7. クラスタリング¶
クラスタリングでは、ホスト間で負荷が共有されます。各インスタンスは、UI および API アクセスのエントリーポイントとして機能します。これにより、Tower の管理者が複数のインスタンスの手前でロードバランサーを使用できるようになり、データの可視性が向上されるはずです。
注釈
負荷分散はオプションで、必要に応じて 1 つまたはすべてのインスタンスで受信することも可能です。
各インスタンスは、Tower のクラスターに参加して、ジョブの実行機能を拡張することができます。これは、ジョブの実行場所を指定するのではなく、ジョブをどこでも実行できる簡単なシステムです。また、クラスターインスタンスは異なるプール/キューにグループ化すること (インスタンスグループ) が可能です。
Tower は、OpenShift を使用するコンテナーベースのクラスターをサポートしています。つまり、これらのプラットフォームに新しい Tower インスタンスを、機能の変更や転換を行うことなくインストールできます。ただし、OpenShift のデプロイメントおよび設定 にはいくつか相違点があり、考慮が必要です。Kubernetes コンテナーを指定するインスタンスグループを作成できます。詳細は「実行環境」のセクションを参照してください。
サポート対象のオペレーティングシステム
クラスター環境の確立には、以下のオペレーティングシステムがサポートされます。
Red Hat Enterprise Linux 7 以降 (RHEL8 を推奨。RHEL 7 または Centos 7 インスタンスも可)
注釈
OpenShift での分離インスタンスと Ansible Tower の実行の組み合わせはサポートされません。
7.1. 設定の留意事項¶
本セクションは、クラスターの初期設定のみを対象とします。既存のクラスターのアップグレードについては、『Ansible Tower Upgrade and Migration Guide』の「Upgrade Planning」を参照してください。
新規クラスタリング環境における重要な留意事項:
PostgreSQL はまだスタンドアロンのインスタンスで、クラスター化されていません。Tower はレプリカ設定やデータベースのフェイルオーバーを管理しません (ユーザーが待機レプリカを設定した場合)。
クラスターを起動する場合は、データベースノードをスタンドアロン構成にすることとし、PostgreSQL は Tower ノードの 1 つにインストールしないでください。
クラスターでサポートされるインスタンスの最大数は 20 です。
全インスタンスは、他のすべてのインスタンスから到達でき、データベースにアクセスできる必要があります。ホストに安定したアドレスおよび/またはホスト名を指定することも重要です (Tower ホストの設定方法により異なる)。
全インスタンスは、地理的に近い場所に配置する必要があります。インスタンス間はレイテンシーが低く信頼性のある接続を使用します。
クラスター環境にアップグレードするには、プライマリーのインスタンスがインベントリーの
towerグループに所属し、さらにtowerグループの最初のホストとしてリストされる必要があります。手動のプロジェクトでは、顧客が手動で全インスタンスを同期して、一度に全インスタンスを更新する必要があります。
新しい Tower システムにはプライマリー/セカンダリーのコンセプトはありません。システムはすべてプライマリーです。
Tower デプロイメントの
inventoryファイルは保存/永続化する必要があります。新規インスタンスをプロビジョニングする場合は、パスワード、設定オプション、ホスト名をインストーラーで利用できるようにしなければなりません。
7.2. インストールおよび設定¶
新規インスタンスのプロビジョニングは、inventory ファイルを更新して、設定 Playbook を再実行します。この inventory ファイルには、クラスターのインストール時に使用するすべてのパスワードと情報が含まれていることが重要です。含まれていない場合には、他のインスタンスが再設定される場合があります。inventory ファイルインベントリーには、単一のインベントリーグループ tower が含まれています。
注釈
インスタンスはすべて、ジョブの起動先や Playbook イベントの処理、定期的なクリーンアップなど、タスクのスケジュールに関連するハウスキーピングタスクを担当します。
[tower]
hostA
hostB
hostC
[instance_group_east]
hostB
hostC
[instance_group_west]
hostC
hostD
注釈
リソースにグループが選択されていない場合には、tower グループが使用されますが、他のグループが選択されている場合は tower グループは使用されません。
database グループは、外部の PostgreSQL を指定します。データベースホストが別にプロビジョニングされる場合には、このグループは空にしておく必要があります。
[tower]
hostA
hostB
hostC
[database]
hostDB
Playbook がクラスター内の個別の Tower インスタンスで実行すると、その Playbook の出力は、Tower の websocket ベースのストリーミング出力機能の一部として他のすべてのノードにブロードキャストされます。インベントリー内の各ノードにプライベートルーティング可能アドレスを指定して、内部アドレスを使用してこのデータブロードキャストを処理するのが最適です。
[tower] hostA routable_hostname=10.1.0.2 hostB routable_hostname=10.1.0.3 hostC routable_hostname=10.1.0.4
注釈
Ansible Tower の以前のバージョンでは、変数名 rabbitmq_host を使用していました。以前のバージョンの Tower からアップグレードし、インベントリーに rabbitmq_host を指定している場合は、アップグレードの前に、名前を rabbitmq_host から routable_hostname に変更してください。
7.2.1. Tower が使用するインスタンスおよびポート¶
Tower が使用するポートとインスタンスは以下のとおりです。
80、443 (通常の Tower ポート)
22 (ssh - 入力のみが必要)
5432 (データベースインスタンス: データベースが外部インスタンスにインストールされた場合は、Tower インスタンスに対してこのポートを開放する必要があります。)
7.2.2. オプションの SSH 認証¶
(外部で管理するパスワードなしの SSH 鍵など) Tower 以外のシステムを介して、「コントローラー」ノードから「分離ノード」への SSH 認証を管理する場合は、プロビジョニング解除コマンド awx-manage remove_isolated_key を実行することで、この動作を無効にできます。
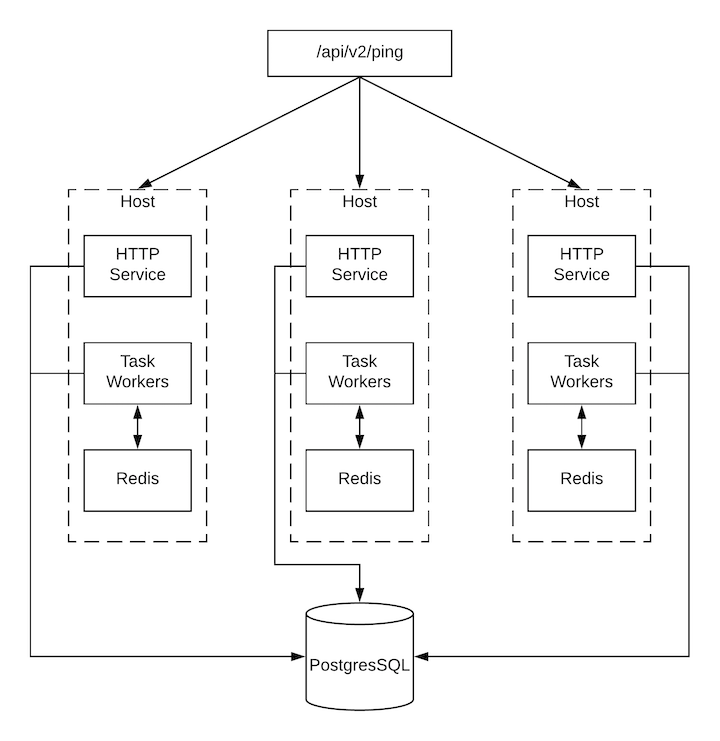
7.3. ブラウザーの API を使用したステータスの確認およびモニタリング¶
Tower は、/api/v2/ping で、クラスターのヘルスを検証するために Browsable API を使用してステータスをできるだけレポートします。以下に例を示します。
HTTP 要求にサービスを提供するインスタンス
クラスター内にある他の全インスタンスが出した最後のハートビートのタイムスタンプ
これらのグループのインスタンスグループおよびインスタンスのメンバーシップ
実行中のジョブやメンバー情報など、インスタンスおよびインスタンスグループに関する詳細情報は、/api/v2/instances/ および /api/v2/instance_groups/ を参照してください。
7.4. インスタンスサービスおよび障害時の動作¶
各 Tower インスタンスは、複数の異なるサービスで構成されており、これらのサービスは連携しています。
HTTP サービス: これには、Tower アプリケーション自体と外部の Web サービスが含まれます。
Callback Receiver: 実行中の Ansible ジョブからジョブイベントを受信します。
ディスパッチャー: 全ジョブを処理して実行するワーカーキュー
Redis: このキー値ストアは、ansible-playbook からアプリケーションに伝搬されるイベントデータのキューとして使用されます。
Rsyslog: ログをさまざまな外部ロギングサービスに配信するために使用されるログ処理サービス。
サービスやコンポーネントに障害が発生すると、全サービスが再起動されるように Tower は構成されています。サービスやコンポーネントが短期間で何度も機能しなくなった場合には、予期せぬ動作を起こさずに修正できるように自動的に全インスタンスがオフラインに切り替えられます。
クラスター環境のバックアップおよび復元については、「クラスター環境のバックアップおよび復元」のセクションを参照してください。
7.5. ジョブランタイムの動作¶
ジョブの実行や、Tower の「通常」ユーザーへレポートする方法は変更されません。システム側には、注目すべき相違点が複数あります。
ジョブが API インターフェースから送信されると、ディスパッチャーキューにプッシュされます。各 Tower インスタンスは特定のスケジュールアルゴリズムを使用してキューに接続し、そのキューからジョブを受信します。クラスター内のいずれのインスタンスも、同じ確率でジョブを受信してタスクを実行します。ジョブの実行時にインスタンスが失敗すると、ジョブは永続的に「失敗」とマークされます。
プロジェクトの更新は、ジョブを実行する可能性のあるすべてのインスタンスで正常に実行されます。プロジェクトは、ジョブを実行する直前に、インスタンス上の正しいバージョンに自分自身を同期します。必要なリビジョンがすでにローカルでチェックアウトされており、Galaxy またはコレクションの更新が不要な場合、同期は実行されない可能性があります。
同期が行われると、
launch_type = syncとjob_type = runのプロジェクトの更新として記録されます。プロジェクトの同期によってステータスやプロジェクトのバージョンが変更されることはありません。代わりに、プロジェクトが実行されているインスタンスのソースツリー*のみ*が更新されます。Galaxy またはコレクションから更新が必要な場合は、必要なロールをダウンロードし、/tmp ファイルでより多くの領域を消費する同期が実行されます。大規模なプロジェクト (約 10 GB) があると、
/tmpのディスク容量が問題になる可能性があります。
7.5.1. ジョブの実行¶
デフォルトでは、ジョブが Tower のキューに送信されると、どのワーカーでもジョブを取得できます。ただし、ジョブの実行元となるインスタンスを制限するなど、特定のジョブを実行する場所を制御できます。
一時的にインスタンスをオフラインにするため、インスタンスごとにプロパティーを有効に定義します。このプロパティーが無効の場合は、対象のインスタンスにジョブは割り当てられません。既存のジョブが完了しますが、新しいジョブは割り当てられません。
7.6. インスタンスのプロビジョニング解除¶
Playbook の設定を再実行しても、自動的にインスタンスのプロビジョニングが解除されるわけではありません。これは現在、インスタンスがオフラインになった理由が意図的なのか、障害が原因なのかをクラスターでは識別できないためです。代わりに、Tower インスタンスの全サービスをシャットダウンしてから、他のインスタンスからプロビジョニング解除ツールを実行します。
ansible-tower-service stopのコマンドで、インスタンスをシャットダウンするか、サービスを停止します。別のノードから
$ awx-manage deprovision_instance --hostname=<name used in inventory file>のプロビジョニング解除のコマンドを実行して、Tower のクラスターから削除します。例:
awx-manage deprovision_instance --hostname=hostB
同様に、Tower でインスタンスグループのプロビジョニングを解除しても、インスタンスグループは自動的にプロビジョニング解除されたり、削除されたりしません。詳細は、「インスタンスグループのプロビジョニング解除」のセクションを参照してください。