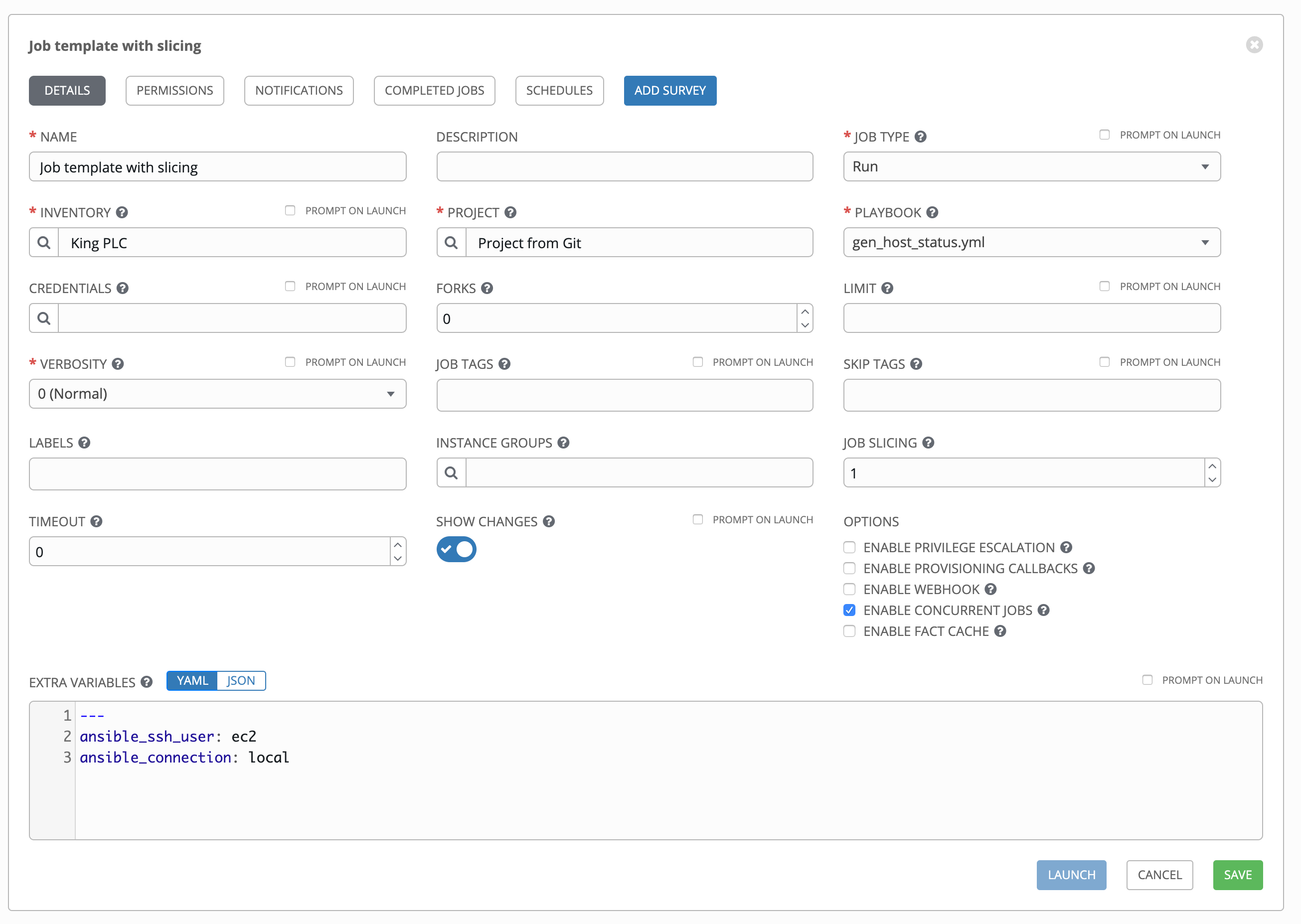
button to open a separate window. Choose the instance groups on which you want to run this job template. If the list is extensive, use the search to narrow the options.Job Slicing: Specify the number of slices you want this job template to run. Each slice will run the same tasks against a portion of the inventory. For more information about job slices, see Job Slicing.
Timeout: Allows you to specify the length of time (in seconds) Tower may run the task before it is canceled. Defaults to 0 for no job timeout.
Show Changes: Allows you to see the changes made by Ansible tasks.
Prompt on Launch: If selected, even if a default value is supplied, you will be prompted upon launch to choose whether or not to show changes.
Options: Supply optional labels that describe this job template, such as “dev” or “test”. Labels can be used to group and filter job templates and completed jobs in the Tower display.
Enable Privilege Escalation: If enabled, run this playbook as an administrator. This is the equivalent of passing the
--becomeoption to theansible-playbookcommand.Enable Provisioning Callbacks: Enable a host to call back to Tower via the Tower API and invoke the launch of a job from this job template. Refer to Provisioning Callbacks for additional information.
Enable Webhook: Turns on the ability to interface with a predefined SCM system web service that is used to launch a job template. Currently supported SCM systems are GitHub and GitLab.
If you enable webhooks, other fields display, prompting for additional information:

Webhook Service: Select which service to listen for webhooks from
Webhook Credential: Optionally, provide a GitHub or GitLab personal access token (PAT) as a credential to use to send status updates back to the webhook service. Before you can select it, the credential must exist. See Credential Types to create one.
Upon Save, additional fields display and remain present while viewing or editing.
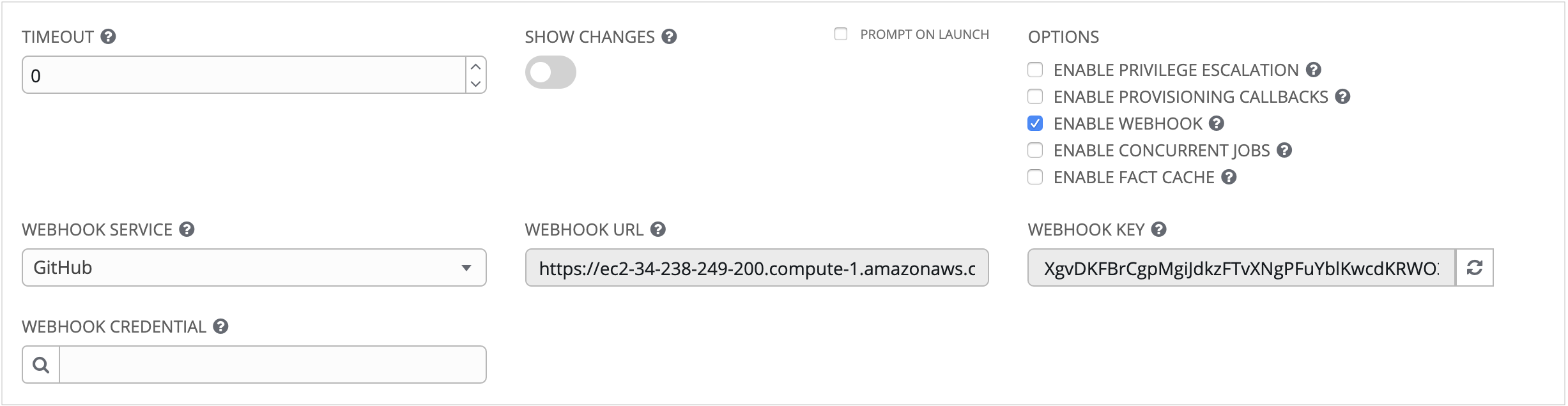
Webhook URL: Automatically populated with the URL for the webhook service to POST requests to.
Webhook Key: Generated shared secret to be used by the webhook service to sign payloads sent to Tower. This must be configured in the settings on the webhook service in order for Tower to accept webhooks from this service.
For additional information on setting up webhooks, see Working with Webhooks.
Enable Concurrent Jobs: Allow jobs in the queue to run simultaneously if not dependent on one another. Check this box if you want to run job slices simultaneously. Refer to Ansible Tower Capacity Determination and Job Impact for additional information.
Enable Fact Cache: When enabled, Tower will activate an Ansible fact cache plugin for all hosts in an inventory related to the job running.
Extra Variables:
Pass extra command line variables to the playbook. This is the “-e” or “–extra-vars” command line parameter for ansible-playbook that is documented in the Ansible documentation, Defining variables at runtime.
Provide key/value pairs using either YAML or JSON. These variables have a maximum value of precedence and overrides other variables specified elsewhere. An example value might be:
git_branch: production release_version: 1.5For more information about extra variables, refer to Extra Variables.
Prompt on Launch: If selected, even if a default value is supplied, you will be prompted upon launch to choose command line variables.
Note
If you want to be able to specify extra_vars on a schedule, you must select Prompt on Launch for EXTRA VARIABLES on the job template, or a enable a survey on the job template, then those answered survey questions become extra_vars.
When you have completed configuring the details of the job template, click Save.
Saving the template does not exit the job template page but remains on the Job Template Details view for further editing, if necessary. After saving the template, you can click Launch to launch the job, or proceed with adding more attributes about the template, such as permissions, notifications, view completed jobs, and add a survey (if the job type is not a scan). You must first save the template prior to launching, otherwise, the Launch button remains grayed-out.
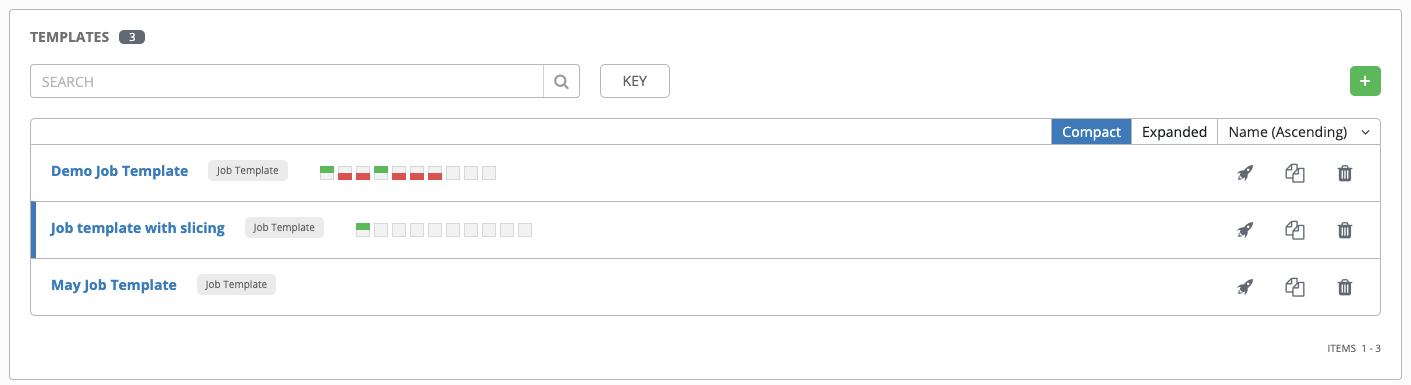
You can verify the template is saved when the newly created template appears on the list of templates at the bottom of the screen.
16.2. Add Permissions¶
The Permissions tab allows you to review, grant, edit, and remove associated permissions for users as well as team members. To assign permissions to a particular user for this resource:
Click the Permissions tab.
Click the
button to open the Add Users/Teams window.
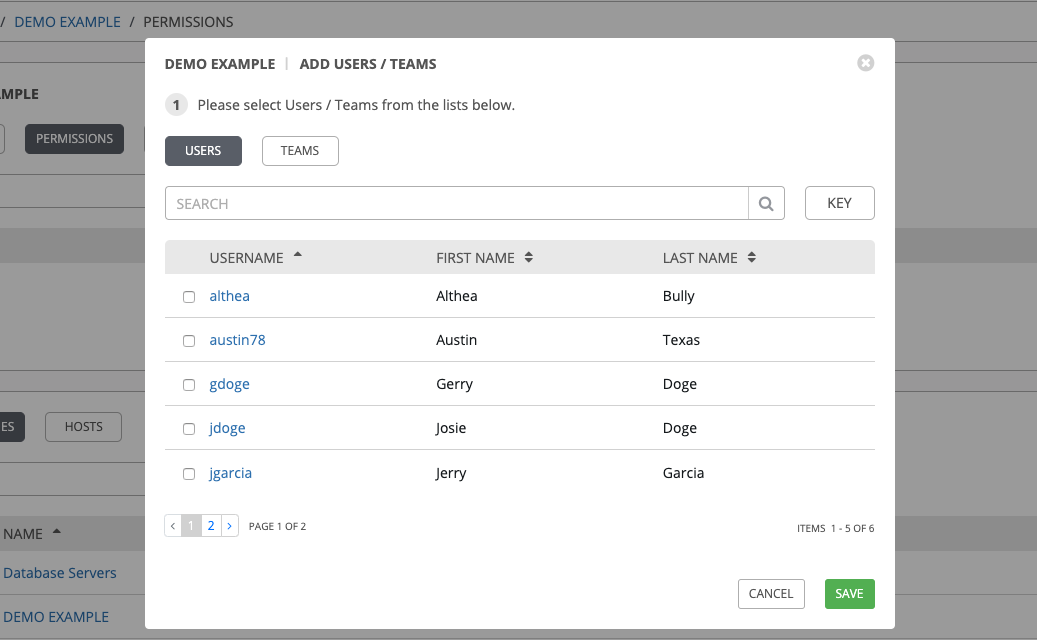
Specify the users or teams that will have access then assign them specific roles:
Click to select one or multiple check boxes beside the name(s) of the user(s) or team(s) to select them.
Note
You can select multiple users and teams at the same time by navigating between the Users and Teams tabs without saving.
After selections are made, the window expands to allow you to select a role from the drop-down menu list for each user or team you chose.
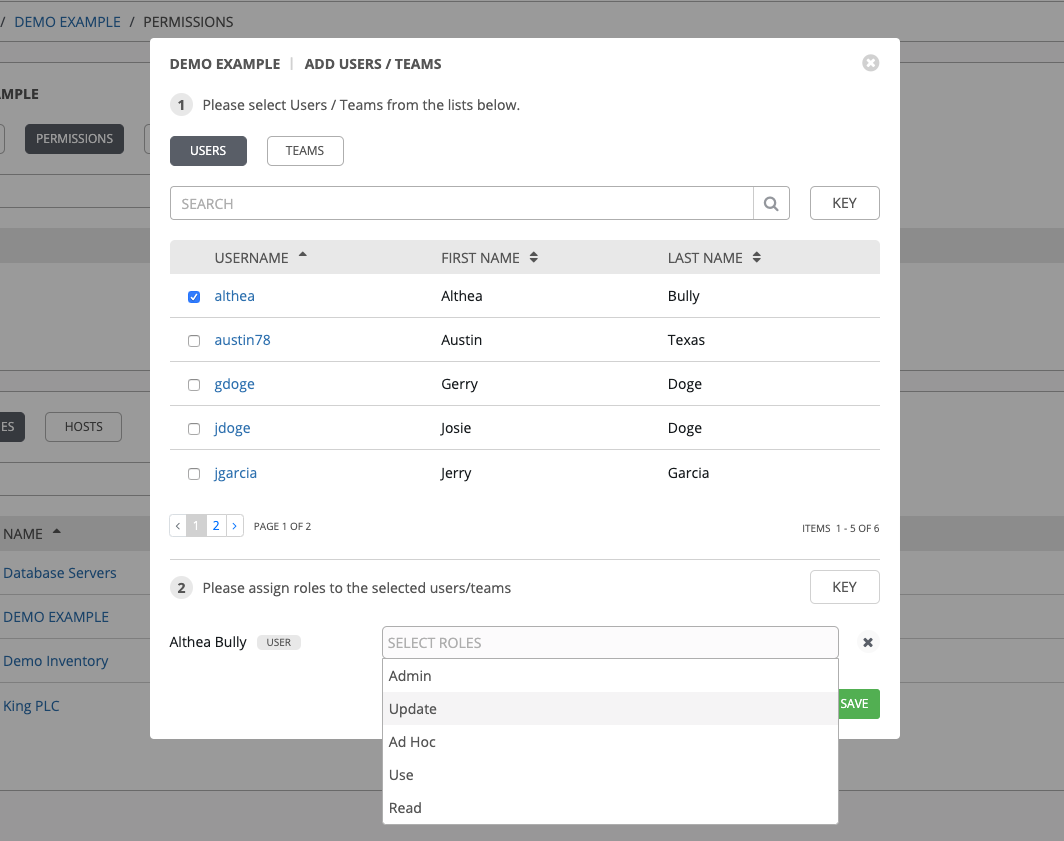
The example above shows options associated with inventories. Different resources have different options available:
Admin allows read, run, and edit privileges (applies to all resources)
Use allows use of a resource in a job template (applies all resources except job templates)
Update allows updating of project via the SCM Update (applies to projects and inventories)
Ad Hoc allows use of Ad Hoc commands (applies to inventories)
Execute allows launching of a job template (applies to job templates)
Read allows view-only access (applies to all resources)
Tip
Use the Key button in the roles selection pane to display a description of each of the roles. For more information, refer to the Roles section of this guide.
Select the role to apply to the selected user or team.
Note
You can assign roles to multiple users and teams by navigating between the Users and Teams tabs without saving.
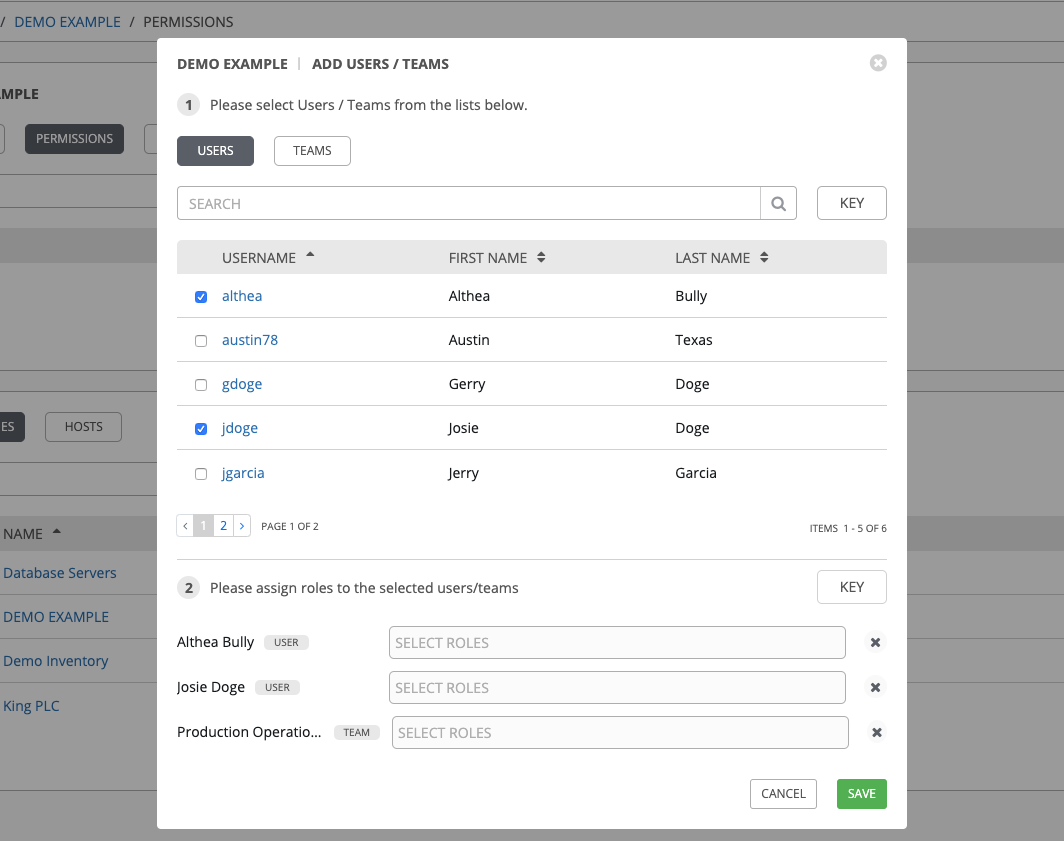
Review your role assignments for each user and team.
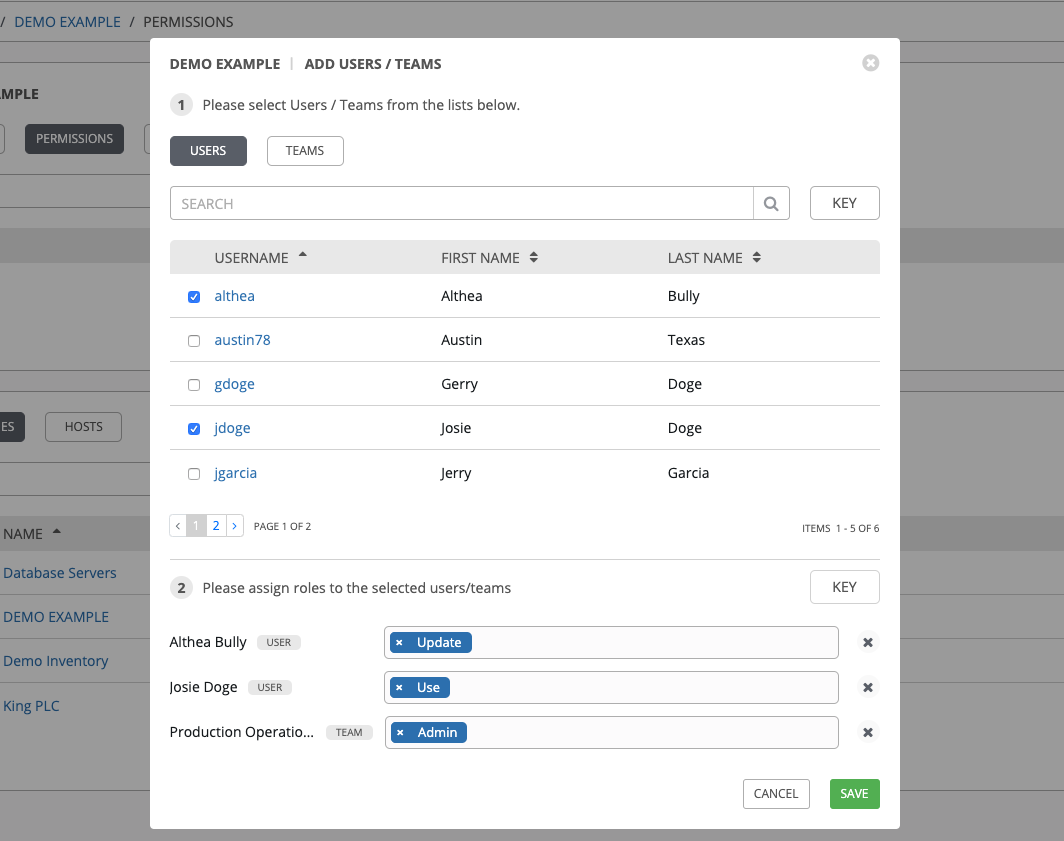
Click Save when done, and the Add Users/Teams window closes to display the updated roles assigned for each user and team.

To remove Permissions for a particular user, click the Disassociate (x) button next to its resource.

This launches a confirmation dialog, asking you to confirm the disassociation.
16.3. Work with Notifications¶
Clicking the Notifications tab allows you to review any notification integrations you have setup.
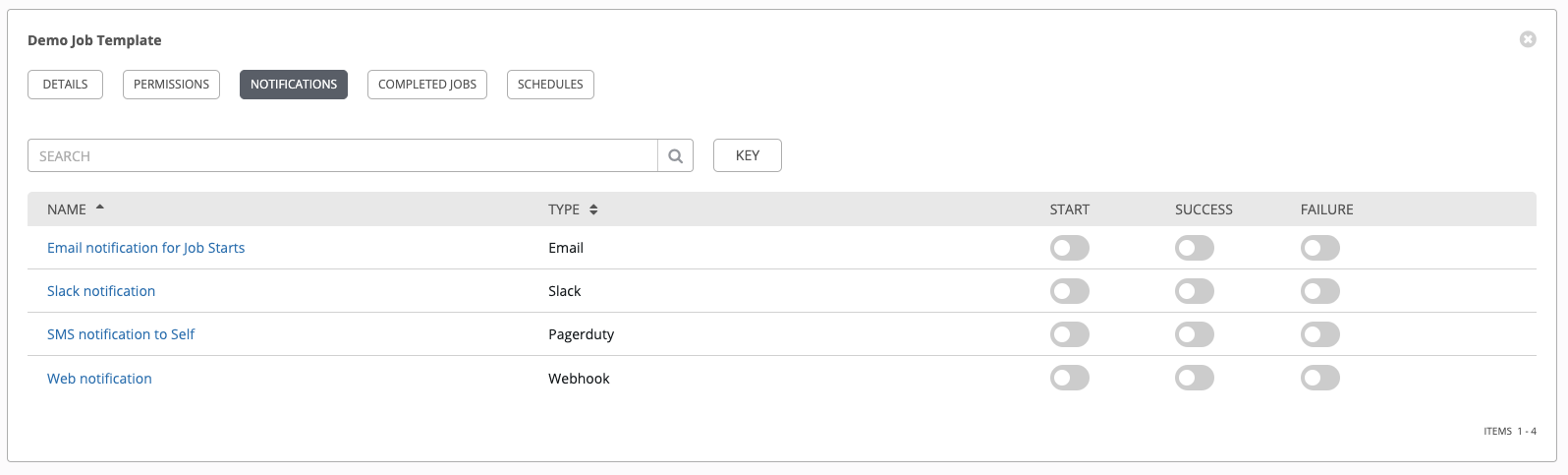
Use the toggles to enable or disable the notifications to use with your particular template. For more detail, see Enable and Disable Notifications.
If no notifications have been set up, click the NOTIFICATIONS link from inside the gray box to create a new notification.
Refer to Notification Types for additional details on configuring various notification types.
16.4. View Completed Jobs¶
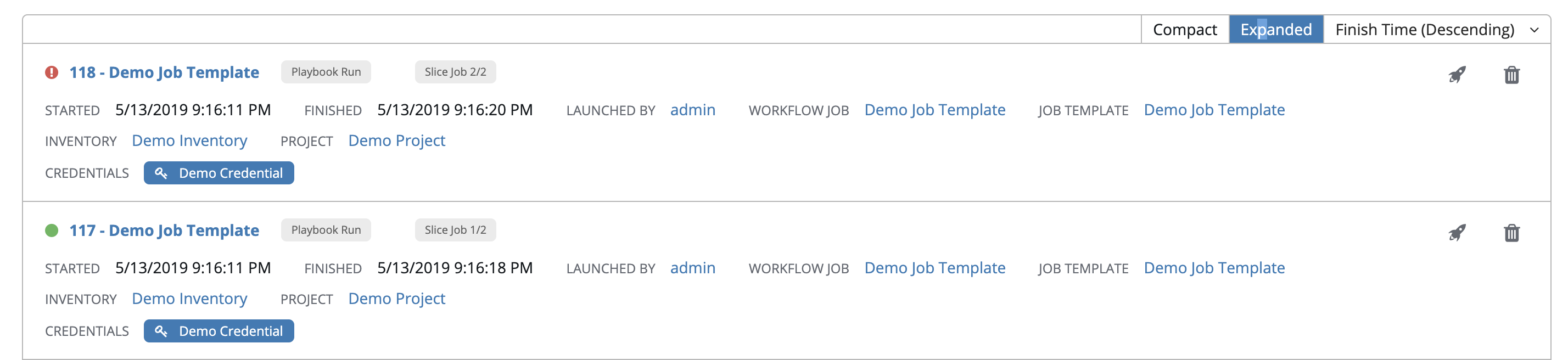
The Completed Jobs tab provides the list of job templates that have ran. Click Expanded to view details of each job, including its status, ID, and name; type of job, time started and completed, who started the job; and which template, inventory, project, and credential were used. You can filter the list of completed jobs using any of these criteria.
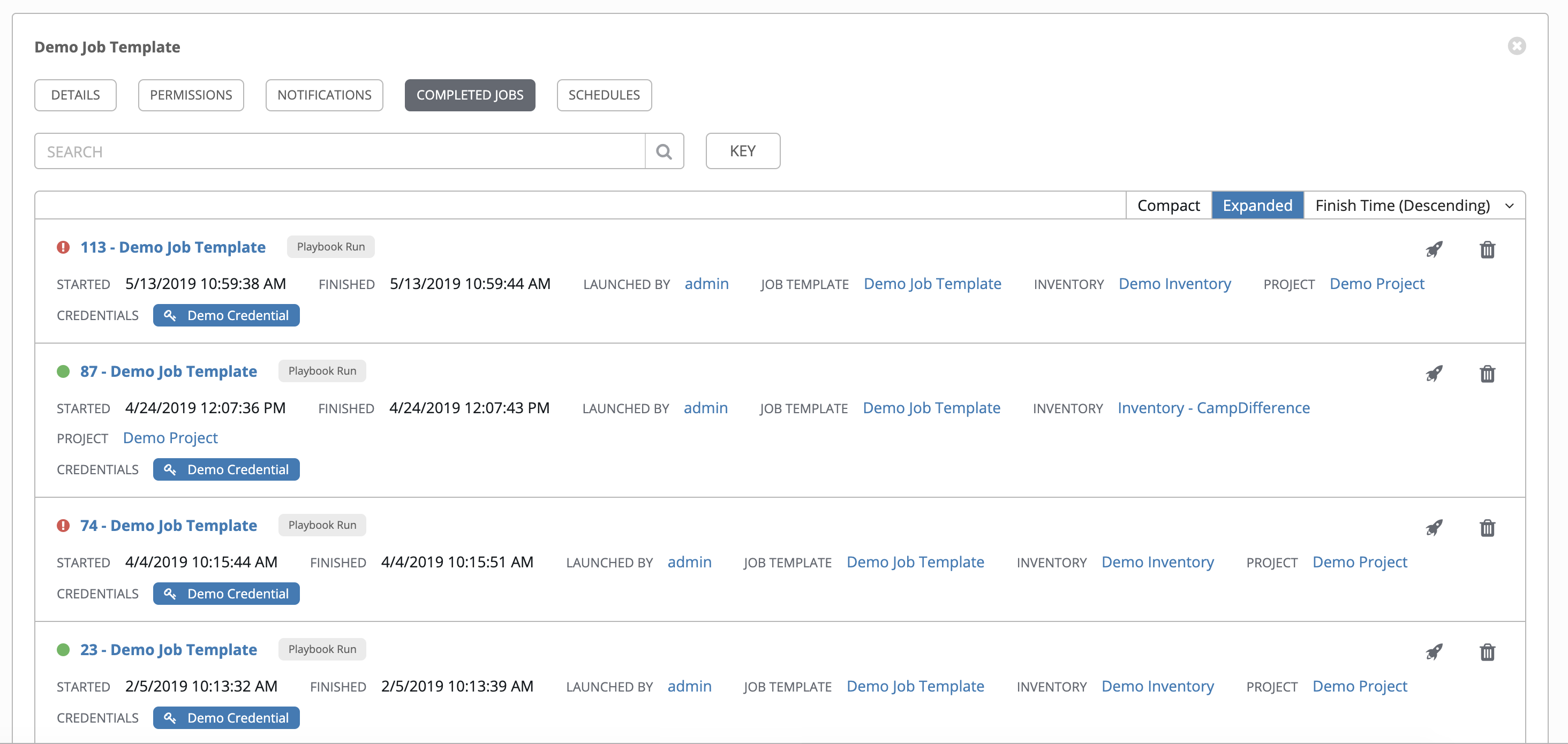
Sliced jobs that display on this list are labeled accordingly, with the number of sliced jobs that have run:
16.5. Scheduling¶
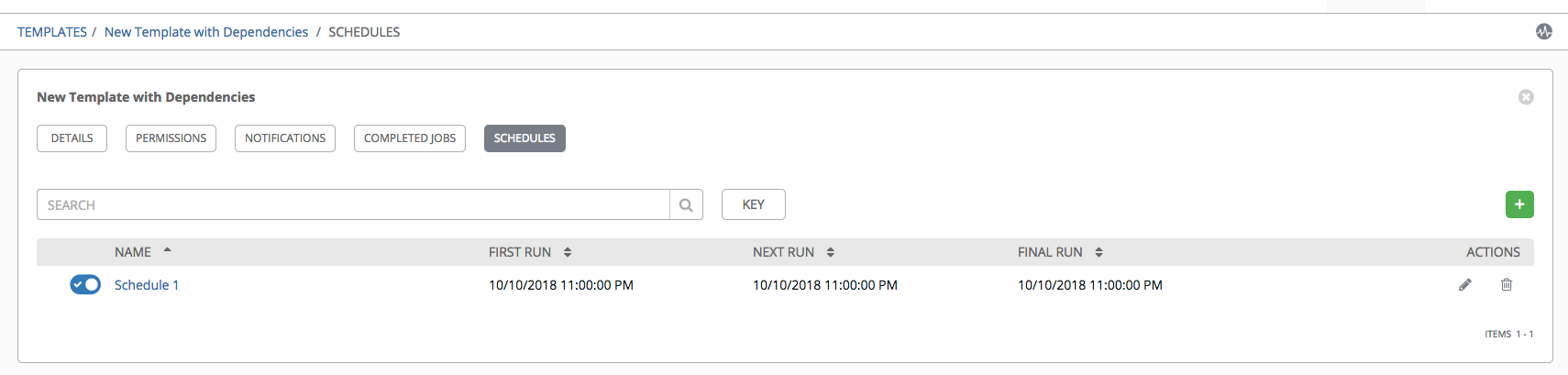
Access the schedules for a particular job template from the Schedules tab.
16.5.1. Schedule a Job Template¶
To schedule a job template run, click the Schedules tab.
If schedules are already set up; review, edit, or enable/disable your schedule preferences.
If schedules have not been set up, refer to Schedules for more information.
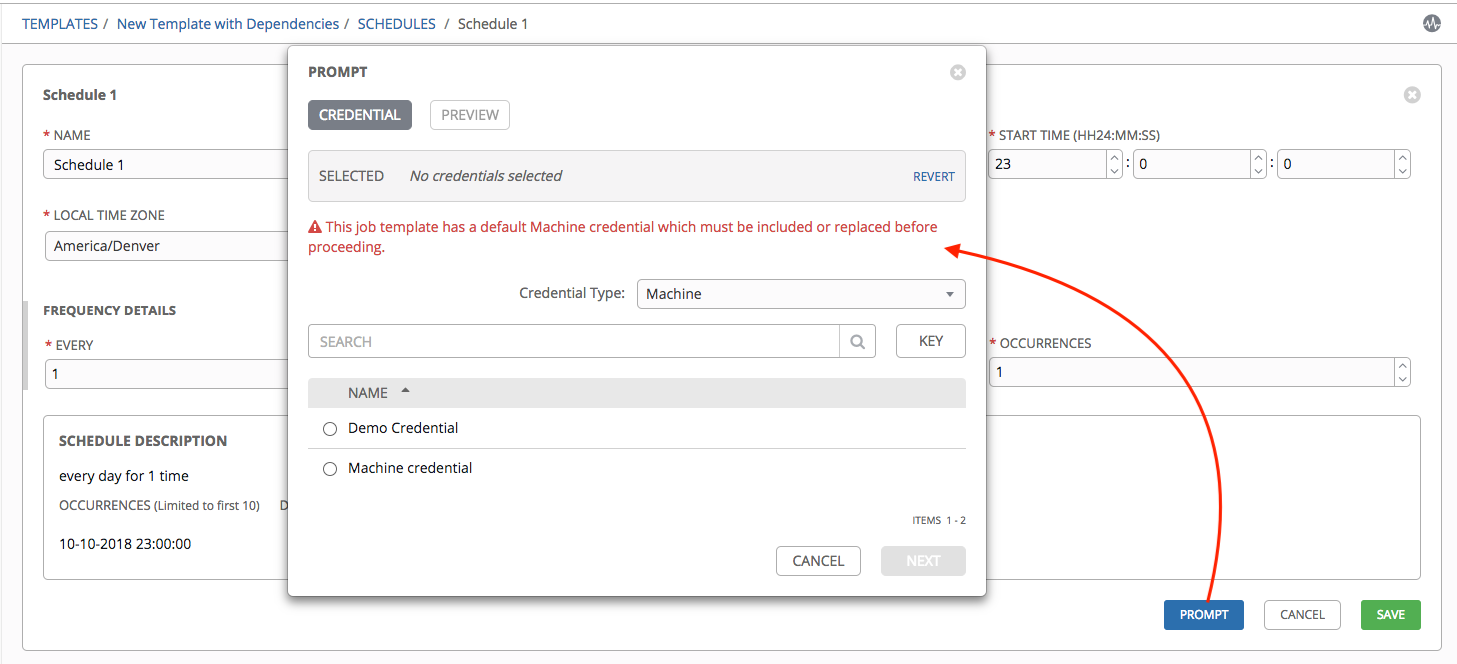
If Prompt on Launch was selected for the Credentials field, and you create or edit scheduling information for your job template, a Prompt button displays at the bottom of the Schedules form. You will not be able to remove the default machine credential in the Prompt dialog without replacing it with another machine credential before you can save it. Below is an example of such a message:
Note
To able to set extra_vars on schedules, you must select Prompt on Launch for EXTRA VARIABLES on the job template, or a enable a survey on the job template, then those answered survey questions become extra_vars.
16.6. Surveys¶
Job types of Run or Check will provide a way to set up surveys in the Job Template creation or editing screens. Surveys set extra variables for the playbook similar to ‘Prompt for Extra Variables’ does, but in a user-friendly question and answer way. Surveys also allow for validation of user input. Click the  button to create a survey.
button to create a survey.
Use cases for surveys are numerous. An example might be if operations wanted to give developers a “push to stage” button they could run without advanced Ansible knowledge. When launched, this task could prompt for answers to questions such as, “What tag should we release?”
Many types of questions can be asked, including multiple-choice questions.
16.6.1. Create a Survey¶
To create a survey:
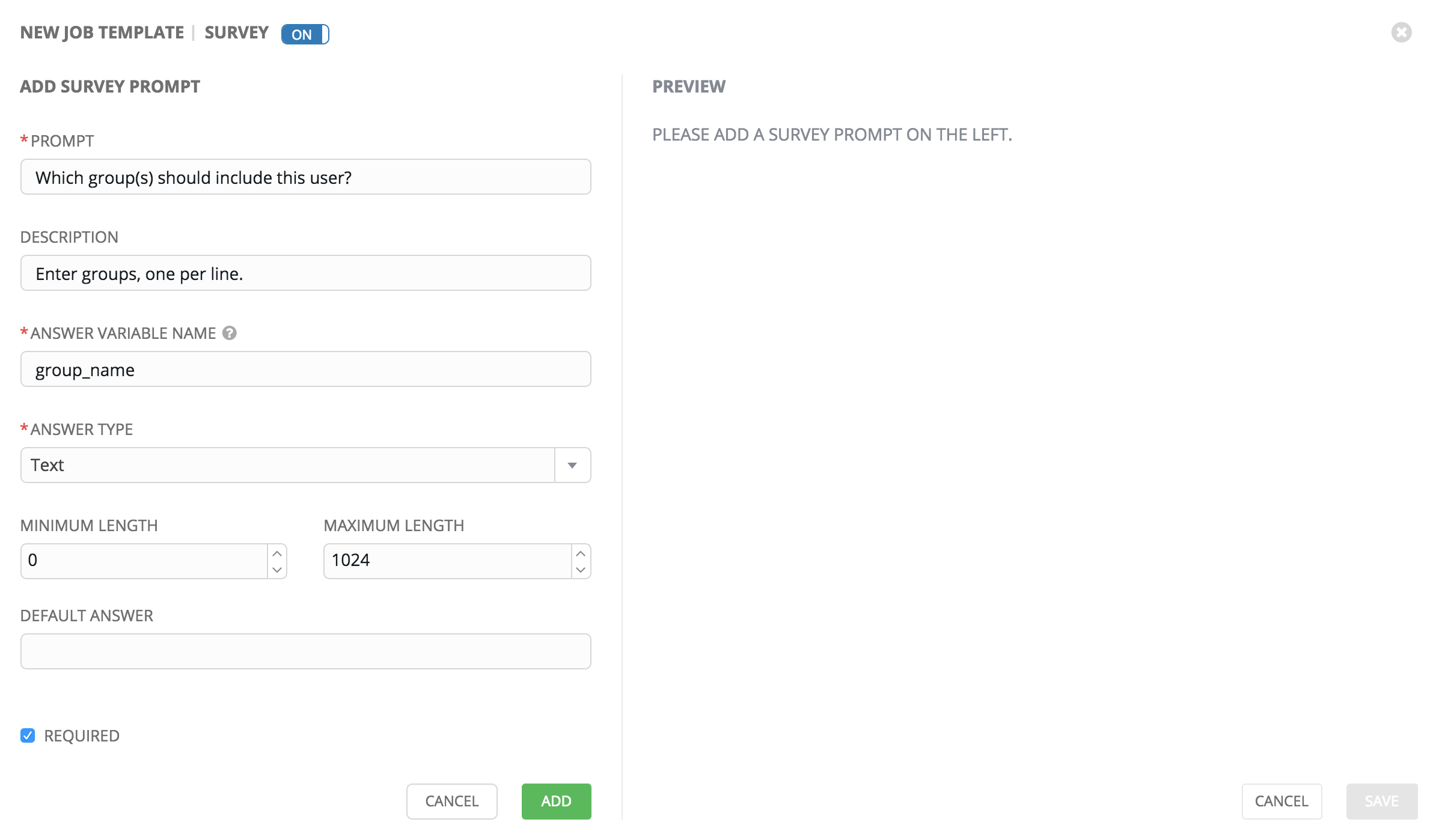
Click on the
button to bring up the Add Survey window.
Use the ON/OFF toggle button at the top of the screen to quickly activate or deactivate this survey prompt.
A survey can consist of any number of questions. For each question, enter the following information:
Name: The question to ask the user
Description: (optional) A description of what’s being asked of the user.
Answer Variable Name: The Ansible variable name to store the user’s response in. This is the variable to be used by the playbook. Variable names cannot contain spaces.
Answer Type: Choose from the following question types.
Text: A single line of text. You can set the minimum and maximum length (in characters) for this answer.
Textarea: A multi-line text field. You can set the minimum and maximum length (in characters) for this answer.
Password: Responses are treated as sensitive information, much like an actual password is treated. You can set the minimum and maximum length (in characters) for this answer.
Multiple Choice (single select): A list of options, of which only one can be selected at a time. Enter the options, one per line, in the Multiple Choice Options box.
Multiple Choice (multiple select): A list of options, any number of which can be selected at a time. Enter the options, one per line, in the Multiple Choice Options box.
Integer: An integer number. You can set the minimum and maximum length (in characters) for this answer.
Float: A decimal number. You can set the minimum and maximum length (in characters) for this answer.
Default Answer: The default answer to the question. This value is pre-filled in the interface and is used if the answer is not provided by the user.
Required: Whether or not an answer to this question is required from the user.
Once you have entered the question information, click the
button to add the question.
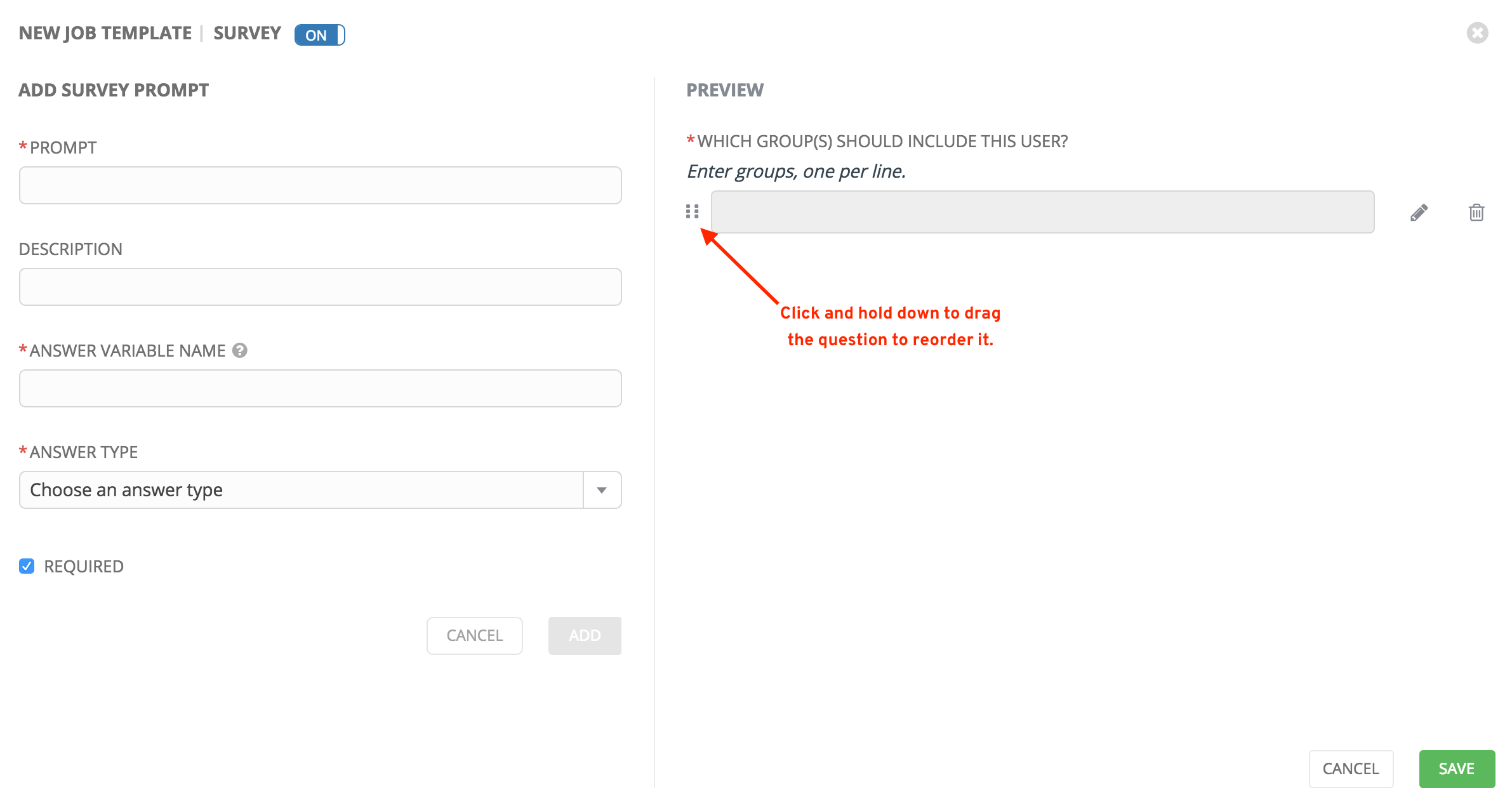
A stylized version of the survey is presented in the Preview pane. For any question, you can click on the Edit button to edit the question, the Delete button to delete the question, and click and drag on the grid icon to rearrange the order of the questions.
Return to the left pane to add additional questions.
When done, click Save to save the survey.
16.6.2. Optional Survey Questions¶
The Required setting on a survey question determines whether the answer is optional or not for the user interacting with it.
Behind the scenes, optional survey variables can be passed to the playbook in extra_vars, even when they aren’t filled in.
If a non-text variable (input type) is marked as optional, and is not filled in, no survey
extra_varis passed to the playbook.If a text input or text area input is marked as optional, is not filled in, and has a minimum
length > 0, no surveyextra_varis passed to the playbook.If a text input or text area input is marked as optional, is not filled in, and has a minimum
length === 0, that surveyextra_varis passed to the playbook, with the value set to an empty string ( “” ).
16.7. Launch a Job Template¶
A major benefit of Ansible Tower is the push-button deployment of Ansible playbooks. You can easily configure a template within Tower to store all parameters you would normally pass to the ansible-playbook on the command line–not just the playbooks, but the inventory, credentials, extra variables, and all options and settings you can specify on the command line.
Easier deployments drive consistency, by running your playbooks the same way each time, and allow you to delegate responsibilities–even users who aren’t Ansible experts can run Tower playbooks written by others.
Launch a job template by any of the following ways:
Access the job template list from the
 navigational link or while in the Job Template Details view, scroll to the bottom to access the button from the list of templates.
navigational link or while in the Job Template Details view, scroll to the bottom to access the button from the list of templates.
While in the Job Template Details view of the job template you want to launch, click Launch.
A job may require additional information to run. The following data may be requested at launch:
Credentials that were setup
The option
Prompt on Launchis selected for any parameterPasswords or passphrases that have been set to Ask
A survey, if one has been configured for the job templates
Extra variables, if requested by the job template
Note
If a job has user-provided values, then those are respected upon relaunch. If the user did not specify a value, then the job uses the default value from the job template. Jobs are not relaunched as-is. They are relaunched with the user prompts re-applied to the job template.
Below is an example job launch that prompts for Job Tags, and runs the example survey created in Surveys.
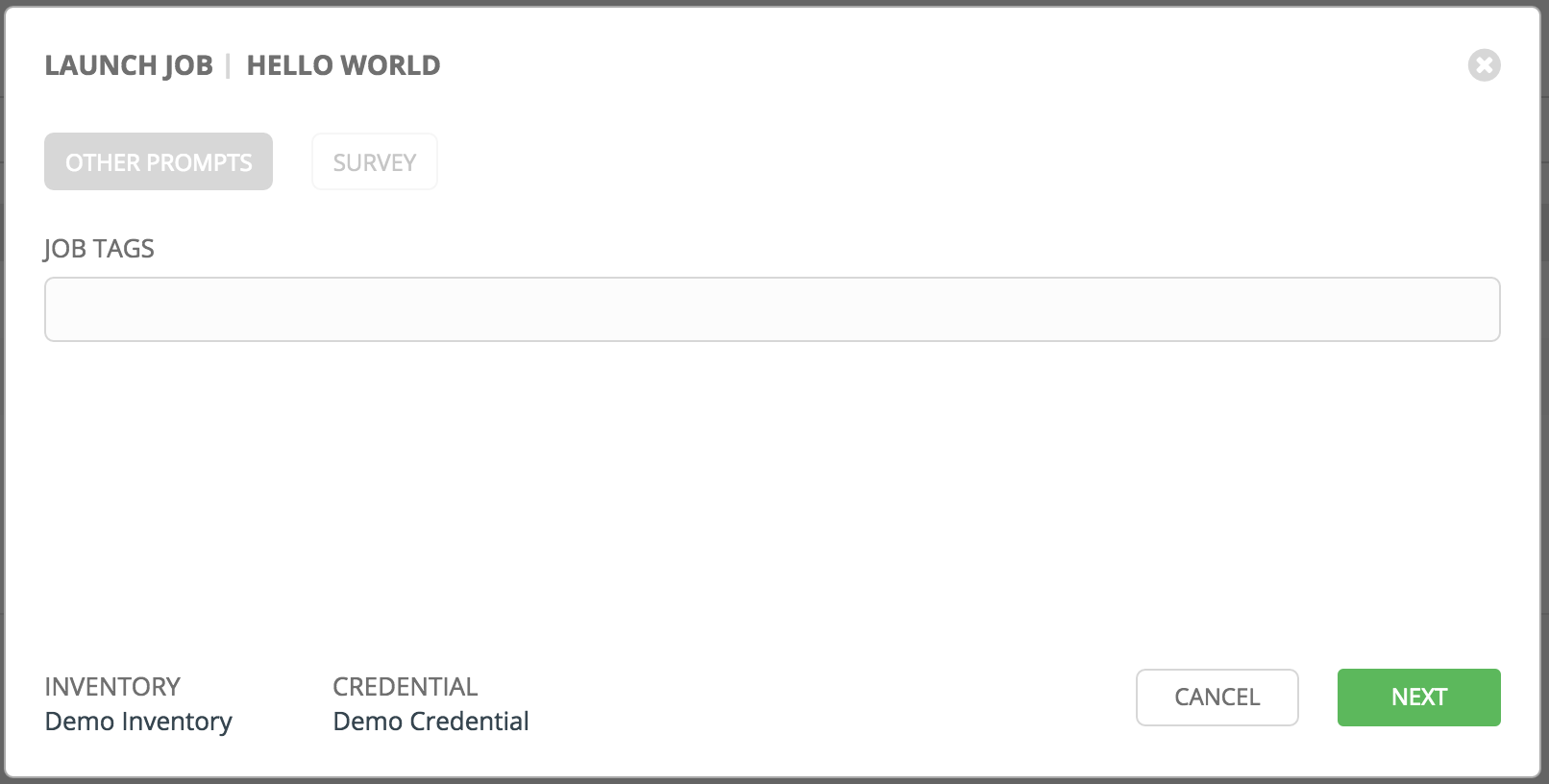
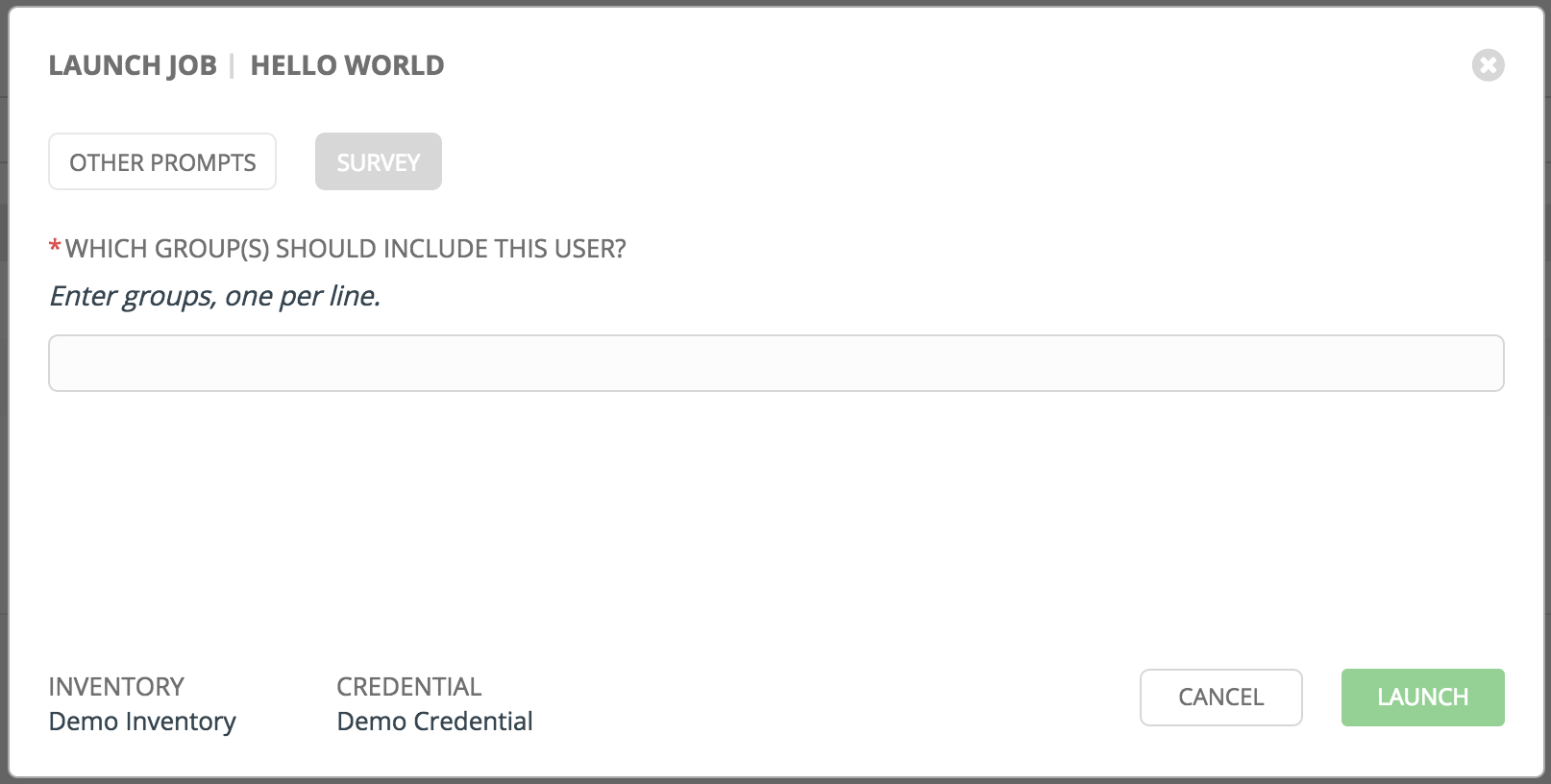
Note
Providing values on one tab, and going back to a previous tab, and then continuing on to the next tab will result in having to re-provide values on the rest of the tabs. Make sure you fill in the tabs in the order the prompts appear to avoid this.
Along with any extra variables set in the job template and survey, Tower automatically adds the following variables to the job environment:
tower_job_id: The Job ID for this job runtower_job_launch_type: The description to indicate how the job was started:manual: Job was started manually by a user.
relaunch: Job was started via relaunch.
callback: Job was started via host callback.
scheduled: Job was started from a schedule.
dependency: Job was started as a dependency of another job.
workflow: Job was started from a workflow job.
sync: Job was started from a project sync.
scm: Job was created as an Inventory SCM sync.
tower_job_template_id: The Job Template ID that this job run usestower_job_template_name: The Job Template name that this job usestower_project_revision: The revision identifier for the source tree that this particular job uses (it is also the same as the job’s fieldscm_revision)tower_user_email: The user email of the Tower user that started this job. This is not available for callback or scheduled jobs.tower_user_first_name: The user’s first name of the Tower user that started this job. This is not available for callback or scheduled jobs.tower_user_id: The user ID of the Tower user that started this job. This is not available for callback or scheduled jobs.tower_user_last_name: The user’s last name of the Tower user that started this job. This is not available for callback or scheduled jobs.tower_user_name: The user name of the Tower user that started this job. This is not available for callback or scheduled jobs.tower_schedule_id: If applicable, the ID of the schedule that launched this jobtower_schedule_name: If applicable, the name of the schedule that launched this jobtower_workflow_job_id: If applicable, the ID of the workflow job that launched this jobtower_workflow_job_name: If applicable, the name of the workflow job that launched this job. Note this is also the same as the workflow job template.tower_inventory_id: If applicable, the ID of the inventory this job usestower_inventory_name: If applicable, the name of the inventory this job uses
All variables are also given an “awx” prefix, for example, awx_job_id.
Upon launch, Tower automatically redirects the web browser to the Job Status page for this job under the Jobs tab.
Note
You can re-launch the most recent job from the list view to re-run on all hosts or just failed hosts in the specified inventory. Refer to Jobs in the Ansible Tower User Guide for more detail.
When slice jobs are running, job lists display the workflow and job slices, as well as a link to view their details individually.
16.8. Copy a Job Template¶
Ansible Tower 3.0 introduced the ability to copy a Job Template. If you choose to copy Job Template, it does not copy any associated schedule, notifications, or permissions. Schedules and notifications must be recreated by the user or admin creating the copy of the Job Template. The user copying the Job Template will be granted the admin permission, but no permissions are assigned (copied) to the Job Template.
Access the job template list from the
navigational link or while in the Job Template Details view, scroll to the bottom to access it from the list of templates.
Click the
button.
A new template opens with the name of the template from which you copied and a timestamp.
Replace the contents of the Name field with a new name, and provide or modify the entries in the other fields to complete this page.
Click Save when done.
16.9. Scan Job Templates¶
Scan jobs are no longer supported starting with Ansible Tower 3.2. This system tracking feature was used as a way to capture and store facts as historical data. Facts are now stored in Tower via fact caching. For more information, see Fact Caching.
If you have Job Template Scan Jobs in your system prior to Ansible Tower 3.2, they have been converted to type run (like normal job templates) and retained their associated resources (i.e. inventory, credential). Job Template Scan Jobs that do not have a related project are assigned a special playbook by default, or you can specify a project with your own scan playbook. A project was created for each organization that points to https://github.com/ansible/tower-fact-modules and the Job Template was set to the playbook, https://github.com/ansible/tower-fact-modules/blob/master/scan_facts.yml.
16.9.1. Fact Scan Playbooks¶
The scan job playbook, scan_facts.yml, contains invocations of three fact scan modules - packages, services, and files, along with Ansible’s standard fact gathering. The scan_facts.yml playbook file looks like the following:
- hosts: all
vars:
scan_use_checksum: false
scan_use_recursive: false
tasks:
- scan_packages:
- scan_services:
- scan_files:
paths: '{{ scan_file_paths }}'
get_checksum: '{{ scan_use_checksum }}'
recursive: '{{ scan_use_recursive }}'
when: scan_file_paths is defined
The scan_files fact module is the only module that accepts parameters, passed via extra_vars on the scan job template.
scan_file_paths: '/tmp/'
scan_use_checksum: true
scan_use_recursive: true
The
scan_file_pathsparameter may have multiple settings (such as/tmp/or/var/log).The
scan_use_checksumandscan_use_recursiveparameters may also be set to false or omitted. An omission is the same as a false setting.
Scan job templates should enable become and use credentials for which become is a possibility. You can enable become by checking the Enable Privilege Escalation from the Options menu:
Note
If you maintained scan job templates in Ansible Tower 3.1.x and then upgrade to Ansible Tower 3.2, a new “Tower Fact Scan - Default” project is automatically created for you. This project contains the old scan playbook previously used in earlier versions of Ansible Tower.
16.9.2. Supported OSes for scan_facts.yml¶
If you use the scan_facts.yml playbook with use fact cache, ensure that your OS is supported:
Red Hat Enterprise Linux 5, 6, & 7
CentOS 5, 6, & 7
Ubuntu 16.04 (Support for Unbuntu is deprecated and will be removed in a future release)
OEL 6 & 7
SLES 11 & 12
Debian 6, 7, 8
Fedora 22, 23, 24
Amazon Linux 2016.03
Windows Server 2008 and later
Note that some of these operating systems may require initial configuration in order to be able to run python and/or have access to the python packages (such as python-apt) that the scan modules depend on.
16.9.3. Pre-scan Setup¶
The following are examples of playbooks that configure certain distributions so that scan jobs can be run against them.
Bootstrap Ubuntu (16.04)
---
- name: Get Ubuntu 16, and on ready
hosts: all
sudo: yes
gather_facts: no
tasks:
- name: install python-simplejson
raw: sudo apt-get -y update
raw: sudo apt-get -y install python-simplejson
raw: sudo apt-get install python-apt
Bootstrap Fedora (23, 24)
---
- name: Get Fedora ready
hosts: all
sudo: yes
gather_facts: no
tasks:
- name: install python-simplejson
raw: sudo dnf -y update
raw: sudo dnf -y install python-simplejson
raw: sudo dnf -y install rpm-python
CentOS 5 or Red Hat Enterprise Linux 5 may also need the simplejson package installed.
16.9.4. Custom Fact Scans¶
A playbook for a custom fact scan is similar to the example of the Fact Scan Playbook above. As an example, a playbook that only uses a custom scan_foo Ansible fact module would look like this:
scan_custom.yml:
- hosts: all
gather_facts: false
tasks:
- scan_foo:
scan_foo.py:
def main():
module = AnsibleModule(
argument_spec = dict())
foo = [
{
"hello": "world"
},
{
"foo": "bar"
}
]
results = dict(ansible_facts=dict(foo=foo))
module.exit_json(**results)
main()
To use a custom fact module, ensure that it lives in the /library/ subdirectory of the Ansible project used in the scan job template. This fact scan module is very simple, returning a hard-coded set of facts:
[
{
"hello": "world"
},
{
"foo": "bar"
}
]
Refer to the Ansible module development section of the Ansible documentation for more information.
16.10. Fact Caching¶
Tower can store and retrieve facts on a per-host basis through an Ansible Fact Cache plugin. This behavior is configurable on a per-job template basis. Fact caching is turned off by default but can be enabled to serve fact requests for all hosts in an inventory related to the job running. This allows you to use job templates with --limit while still having access to the entire inventory of host facts. A global timeout setting that the plugin enforces per-host, can be specified (in seconds) through the Configure Tower interface under the Jobs tab:
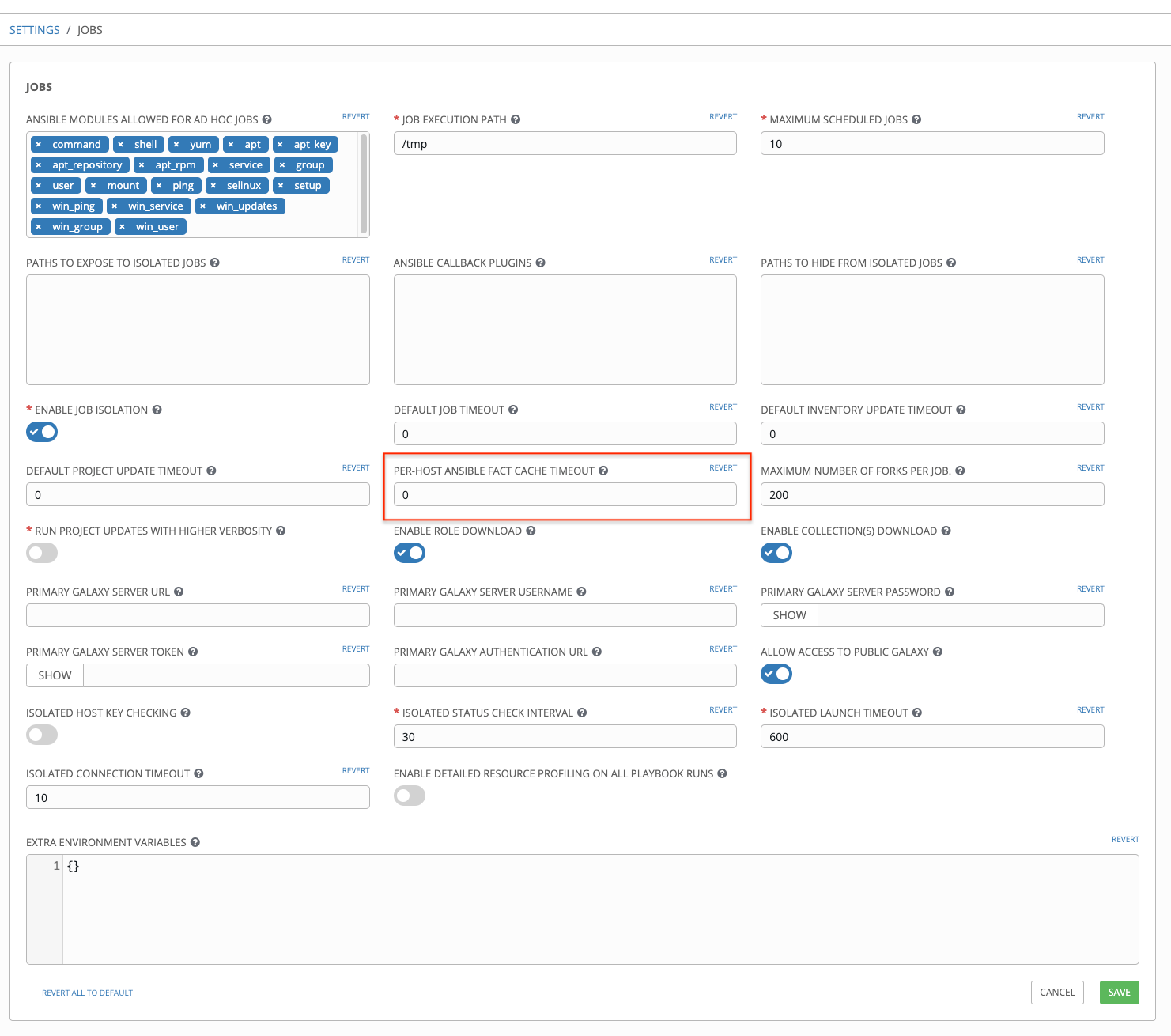
Upon launching a job that uses fact cache (use_fact_cache=True), Tower will store all ansible_facts associated with each host in the inventory associated with the job. The Ansible Fact Cache plugin that ships with Ansible Tower will only be enabled on jobs with fact cache enabled (use_fact_cache=True).
When a job that has fact cache enabled (use_fact_cache=True) finishes running, Tower will restore all records for the hosts in the inventory. Any records with update times newer than the currently stored facts per-host will be updated in the database.
New and changed facts will be logged via Tower’s logging facility. Specifically, to the system_tracking namespace or logger. The logging payload will include the fields:
host_name
inventory_id
ansible_facts
where ansible_facts is a dictionary of all Ansible facts for host_name in Tower inventory, inventory_id.
Note
If a hostname includes a forward slash (/), fact cache will not work for that host. If you have an inventory with 100 hosts and one host has a / in the name, 99 of those hosts will still collect facts.
16.10.1. Benefits of Fact Caching¶
Fact caching saves a significant amount of time over running fact gathering. If you have a playbook in a job that runs against a thousand hosts and forks, you could easily spend 10 minutes gathering facts across all of those hosts. But if you run a job on a regular basis, the first run of it caches these facts and the next run will just pull them from the database. This cuts the runtime of jobs against large inventories, including Smart Inventories, by an enormous magnitude.
Note
Do not modify the ansible.cfg file to apply fact caching. Custom fact caching could conflict with Tower’s fact caching feature. It is recommended to use the fact caching module that comes with Ansible Tower. Fact caching is not supported for isolated nodes.
You can choose to use cached facts in your job by enabling it in the Options field of the Job Templates window.

To clear facts, you need to run the Ansible clear_facts meta task. Below is an example playbook that uses the Ansible clear_facts meta task.
- hosts: all
gather_facts: false
tasks:
- name: Clear gathered facts from all currently targeted hosts
meta: clear_facts
The API endpoint for fact caching can be found at: http://<Tower server name>/api/v2/hosts/x/ansible_facts.
16.11. Utilizing Cloud Credentials¶
Cloud Credentials can be used when syncing a respective cloud inventory. Cloud Credentials may also be associated with a Job Template and included in the runtime environment for use by a playbook. Cloud Credentials were introduced in Ansible Tower version 2.4.0 and these are currently supported:
16.11.1. OpenStack¶
The sample playbook below invokes the nova_compute Ansible OpenStack cloud module and requires credentials to do anything meaningful, and specifically requires the following information: auth_url, username, password, and project_name. These fields are made available to the playbook via the environmental variable OS_CLIENT_CONFIG_FILE, which points to a YAML file written by Tower based on the contents of the cloud credential. This sample playbook loads the YAML file into the Ansible variable space.
OS_CLIENT_CONFIG_FILE example:
clouds:
devstack:
auth:
auth_url: http://devstack.yoursite.com:5000/v2.0/
username: admin
password: your_password_here
project_name: demo
Playbook example:
- hosts: all
gather_facts: false
vars:
config_file: "{{ lookup('env', 'OS_CLIENT_CONFIG_FILE') }}"
nova_tenant_name: demo
nova_image_name: "cirros-0.3.2-x86_64-uec"
nova_instance_name: autobot
nova_instance_state: 'present'
nova_flavor_name: m1.nano
nova_group:
group_name: antarctica
instance_name: deceptacon
instance_count: 3
tasks:
- debug: msg="{{ config_file }}"
- stat: path="{{ config_file }}"
register: st
- include_vars: "{{ config_file }}"
when: st.stat.exists and st.stat.isreg
- name: "Print out clouds variable"
debug: msg="{{ clouds|default('No clouds found') }}"
- name: "Setting nova instance state to: {{ nova_instance_state }}"
local_action:
module: nova_compute
login_username: "{{ clouds.devstack.auth.username }}"
login_password: "{{ clouds.devstack.auth.password }}"
16.11.2. Amazon Web Services¶
Amazon Web Services cloud credentials are exposed as the following environment variables during playbook execution (in the job template, choose the cloud credential needed for your setup):
AWS_ACCESS_KEY_IDAWS_SECRET_ACCESS_KEY
All of the AWS modules will implicitly use these credentials when run via Tower without having to set the aws_access_key_id or aws_secret_access_key module options.
16.11.3. Rackspace¶
Rackspace cloud credentials are exposed as the following environment variables during playbook execution (in the job template, choose the cloud credential needed for your setup):
RAX_USERNAMERAX_API_KEY
All of the Rackspace modules will implicitly use these credentials when run via Tower without having to set the username or api_key module options.
16.11.4. Google¶
Google cloud credentials are exposed as the following environment variables during playbook execution (in the job template, choose the cloud credential needed for your setup):
GCE_EMAILGCE_PROJECTGCE_CREDENTIALS_FILE_PATH
All of the Google modules will implicitly use these credentials when run via Tower without having to set the service_account_email, project_id, or pem_file module options.
16.11.5. Azure¶
Azure cloud credentials are exposed as the following environment variables during playbook execution (in the job template, choose the cloud credential needed for your setup):
AZURE_SUBSCRIPTION_IDAZURE_CERT_PATH
All of the Azure modules implicitly use these credentials when run via Tower without having to set the subscription_id or management_cert_path module options.
16.11.6. VMware¶
VMware cloud credentials are exposed as the following environment variables during playbook execution (in the job template, choose the cloud credential needed for your setup):
VMWARE_USERVMWARE_PASSWORDVMWARE_HOST
The sample playbook below demonstrates usage of these credentials:
- vsphere_guest:
vcenter_hostname: "{{ lookup('env', 'VMWARE_HOST') }}"
username: "{{ lookup('env', 'VMWARE_USER') }}"
password: "{{ lookup('env', 'VMWARE_PASSWORD') }}"
guest: newvm001
from_template: yes
template_src: centosTemplate
cluster: MainCluster
resource_pool: "/Resources"
vm_extra_config:
folder: MyFolder
16.12. Provisioning Callbacks¶
Provisioning callbacks are a feature of Tower that allow a host to initiate a playbook run against itself, rather than waiting for a user to launch a job to manage the host from the tower console. Please note that provisioning callbacks are only used to run playbooks on the calling host. Provisioning callbacks are meant for cloud bursting, ie: new instances with a need for client to server communication for configuration (such as transmitting an authorization key), not to run a job against another host. This provides for automatically configuring a system after it has been provisioned by another system (such as AWS auto-scaling, or a OS provisioning system like kickstart or preseed) or for launching a job programmatically without invoking the Tower API directly. The Job Template launched only runs against the host requesting the provisioning.
Frequently this would be accessed via a firstboot type script, or from cron.
To enable callbacks, check the Allow Provisioning Callbacks checkbox in the Job Template. This displays the Provisioning Callback URL for this job template.
Note
If you intend to use Tower’s provisioning callback feature with a dynamic inventory, Update on Launch should be set for the inventory group used in the Job Template.

Callbacks also require a Host Config Key, to ensure that foreign hosts with the URL cannot request configuration. Click the  button to create a unique host key for this callback, or enter your own key. The host key may be reused across multiple hosts to apply this job template against multiple hosts. Should you wish to control what hosts are able to request configuration, the key may be changed at any time.
button to create a unique host key for this callback, or enter your own key. The host key may be reused across multiple hosts to apply this job template against multiple hosts. Should you wish to control what hosts are able to request configuration, the key may be changed at any time.
To callback manually via REST, look at the callback URL in the UI, which is of the form:
http://<TOWER_SERVER_NAME>/api/v2/job_templates/1/callback/
The ‘1’ in this sample URL is the job template ID in Tower.
The request from the host must be a POST. Here is an example using curl (all on a single line):
curl -k -f -i -H 'Content-Type:application/json' -XPOST -d '{"host_config_key": "cfbaae23-81c0-47f8-9a40-44493b82f06a"}' \
https://<TOWER_SERVER_NAME>/api/v2/job_templates/1/callback/
The requesting host must be defined in your inventory for the callback to succeed. If Tower fails to locate the host either by name or IP address in one of your defined inventories, the request is denied. When running a Job Template in this way, the host initiating the playbook run against itself must be in the inventory. If the host is missing from the inventory, the Job Template will fail with a “No Hosts Matched” type error message.
Note
If your host is not in inventory and Update on Launch is set for the inventory group, Tower attempts to update cloud based inventory source before running the callback.
Successful requests result in an entry on the Jobs tab, where the results and history can be viewed.
While the callback can be accessed via REST, the suggested method of using the callback is to use one of the example scripts that ships with Tower - /usr/share/awx/request_tower_configuration.sh (Linux/UNIX) or /usr/share/awx/request_tower_configuration.ps1 (Windows). Usage is described in the source code of the file by passing the -h flag, as shown below:
./request_tower_configuration.sh -h
Usage: ./request_tower_configuration.sh <options>
Request server configuration from Ansible Tower.
OPTIONS:
-h Show this message
-s Tower server (e.g. https://tower.example.com) (required)
-k Allow insecure SSL connections and transfers
-c Host config key (required)
-t Job template ID (required)
-e Extra variables
-s Number of seconds between retries (default: 60)
This script is intelligent in that it knows how to retry commands and is therefore a more robust way to use callbacks than a simple curl request. As written, the script retries once per minute for up to ten minutes.
Note
Please note that this is an example script. You should edit this script if you need more dynamic behavior when detecting failure scenarios, as any non-200 error code may not be a transient error requiring retry.
Most likely you will use callbacks with dynamic inventory in Tower, such as pulling cloud inventory from one of the supported cloud providers. In these cases, along with setting Update On Launch, be sure to configure an inventory cache timeout for the inventory source, to avoid hammering of your Cloud’s API endpoints. Since the request_tower_configuration.sh script polls once per minute for up to ten minutes, a suggested cache invalidation time for inventory (configured on the inventory source itself) would be one or two minutes.
While we recommend against running the request_tower_configuration.sh script from a cron job, a suggested cron interval would be perhaps every 30 minutes. Repeated configuration can be easily handled by scheduling in Tower, so the primary use of callbacks by most users is to enable a base image that is bootstrapped into the latest configuration upon coming online. To do so, running at first boot is a better practice. First boot scripts are just simple init scripts that typically self-delete, so you would set up an init script that called a copy of the request_tower_configuration.sh script and make that into an autoscaling image.
16.12.1. Passing Extra Variables to Provisioning Callbacks¶
Just as you can pass extra_vars in a regular Job Template, you can also pass them to provisioning callbacks. To pass extra_vars, the data sent must be part of the body of the POST request as application/json (as the content type). Use the following JSON format as an example when adding your own extra_vars to be passed:
'{"extra_vars": {"variable1":"value1","variable2":"value2",...}}'
(Added in Ansible Tower version 2.2.0.)
You can also pass extra variables to the Job Template call using curl, such as is shown in the following example:
root@localhost:~$ curl -f -H 'Content-Type: application/json' -XPOST \
-d '{"host_config_key": "5a8ec154832b780b9bdef1061764ae5a", "extra_vars": "{\"foo\": \"bar\"}"}' \
http://<TOWER_SERVER_NAME>/api/v2/job_templates/1/callback
For more information, refer to Launching Jobs with Curl.
16.13. Extra Variables¶
Note
Additional strict extra_vars validation was added in Ansible Tower 3.0.0. extra_vars passed to the job launch API are only honored if one of the following is true:
They correspond to variables in an enabled survey
ask_variables_on_launchis set to True
When you pass survey variables, they are passed as extra variables (extra_vars) within Tower. This can be tricky, as passing extra variables to a job template (as you would do with a survey) can override other variables being passed from the inventory and project.
For example, say that you have a defined variable for an inventory for debug = true. It is entirely possible that this variable, debug = true, can be overridden in a job template survey.
To ensure that the variables you need to pass are not overridden, ensure they are included by redefining them in the survey. Keep in mind that extra variables can be defined at the inventory, group, and host levels.
Note
Beginning with Ansible Tower version 2.4, the behavior for Job Template extra variables and Survey variables has changed. Previously, variables set using a Survey overrode any extra variables specified in the Job Template. In 2.4 and later, the Job Template extra variables dictionary is merged with the Survey variables. This may result in a change of behavior upon upgrading to 2.4.
Here are some simplified examples of extra_vars in YAML and JSON formats:
The configuration in YAML format:
launch_to_orbit: true
satellites:
- sputnik
- explorer
- satcom
The configuration in JSON format:
{
"launch_to_orbit": true,
"satellites": ["sputnik", "explorer", "satcom"]
}
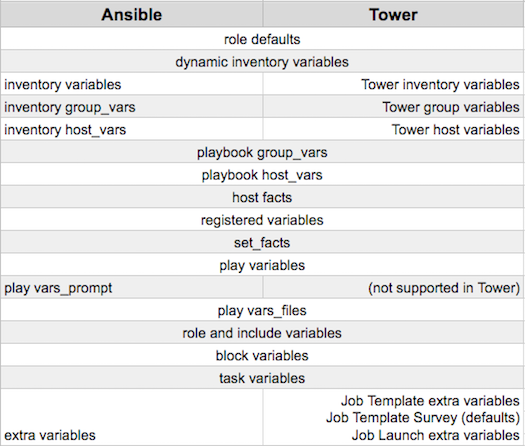
The following table notes the behavior (hierarchy) of variable precedence in Ansible Tower as it compares to variable precedence in Ansible.
Ansible Tower Variable Precedence Hierarchy (last listed wins)
16.13.1. Relaunching Job Templates¶
Another change for Ansible Tower version 2.4 introduced a launch_type setting for your jobs. Instead of manually relaunching a job, a relaunch is denoted by setting launch_type to relaunch. The relaunch behavior deviates from the launch behavior in that it does not inherit extra_vars.
Job relaunching does not go through the inherit logic. It uses the same extra_vars that were calculated for the job being relaunched.
For example, say that you launch a Job Template with no extra_vars which results in the creation of a Job called j1. Next, say that you edit the Job Template and add in some extra_vars (such as adding "{ "hello": "world" }").
Relaunching j1 results in the creation of j2, but because there is no inherit logic and j1 had no extra_vars, j2 will not have any extra_vars.
To continue upon this example, if you launched the Job Template with the extra_vars you added after the creation of j1, the relaunch job created (j3) will include the extra_vars. And relaunching j3 results in the creation of j4, which would also include extra_vars.