21. Jobs¶
job 是针对主机清单启动 Ansible playbook 的一个 Tower 实例。
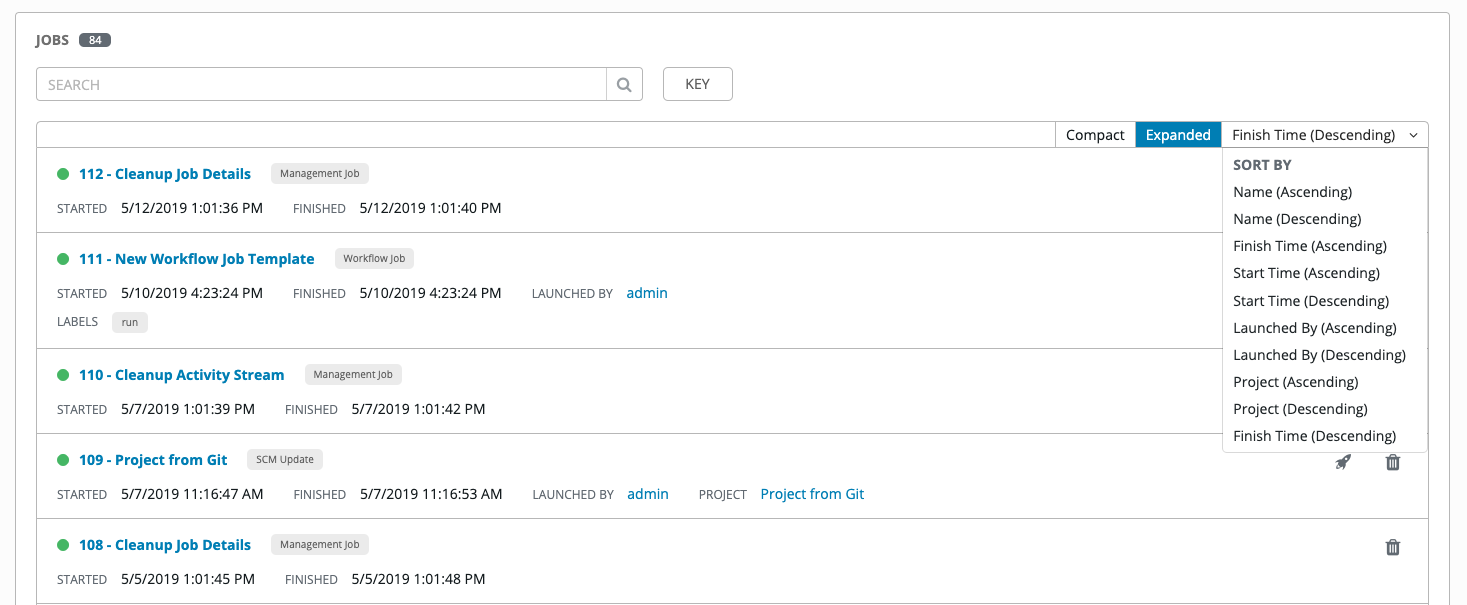
Jobs 链接显示作业列表及其状态--显示为成功完成或失败,或显示为活跃(运行中)作业。默认视图为折叠状态 (Compact),显示作业 ID、作业名称和作业类型,但您可以扩展以查看更多信息。您可以按照各种条件对列表进行排序,然后执行搜索来过滤相关的作业。
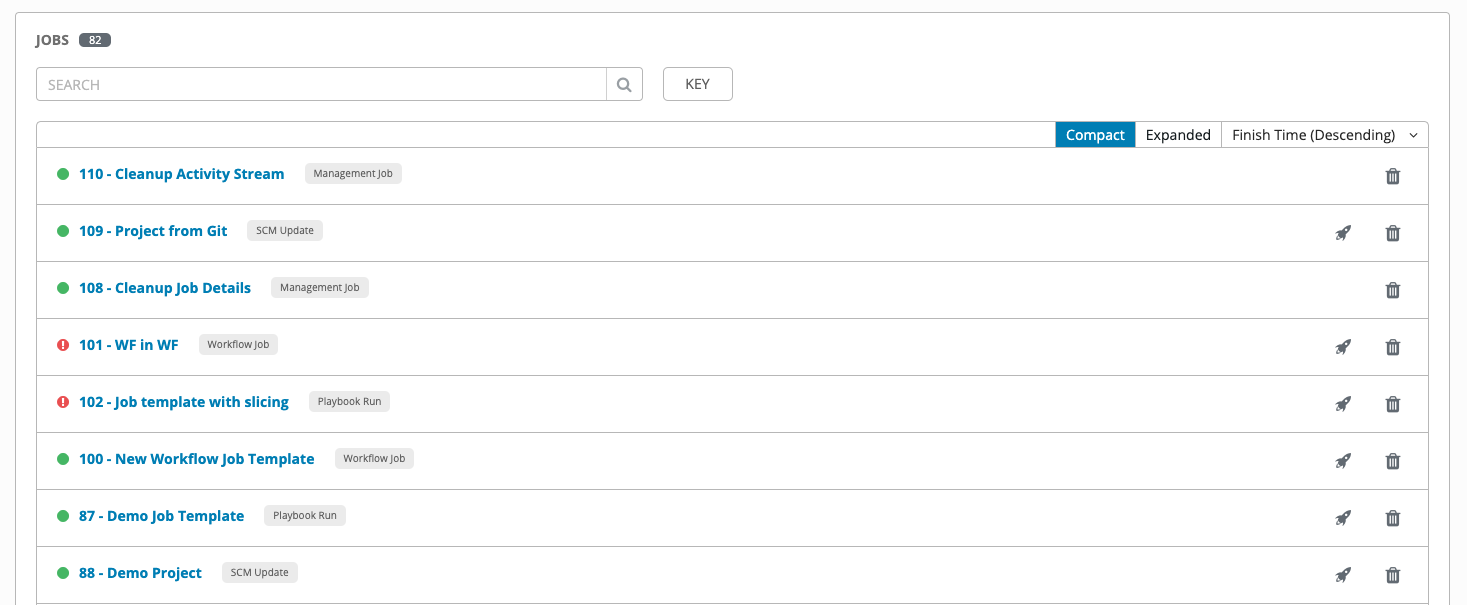
在此屏幕中,您可以执行的操作包括查看特定作业的详情和标准输出,重新启动 ( ) 作业,或删除 (
) 作业,或删除 ( ) 作业。
) 作业。
在列表视图中,您可以重新启动最新的作业。您可以对指定清单中的所有主机重新运行,即使其中部分主机已经成功运行也一样。这可让您在不必对它们再次运行 Playbook 即可重新运行作业。您也可以对所有失败的主机重新运行作业。这有助于降低 Ansible Tower 节点上的负载,因为不需要再次处理成功的主机。
重新启动操作只适用于重新启动 playbook 运行,不适用于项目/清单更新、系统作业、工作流作业等。
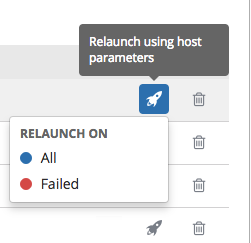
选择 All 重新启动所有主机。
选择 Failed 重新启动所有失败且不可访问的主机。
当重新启动时,您会停留在同一页面。
使用 Tower Search 功能可按照各种条件查找作业。有关使用 Tower Search 的详情,请参阅 搜索 章节。
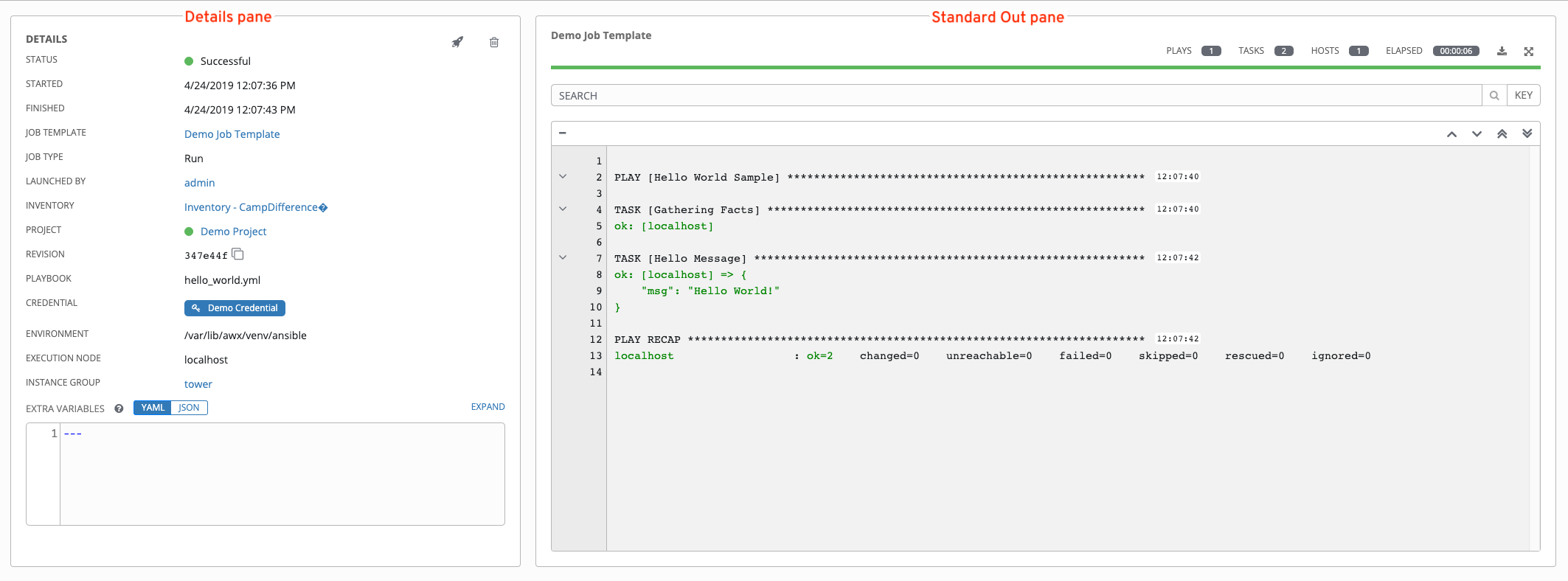
点击任何类型的作业会进入该作业的作业详情视图,该视图由以下两个部分组成:
Details 窗格提供作业的有关信息和状态
Standard Out 窗格显示作业进程和输出
21.1. 作业详情 - 清单同步¶
注解
从 Ansible Tower 3.7 开始,在一个相关作业运行时也可以进行清单更新。当您有大型项目(大约 10 GB)时,/tmp 可能出现磁盘空间的问题。
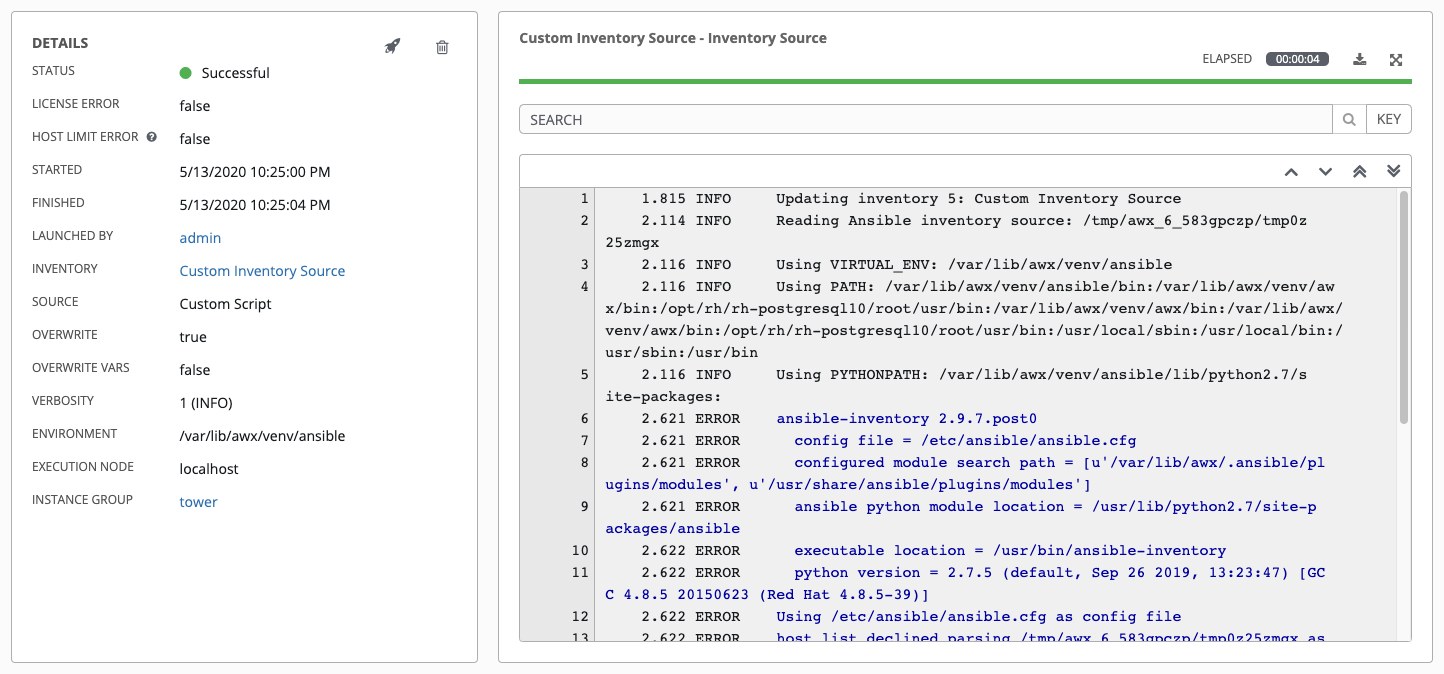
21.1.1. 详情¶
Details 窗口显示作业的基本状态及其启动时间。您可以通过 Details 窗格右上角的图标重新启动 () 或删除 () 作业。
Details 窗格还提供有关作业执行的详情:
Status:可以是以下任意一种:
Pending - 已创建清单同步但尚未排队或启动。在实际准备好由系统运行之前,任何作业(不仅仅是清单源同步)都会停留在等待状态。清单源同步未准备就绪的原因包括:依赖项当前正在运行(所有依赖项都必须已完成才能执行下一个步骤),或者其配置的位置没有足够的运行容量。
Waiting - 清单同步处于等待执行的队列中。
Running - 清单同步当前正在进行中。
Successful - 清单同步作业成功。
Failed - 清单同步作业失败。
License Error:只有 Inventory Sync 作业才会显示。如果为 True,则表示由清单同步添加的主机导致 Tower 超过了受管主机的许可证数。
Host Limit Error:代表任务的清单所属的机构已超过系统管理员定义的主机数限制。
Started:Tower 启动作业的时间戳。
Finished:作业完成的时间戳。
Launched By: 启动这个作业的用户的名称。
Inventory: 关联的清单组。
Source:云清单的类型。
Overwrite:如果为 True,以前存在于外部源上的但现已被删除的任何主机和组都将从 Tower 清单中删除。不由清单源管理的主机和组将提升到下一个手动创建的组,如果没有手动创建组来提升它们,则它们将保留在清单的“all”默认组中。如果为 False,外部源上没有的本地子主机和组将在清单更新过程中保持不变。
Overwrite Vars:如果为 True,子组和主机的所有变量都将被删除,并替换为外部源上的变量。如果为 False,就会执行合并,将本地变量与外部源上的变量合并。
Verbosity:控制 Ansible 为清单源更新任务生成的输出级别。
Environment: 使用的虚拟环境。
Execution node: 用于执行作业的节点。
Instance Group: 此作业使用的实例组的名称(tower 是默认实例组)。
通过点击这些项,您可以根据情况查看对应的作业模板、项目和其他 Tower 对象。
21.1.2. 标准输出¶
Standard Out 窗格显示运行清单同步 playbook 的完整结果。这与您通过 Ansible 命令行运行它时显示的信息相同,并可用于调试。位于 Standard Out 窗格右上角的图标可用于将输出切换为主视图 ( ) 或下载输出 (
) 或下载输出 ( )。
)。
所有 playbook 运行的 ANSIBLE_DISPLAY_ARGS_TO_STDOUT 会默认设置为 False。这与 Ansible 的默认行为匹配。这会导致 Tower 不再在作业详情界面的任务标题中显示任务参数,以避免将某些敏感模块参数泄漏到 stdout。如果您希望恢复之前的行为(虽然有安全影响),您可以通过 AWX_TASK_ENV``配置设置将 ``ANSIBLE_DISPLAY_ARGS_TO_STDOUT 设置为 True。如需了解更多信息,请参阅 ANSIBLE_DISPLAY_ARGS_TO_STDOUT。
21.2. 作业详情 - SCM¶
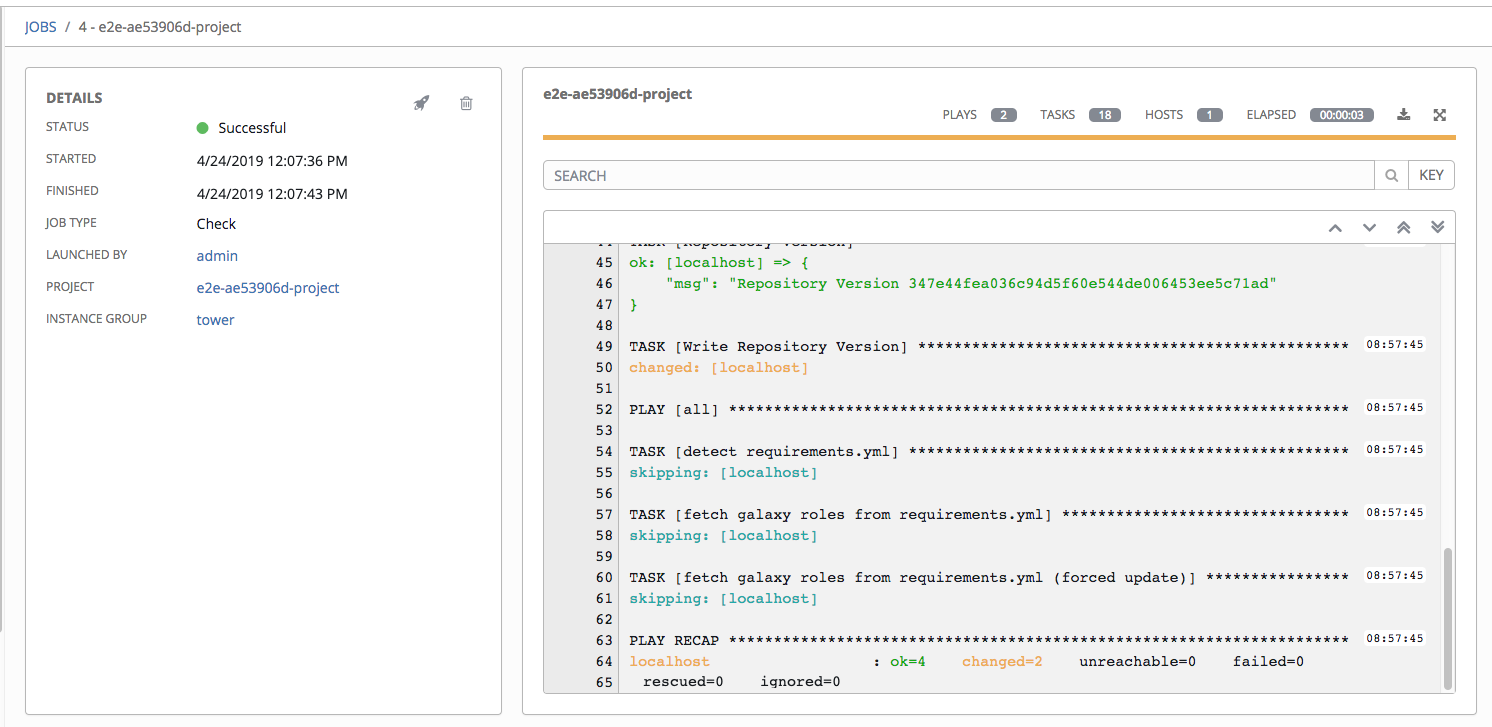
21.2.1. 详情¶
Details 窗口显示作业的基本状态及其启动时间。您可以通过 Details 窗格右上角的图标重新启动 () 或删除 () 作业。
Details 窗格提供有关作业执行的详情:
Name:关联的清单组的名称。
Status:可以是以下任意一种:
Pending - 已创建 SCM 作业但尚未排队或启动。在实际准备好由系统运行之前,任何作业(不仅仅是 SCM 作业)都会停留在等待状态。SCM 作业未准备就绪的原因包括:依赖项当前正在运行(所有依赖项都必须已完成才能执行下一个步骤),或者其配置的位置没有足够的运行容量。
Waiting - SCM 作业处于等待执行的队列中。
Running - SCM 作业当前正在进行中。
Successful - 最后的 SCM 作业成功。
Failed - 最后的 SCM 作业失败。
Started:Tower 启动作业的时间戳。
Finished:作业完成的时间戳。
Elapsed:作业所花总时间。
Launch Type:Manual 或 Scheduled。
Project:项目名称。
通过点击这些项,您可以根据情况查看对应的作业模板、项目和其他 Tower 对象。
21.2.2. 标准输出¶
Standard Out 窗格显示运行 SCM 更新的完整结果。这与您通过 Ansible 命令行运行它时显示的信息相同,并可用于调试。位于 Standard Out 窗格右上角的图标可用于将输出切换为主视图 () 或下载输出 ()。
21.3. 作业详情 - Playbook 运行¶
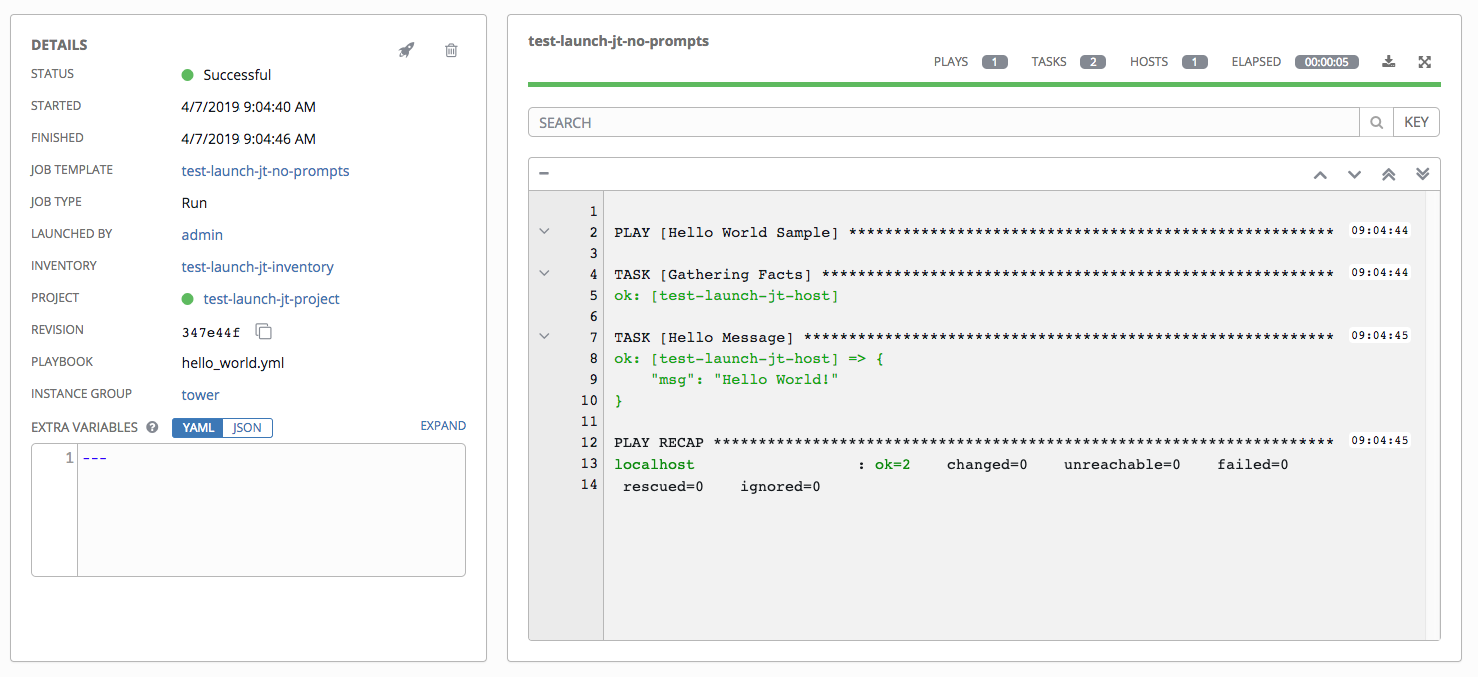
从 Job Templates 页面启动作业后,也可以访问 Playbook Run 作业的作业详情视图。
21.3.1. 详情¶
Details 窗口显示作业的基本状态及其启动时间。您可以通过 Details 窗格右上角的图标重新启动 () 或删除 () 作业。
Details 窗格提供有关作业执行的详情:
Status:可以是以下任意一种:
Pending - 已创建 playbook 运行但尚未排队或启动。在实际准备好由系统运行之前,任何作业(不仅仅是 playbook 运行)都会停留在等待状态。Playbook 运行未准备就绪的原因包括:依赖项当前正在运行(所有依赖项都必须已完成才能执行下一个步骤),或者其配置的位置没有足够的运行容量。
Waiting - playbook 运行处于等待执行的队列中。
Running - playbook 运行当前正在进行中。
Successful - 最后的 playbook 运行成功。
Failed - 最后的 playbook 运行失败。
Template:从中启动此作业的作业模板的名称。
Started:Tower 启动作业的时间戳。
Finished:作业完成的时间戳。
Elapsed:作业所花总时间。
Launch By:启动了此作业的用户、作业或调度扫描作业的名称。
Inventory:选作为此作业运行对象的清单。
Machine Credential:此作业中使用的凭证的名称。
Verbosity:创建作业模板时设置的详细程度等级。
Extra Variables:创建作业模板时传递的任何额外变量都会在此处显示。
通过点击这些项,您可以根据情况查看对应的作业模板、项目和其他 Tower 对象。
21.3.2. 标准输出窗格¶
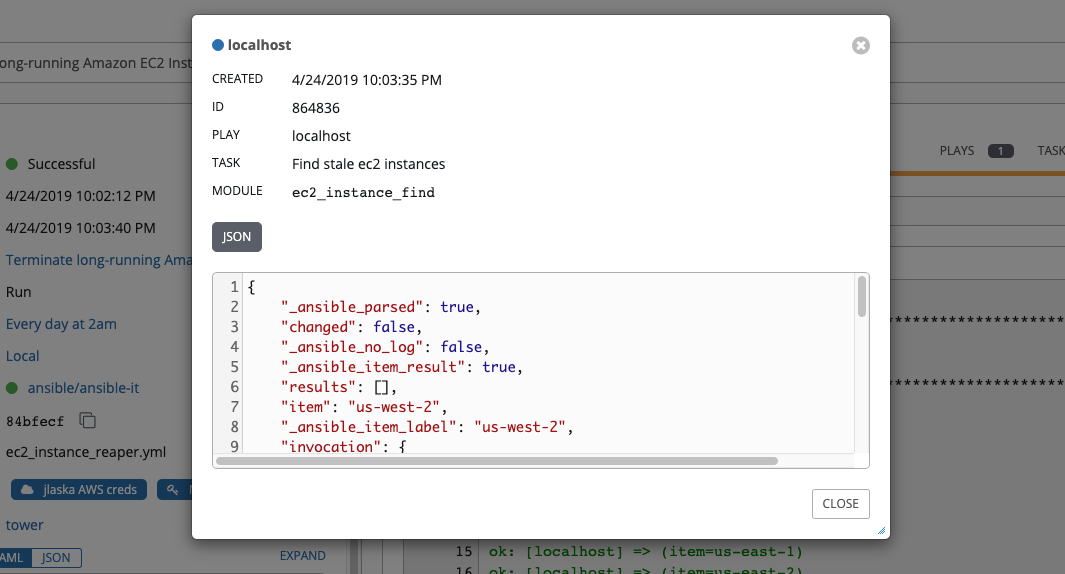
Standard Out 窗格显示运行 Ansible playbook 的完整结果。这与您通过 Ansible 命令行运行它的信息相同,并可用于调试。您可以查看事件摘要、主机状态和主机事件。在 Standard Out 窗格右上角的图标可用于将输出切换为主视图 () 或下载输出 ()。
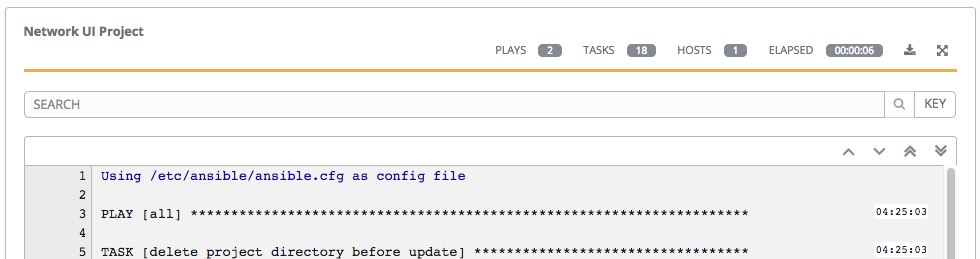

21.3.2.3. 搜索¶
使用 Tower Search 来查找特定的事件、主机名及其状态。要只过滤具有特定状态的某些主机,请指定以下状态之一:
Changed:playbook 任务已实际执行。由于 Ansible 任务应该编写成幂等的,因此任务可能在没有对主机执行任何操作的情况下成功退出。在这些情况下,任务将返回 Ok,而不是 Changed。
Failed:任务失败。在此主机上停止了进一步的 playbook 执行。
OK:playbook 任务返回“Ok”。
Unreachable:无法从网络访问主机,或者主机存在另一个与之关联的致命错误。
Skipped:跳过了 playbook 任务,因为主机不需要更改即可达到目标状态。
Rescued:在 Ansible 2.8 中引入,这显示了失败后执行 rescue 部分的任务。
Ignored:在 Ansible 2.8 中引入,这显示了已失败并配置了
ignore_errors: yes的任务。
这些状态也显示在每个 Standard Out 窗格底部名为 Host Summary 字段的一组“统计数据”中。
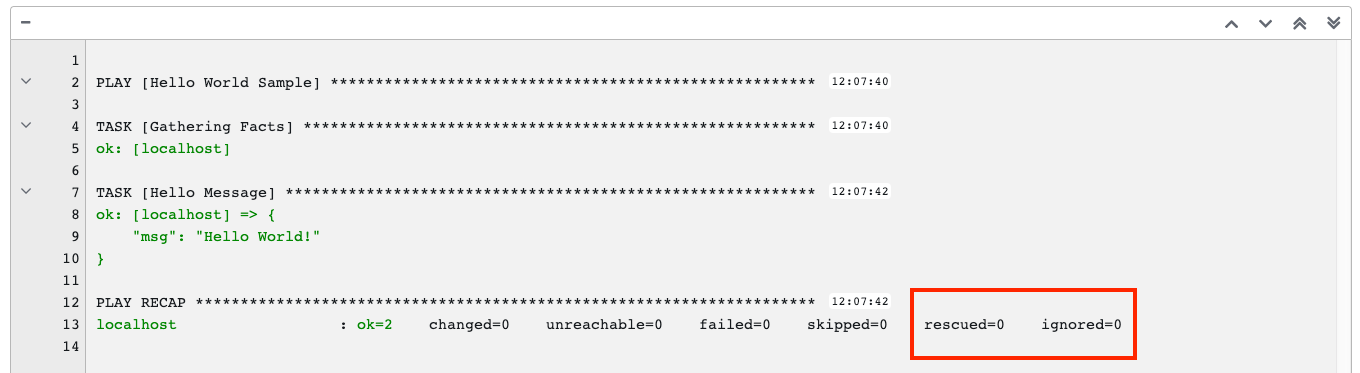
以下示例显示一个只包含失败主机的搜索。
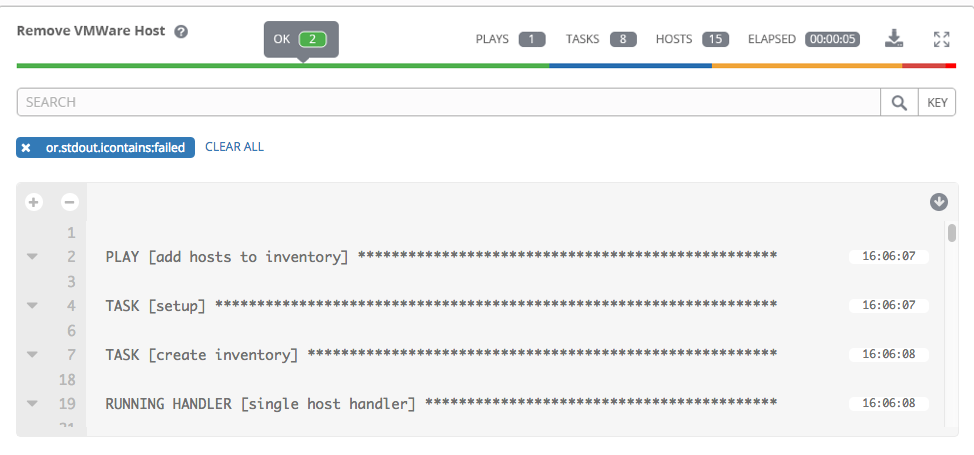
有关使用 Tower Search 的详情,请参阅 搜索 章节。
21.3.2.4. 标准输出视图¶
标准输出视图显示特定作业上发生的所有事件。默认情况下,会展开所有行,以便显示所有详情。使用折叠所有按钮 (![]() ) 切换到仅包含 play 和任务的标头的视图。单击 (
) 切换到仅包含 play 和任务的标头的视图。单击 (![]() ) 按钮查看标准输出的所有行。
) 按钮查看标准输出的所有行。
或者,也可以通过点击 play 或任务旁的箭头图标来显示特定 play 或任务的所有详情。单击侧边的箭头到下移,展开与该 play 或任务关联的行。点击箭头回到侧边位置来折叠和隐藏行。
在扩展/折叠模式中查看详情时需要注意以下事项:
每个没有折叠的显示行都有对应的行号和开始时间。
任何 play 或任务完成后,展开/折叠图标都位于此 play 或任务的开始位置。
如果查询某个特定 play 或任务,它将以折叠状态出现在其完成进程的末尾。
在有些情况下,会显示因为输出可多而无法显示的错误消息。当事件数量超过 4000 个时,会出现这种情况。使用搜索和过滤特定事件来绕过错误。
将鼠标悬停在 Standard Out 视图中的事件行上,该行上方会显示一个工具提示,提供受此任务影响的主机总数,以及一个选项,用于查看其状态细分的更多详情。
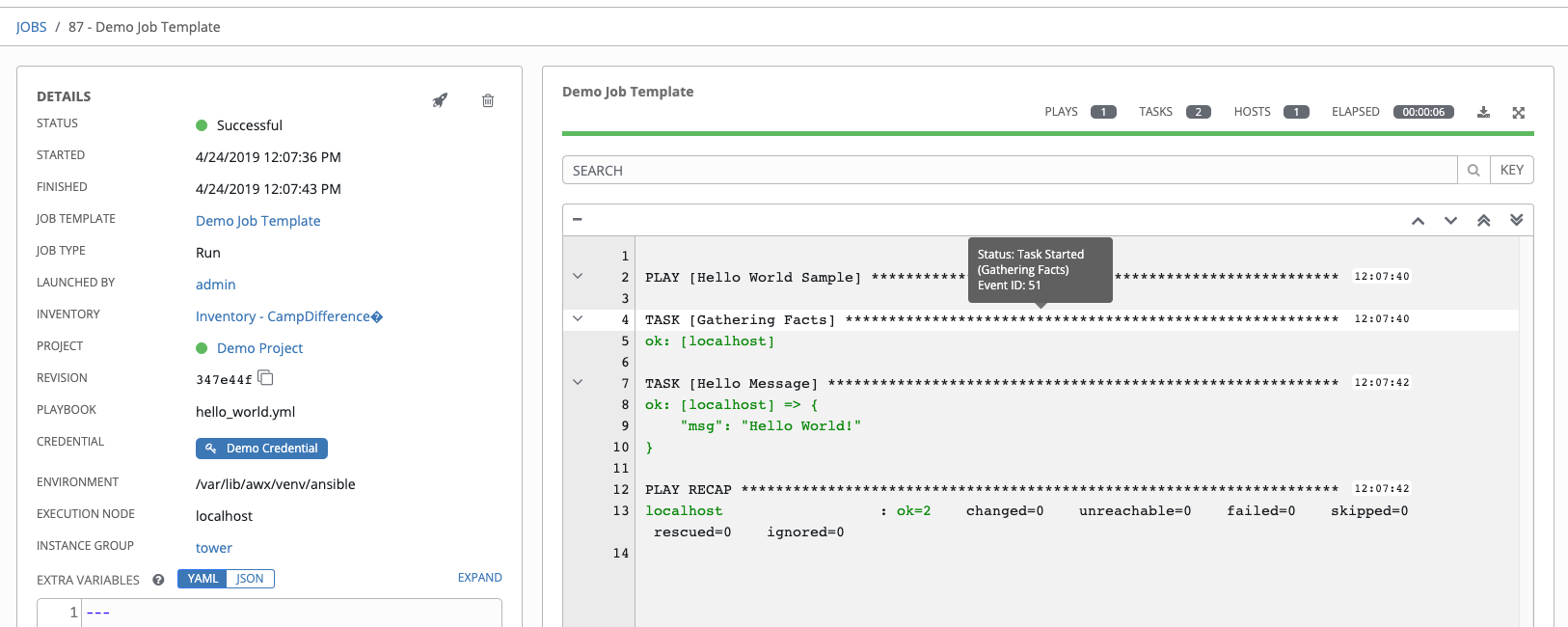
点击 Standard Out 窗格中的事件行,在单独的窗口中会显示 Host Events 对话框。此窗口显示受该特定事件影响的主机。
注解
升级到 Tower 的最新版本涉及逐渐迁移所有历史 playbook 输出和事件。这种迁移过程是分散的,并在安装完成后自动在后台进行。在迁移完全完成前,基有大量历史作业输出(几十或及百 GB 的输出)的安装可能会存在缺少作业输出的问题。大多数最新的数据都会在输出的顶部显示,然后是旧的事件。迁移具有大量事件的作业的时间可能比迁移数量小的作业的时间更长。
21.4. 决定 Ansible Tower 容量和作业的影响¶
本节论述了如何确定实例组的容量及其对您的作业的影响。如需了解容器组,请参阅 Ansible Tower Administration Guide 中的 容器容量限制。
Ansible Tower 容量系统根据实例可使用的资源量以及正在运行的作业的大小(称为*影响*)来确定可在该实例上运行的作业数量。用于确定这一点的算法完全基于两个因素:
系统可使用的内存量 (
mem_capacity)系统可使用的 CPU 量 (
cpu_capacity)
容量还会影响实例组。由于组由不同实例组成,同样实例也可以分配到多个组。这意味着对一个实例的影响可能会影响其他组的总容量。
实例组(而非实例本身)可以分配给不同级别的作业使用(请参阅 Clustering)。当任务管理器准备其图表来确定作业将在哪个组上运行时,它会将实例组的容量提交到尚未启动或尚未准备好启动的作业。
最后,在较小的配置中,如果只有一个实例可用于某个作业运行,则任务管理器将允许该作业在此实例上运行,即使它会使此实例超出容量。这样可保证作业本身不会因为系统配置不足而卡住。
因此,容量和影响不是一个相对于作业和实例/实例组的零和系统。
有关分片作业及其对容量的影响的信息,请参阅 作业分片执行行为。
21.4.1. 容量算法的资源确定¶
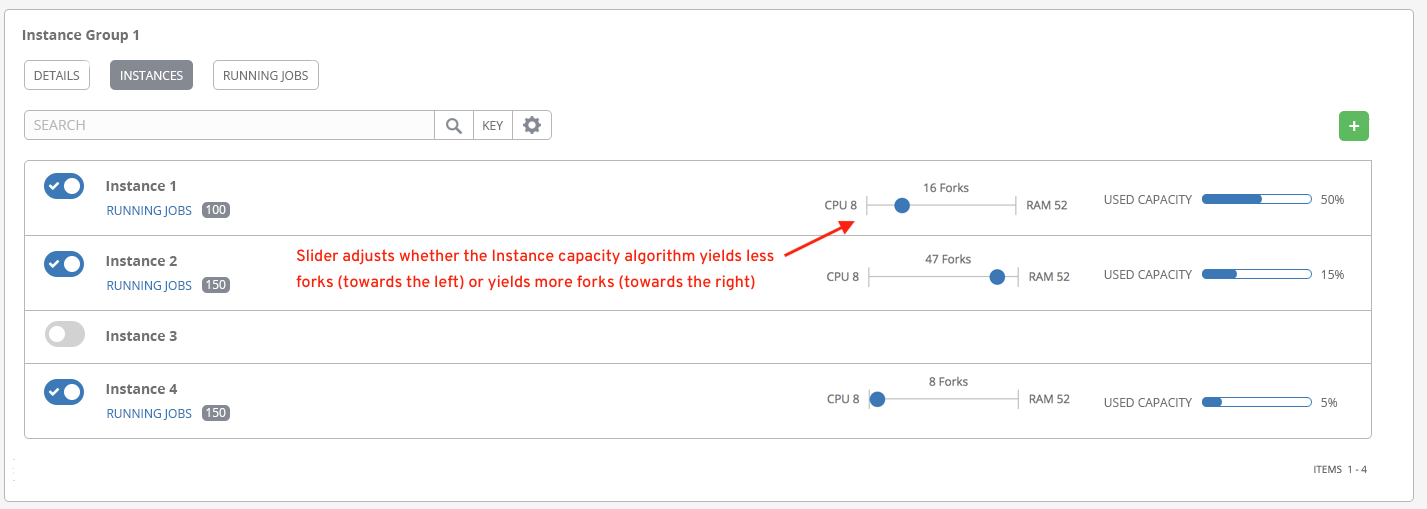
定义容量算法是为了确定系统能够同时运行多少个 fork。这决定了 Ansible 本身将同时与多少系统通信。通常,增加 Tower 系统运行的 fork 数量意味着可以并行执行更多工作,从而加快作业运行速度。这么做的代价是,这将增加系统的负载,进而可能导致工作总体上变慢。
在确定容量时,Tower 可以在两种模式下运行。通过 ``mem_capacity``(默认),您可以超额提交 CPU 资源,同时防止系统内存不足。如果您的大多数工作不是 CPU 密集型,那么选择此模式可以使 fork 数量达到最大。
21.4.1.1. 内存相对容量¶
mem_capacity 是相对于每个 fork 所需的内存量来计算的。考虑到 Tower 内部组件的开销,每个 fork 大约需要 100MB。如果考虑 Ansible 作业可用的内存量,容量算法会保留 2GB 内存,以防存在其他 Tower 服务。这种情况的算法公式为:
(mem - 2048) / mem_per_fork
例如:
(4096 - 2048) / 100 == ~20
具有 4GB 内存的系统可以运行 20 个 fork。mem_per_fork 的值可通过设置 Tower 设置值(或环境变量)``SYSTEM_TASK_FORKS_MEM`` 来控制,该值默认值为 100。
21.4.1.2. CPU 相对容量¶
通常,Ansible 工作负载为高度 CPU 密集型。在这些情况下,有时降低并发工作负载可以让更多的任务更快地运行,并减少这些作业的平均完成时间。
就像 Tower mem_capacity 算法使用每个 fork 所需的内存量一样,cpu_capacity 算法会考虑每个 fork 所需的 CPU 资源量。这种算法的基准值是每个内核的 4 fork。这种情况的算法公式为:
cpus * fork_per_cpu
例如,一个 4 核系统:
4 * 4 == 16
fork_per_cpu 的值可通过设置 Tower 设置值(或环境变量)``SYSTEM_TASK_FORKS_CPU`` 来控制,它的默认值为 4。
21.4.2. 容量作业影响¶
当选择容量时,了解每个作业类型对容量的影响很重要。
理解 fork 对 Ansible 的含义会很有帮助: https://www.ansible.com/blog/ansible-performance-tuning(请参阅"了解您的 Fork"部分)。
Ansible 的默认 fork 值为 5。但是,如果 Tower 知道您正在针对 5 个以下的系统运行,那么实际的并发值会更低。
运行作业时,Tower 会在选择的 fork 数量基础上增加 1 以补偿 Ansible 父进程。也就是说,如果您以 5 的 fork 值针对 5 个系统运行 playbook,则从作业影响角度来看,实际的 fork 值为 6。
21.4.2.1. Tower 中作业类型的影响¶
作业和临时作业遵循上述模型,即 fork + 1。如果在作业模板上设置了 fork 值,则您的作业容量值将是提供的 forks 值的最小值,加上您拥有的主机数量,再加上 1。加上 1 是为了考虑父 Ansible 进程。
实例容量决定了将哪些作业被分配给任何特定的实例。如果作业和临时命令具有更高的 fork 值,它们将使用更多容量。
其他作业类型具有固定影响:
清单更新:1
项目更新:1
系统作业:5
如果您未在作业模板上设置 fork 值,则您的作业将使用 Ansible 的默认 fork 值 5。如果您的作业只有不到五个主机,即使 Ansible 默认为五个 fork,它也将使用更少数量。通常情况下,设置一个比系统容量高的 fork 值可能导致内存不足或超额提交 CPU,进而造成麻烦。因此,您使用的作业模板 fork 值应与系统相适应。如果您拥有使用 1000 个 fork 的 playbook,但您的任何单独系统都没有如此多容量,那么您的系统容量不足,并存在发生性能或资源问题的风险。
21.4.2.2. 选择正确的容量¶
从 CPU 密集型或内存密集型的容量限制中选择容量实质上就是在最小或最大 fork 数之间进行选择。在上面的示例中,CPU 容量最多允许 16 个 fork,而内存容量最多允许 20 个 fork。对于某些系统,两者之间的差异可能很大,并且通常您可能希望在这两者之间取得平衡。
您可以通过实例字段 capacity_adjustment 选择要考虑的一种算法或另一算法的容量。它表示为 0.0 到 1.0 之间的值。如果设置为 1.0,则将使用最大值。上面的示例涉及内存容量,因此将选择 20 个 fork 的值。如果设置为 0.0,则将使用最小值。0.5 的值将在两种算法之间达到 50/50 平衡,即 18:
16 + (20 - 16) * 0.5 == 18
要在 Tower 用户界面中查看或编辑容量,请选择 Instance Group 的 Instances 标签页。
21.5. 作业分支覆盖¶
项目在 scm_branch 字段中指定要从源控制使用的分支、标签或引用。这些信息由 Project Details 字段中指定的值表示,如下所示。
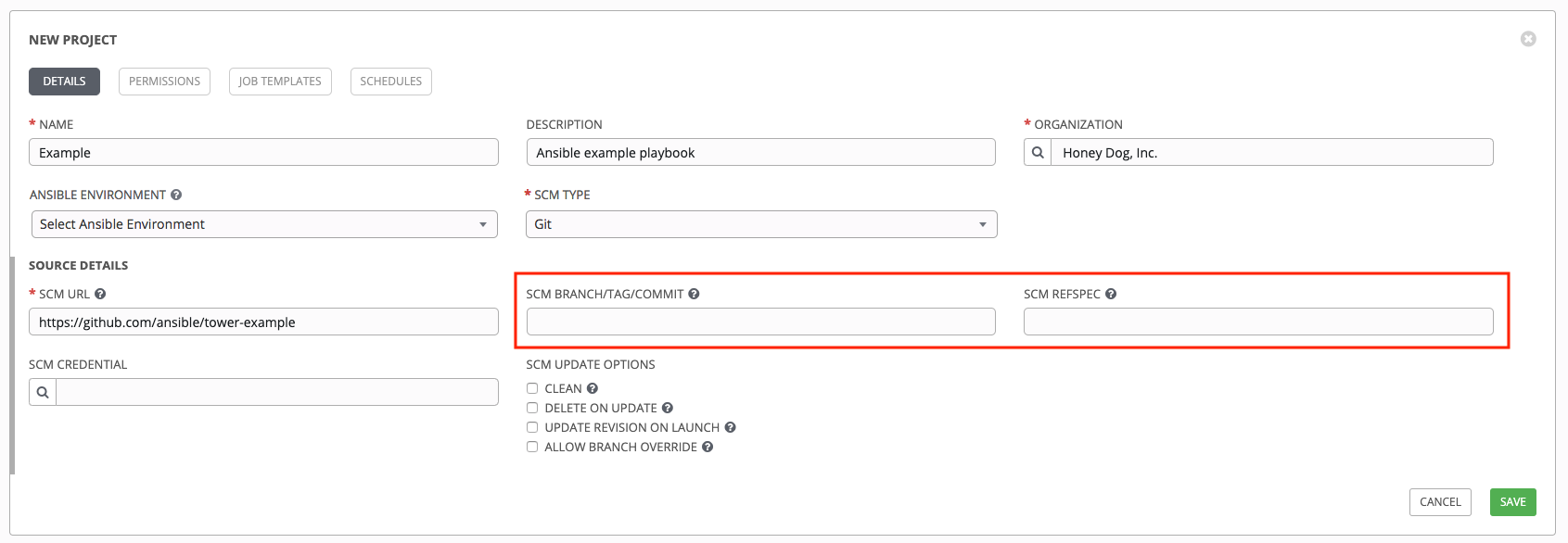
具有“Allow Branch Override”选项的项目。选中此选项时,项目管理员可以将分支选择委托给使用该项目的作业模板(只需要项目 use_role)。

作业模板的管理员可以选中作业模板的 SCM Branch 字段旁的 Prompt on Launch 复选框,进一步将该功能委托给执行作业模板的用户(只需要作业模板 execute_role)。
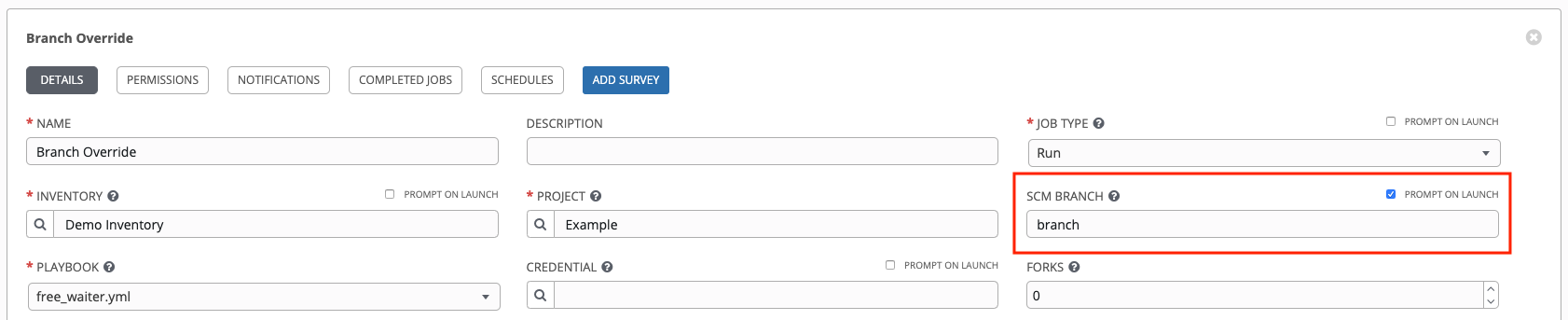
21.5.1. 源树复制行为¶
每个作业运行都有自己的专用数据目录。这个目录包含作业运行的给定 scm_branch 的项目源树副本。作业可以自由地更改项目文件夹,即使仍在运行也能利用这些更改。这个文件夹是临时的,会在作业运行结束时被清理。
如果选中 Clean,Tower 会通过在与 git、Subversion 和 Mercurial 相关的相应 Ansible 模块中使用 force 参数,将存储库的本地副本中的修改文件丢弃。

21.5.2. 项目修订行为¶
通常,在项目更新过程中,默认分支的修订(在项目的 SCM Branch 字段中指定)会在更新时进行存储,并且使用该项目的作业会利用这一修订。若在作业中提供非默认 SCM Branch**(并非提交散列或标签),则会在作业即将开始前从远程源控制拉取最新的修订。这一修订显示在作业及其相应的项目更新的 **Revision 字段中。
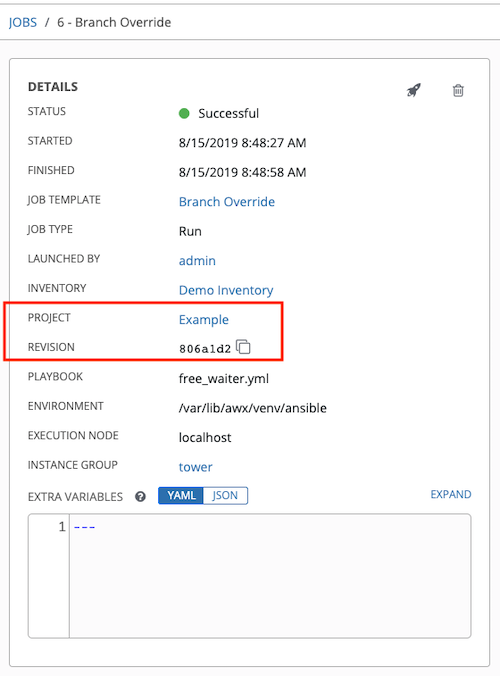
因此,非默认分支不支持离线作业运行。若要确保某个作业从源控制运行静态版本,请使用标签或提交散列。项目更新不会保存所有分支的修订,仅保存项目默认分支。
SCM Branch 字段没有经过验证,因此项目必须更新以确保其有效。如果提供或提示了此字段,则不会验证作业模板的 Playbook 字段,您必须启动作业模板以验证所需的 playbook 是否存在。
21.5.3. Git Refspec¶
SCM Refspec 字段指定更新应该从远程下载的额外引用。例如:
refs/*:refs/remotes/origin/*:获取所有引用,包括远程的 remotes
refs/pull/*:refs/remotes/origin/pull/*(GitHub-specific):获取所有拉取请求的所有引用
refs/pull/62/head:refs/remotes/origin/pull/62/head:获取那一个 GitHub 拉取请求的引用
对于大型项目,在使用此处的第 1 个或 2 个示例时,您应该考虑对性能的影响。
SCM Refspec 参数会影响项目分支的可用性,并且可以允许访问原本不可用的引用。上面的示例允许用户提供来自 SCM Branch 的拉取请求,如果没有 SCM Refspec 字段,这是不可能实现的。
Ansible git 模块默认获取 refs/heads/*。这意味着,如果 SCM Refspec 为空白,项目的分支和标签(以及其中的提交散列)可以用作 SCM 分支。SCM Refspec 字段中指定的值会影响哪些 SCM Branch 字段可用作覆盖。(任何类型的)项目更新会执行额外的 git fetch 命令从远程拉取该 refspec。
例如:您可以通过第 1 个或第 2 个 refspec 示例设置允许分支覆盖的项目 --> 在提示 SCM Branch 的作业模板中使用此项目 --> 客户端可在创建新拉取请求时启动作业模板,提供分支 pull/N/head --> 作业模板将针对提供的 GitGub 拉取请求引用运行。
如需了解更多与 Ansible git 模块相关的更多信息,请参阅 https://docs.ansible.com/ansible/latest/modules/git_module.html。