9. 実行環境¶
Tower を使用すると、クラスターのメンバーまたは事前にプロビジョニングされた分離ノードで直接実行可能な Ansible Playbook を介してジョブを実行できます。Ansible Tower 3.8 では、必要に応じて Playbook ごとにコンテナーグループでジョブを実行できます。詳細については、このセクションに後述されている「コンテナーグループ」を参照してください。
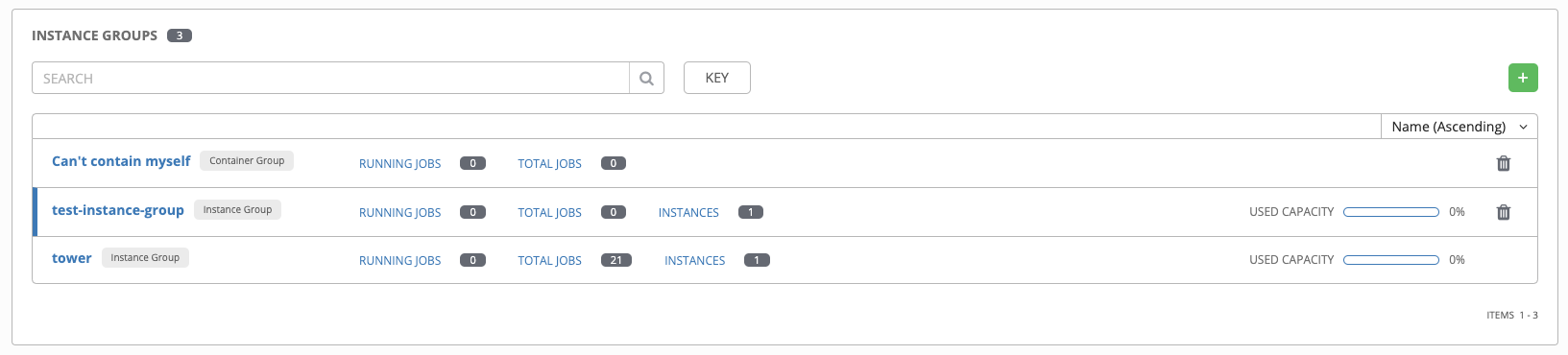
9.1. インスタンスグループ¶
インスタンスは、1 つまたは複数のインスタンスグループにグループ化することができます。インスタンスグループは、以下に記載のリソース 1 つまたは複数に割り当てることができます。
組織
インベントリー
ジョブテンプレート
リソースの 1 つに関連付けられているジョブが実行されると、そのリソースに関連付けられているインスタンスグループに割り当てられます。実行プロセス中に、インベントリーに関連付けられたインスタンスグループではなく、ジョブテンプレートに関連付けられたインスタンスグループが先に確認されます。同様に、インベントリーに関連付けられているインスタンスグループは、組織に関連付けられているインスタンスグループよりも先に確認されます。そのため、3 つのリソースのインスタンスグループの割り当てには、Job Template > Inventory > Organization の階層が形成されます。
インスタンスグループの使用時に考慮すべき事項を複数、以下に示します。
オプションで、これらのグループで他のグループやグループインスタンスを定義することができます。これらのグループには、
instance_group_のプレフィックスを指定する必要があります。インスタンスは、instance_group_グループ以外に Tower のグループに所属する必要はありませんが、towerグループには1 つインスタンスが存在している 必要があります。技術的には、towerは他のinstance_group_グループと同様ですが、常に存在させておく必要があります。特定のグループが特定のリソースに関連付けられていない場合には、ジョブ実行は常にtowerグループにフォールバックします。towerのインスタンスグループは常に存在します (削除したり、名前を変更したりできません)。名前が
instance_group_towerのグループは作成しないでください。インスタンスにグループ名と同じ名前を指定しないでください。
9.1.1. API からのインスタンスグループの設定¶
インスタンスグループは、システム管理者として /api/v2/instance_groups に POST 要求を出すことで作成できます。
インスタンスグループを作成したら、インスタンスをインスタンスグループに関連付けることができます。
HTTP POST /api/v2/instance_groups/x/instances/ {'id': y}`
インスタンスグループに追加したインスタンスは、自動的にグループの作業キューをリッスンするように再設定されます。詳細は、以下の「インスタンスグループのポリシー」セクションを参照してください。
9.1.2. インスタンスグループのポリシー¶
policy を定義することにより、オンラインになると自動的にインスタンスグループに参加するように Tower インスタンスを設定できます。これらのポリシーは、新しいインスタンスがオンラインになるたびに評価されます。
インスタンスグループポリシーは、Instance Group の 3 つの任意フィールドにより制御されます。
policy_instance_percentage: これは、0 - 100 の間の数字で指定します。これにより、確実に、アクティブな Tower インスタンスの割合が対象のインスタンスグループに追加されるようになります。新しいインスタンスがオンラインになると、このグループのインスタンス数が、インスタンスの全体数に対して、指定の割合より少ない場合には、指定の割合の条件を満たすまで、新しいインスタンスが追加されます。policy_instance_minimum: このポリシーは、インスタンスグループに配置するように試行する最小インスタンス数を指定します。利用可能なインスタンス数がこの最小数よりも少ない場合には、すべてのインスタンスがこのインスタンスグループに配置されます。policy_instance_list: これは、このインスタンスグループに常に含めるインスタンス名の固定一覧です。
Ansible Tower ユーザーインターフェースのインスタンスグループ一覧ビューでは、インスタンスグループのポリシーをもとにした各インスタンスグループのキャパシティーレベルの概要がわかります。
9.1.3. 主なポリシーの考慮事項¶
policy_instance_percentageおよびpolicy_instance_minimumはいずれも、最小割り当てレベルを指定します。このグループに割り当てる数が多いルールが適用されます。たとえば、policy_instance_percentageが 50%、policy_instance_minimumが 2 の場合に、6 台のインスタンスを起動すると、3 台がこのインスタンスグループに割り当てられます。クラスター内のインスタンス総数を 2 に減らすと、policy_instance_minimumの条件を満たすために、この 2 台のインスタンスがいずれも、インスタンスグループに割り当てられます。こうすることで、利用可能なリソースの制限に合わせて、低い値を設定できます。ポリシーは、自発的にインスタンスが複数のインスタンスグループに割り当てられないように規制するわけではありませんが、割合を合計すると 100 になるように指定すると実質的に、複数のインスタンスグループに割り当てないようにできます。インスタンスグループが 4 つあり、割合の値が 25 に割り当てると、インスタンスは重複することなく分散されます。
9.1.4. 固有のグループへのインスタンスの手動固定¶
インスタンスが特別で、特定のインスタンスグループだけに割り当てる必要があり、「percentage」または「minimum」のポリシーで他のグループに自動的に参加させない場合には、以下を行います。
インスタンスを 1 つまたは複数のインスタンスグループの
policy_instance_listに追加します。インスタンスの
managed_by_policyプロパティーをFalseに更新します。
こうすることで、割合や最小ポリシーをもとに、インスタンスが他のグループに自動的に追加されないようにします。手動で割り当てたグループにのみ所属するようになります。
HTTP PATCH /api/v2/instance_groups/N/
{
"policy_instance_list": ["special-instance"]
}
HTTP PATCH /api/v2/instances/X/
{
"managed_by_policy": False
}
9.1.5. ジョブランタイムの動作¶
インスタンスグループに関連付けられたジョブを実行する場合は、以下の動作に注意してください。
クラスターを複数のインスタンスグループに分類する場合は、クラスター全体の動作と類似します。インスタンス 2 台がグループに割り当てられると、同じグループ内の他のインスタンスと同様に、いずれかのインスタンスがジョブを受信する可能性が高いです。
Tower インスタンスがオンラインになると、Tower システムの作業容量が効率的に拡張されます。これらのインスタンスがインスタンスグループにも配置されている場合には、グループの容量も拡張されます。複数のグループの所属するインスタンスが作業を実行する場合は、所属する全グループから容量が減少します。インスタンスのプロビジョニングを解除すると、インスタンスの割当先のクラスターから容量がなくなります。詳細については「インスタンスのプロビジョニング解除」のセクションを参照してください。
注釈
すべてのインスタンスを同じ容量でプロビジョニングする必要はありません。
9.1.6. ジョブ実行場所の制御¶
ジョブテンプレート、インベントリー、または組織にインスタンスグループが割り当てられている場合には、対象のジョブテンプレートから実行されたジョブはデフォルトの動作を実行する資格はありません。つまり、これら 3 つのリソースに関連付けられたインスタンスグループに所属する全インスタンスに十分な容量がない場合には、容量が使用可能になるまでジョブは保留状態のままになります。
ジョブの送信先のインスタンスグループを決定する場合の優先順位は、以下のとおりです。
ジョブテンプレート
インベントリー
組織 (プロジェクトの形式)
インスタンスグループがジョブテンプレートと関連付けられており、いずれも許容容量内である場合には、ジョブはインベントリーで指定したインスタンスグループ、次に組織で指定したインスタンスグループに送信されます。リソースがあるので、ジョブはこれらのグループ内で、任意の順番で実行してください。
グローバルの tower グループは、Playbook で定義されるカスタムのインスタンスグループと同様に、リソースと関連付けることができます。これは、ジョブテンプレートやインベントリーに希望のインスタンスグループを指定するのに使用できますが、容量が足りない場合にはジョブは別のインスタンスに送信できます。
たとえば、ジョブテンプレートと group_a を関連付けたり、インベントリーと tower``グループを関連付けたりすることで、``group_a の容量が足りなくなると、 tower グループをフォールバックとして使用できるようになります。
さらに、インスタンスグループにリソースを関連付けずに、フォールバックとして別のリソースを指定することができます。たとえば、ジョブテンプレートにインスタンスグループを割り当てずに、インベントリーや組織のインスタンスグループにフォールバックするように設定できます。
この設定には、優れたユースケースが他に 2 つあります。
(ジョブテンプレートをインスタンスグループに割り当てずに) インスタンスグループにインベントリーを関連付けることで、特定のインベントリーに対して実行される Playbook が関連付けられたグループでのみ実行されるようにすることができます。これらのインスタンスのみが管理ノードに直接関連付けられている場合に非常に便利です。
管理者は、インスタンスグループに組織を割り当てることができます。これにより、管理者はインフラストラクチャー全体をセグメントに分け、各組織が他の組織のジョブ実行機能を妨げずに、ジョブを実行できるように保証します。
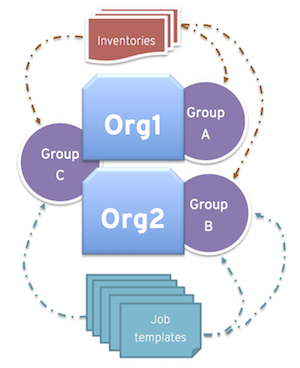
同様に、以下のシナリオのように、管理者は希望に合わせて複数のグループを各組織に割り当てることもできます。
A、B、C の 3 つのインスタンスグループがあり、Org1 および Org2 の 2 つの組織がある場合
管理者が Org1 にグループ A を、Org2 にグループ B を、容量が余分に必要となる可能性があるのでオーバーフロー用として Org1 および Org2 両方にグループ C を割り当てる場合
組織の管理者が自由にインベントリーまたはジョブテンプレートを希望のグループに割り当てる (か、組織からのデフォルトの順番を継承する) 場合
このような方法でリソースを割り当てると柔軟性が高くなります。また、インスタンスが 1 つしか含まれないインスタンスグループを作成することができるので、Tower クラスターの固有のホストに作業を割り当てることができるようになります。
9.1.7. インスタンスグループのプロビジョニング解除¶
Playbook の設定を再実行しても、自動的にインスタンスのプロビジョニングが解除されるわけではありません。これは現在、インスタンスがオフラインになった理由が意図的なのか、障害が原因なのかをクラスターでは識別できないためです。代わりに、Tower インスタンスの全サービスをシャットダウンしてから、他のインスタンスからプロビジョニング解除ツールを実行します。
ansible-tower-service stopのコマンドで、インスタンスをシャットダウンするか、サービスを停止します。別のノードから
$ awx-manage deprovision_instance --hostname=<name used in inventory file>のプロビジョニング解除のコマンドを実行して、Tower のクラスターレジストリーから削除します。例:
awx-manage deprovision_instance --hostname=hostB
同様に、再プロビジョニングの際には通常、Tower のインスタンスグループが使用されないにも拘らず、Tower のインスタンスグループのプロビジョニングを解除しても、インスタンスグループが自動的に削除されたり、プロビジョニングが解除されたりしません。そのまま API エンドポイントに表示されたり、統計が監視されたりする可能性があります。これらのグループは、以下のコマンドを使用すると、削除することができます。
例:
awx-manage unregister_queue --queuename=<name>
このインベントリーファイルのインスタンスグループから、インスタンスのメンバーシップを削除して、Playbook の設定を再実行しても、インスタンスがグループに再度追加されなくなるわけではありません。インスタンスがグループに追加されないようにするには、API 経由で削除し、インベントリーファイルからも削除するか、インベントリーファイルでインスタンスグループの定義をなくします。Ansible Tower ユーザーインターフェースでインスタンスグループのトポロジーを管理することも可能です。UI でのインスタンスグループの管理に関する詳細は、『Ansible Tower User Guide』の「Instance Groups」を参照してください。
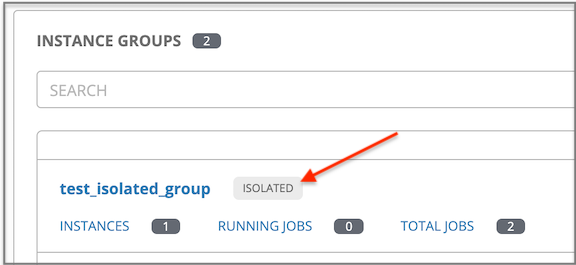
9.1.8. 分離インスタンスグループ¶
Tower には、オプションでセキュリティーの制限があるネットワークゾーン内に分離グループを定義して、そのゾーンからジョブやアドホックのコマンドを実行する機能があります。これらのグループ内のインスタンスには、Tower のシステム環境は完全ではなく、ジョブ実行に使用するユーティリティーが最小限となっています。分離グループは、プレフィックスが isolated_group_ のインベントリーファイルに指定する必要があります。以下は、分離インスタンスグループのインベントリーファイルの例です。
[tower]
towerA
towerB
towerC
[instance_group_security]
towerB
towerC
[isolated_group_govcloud]
isolatedA
isolatedB
[isolated_group_govcloud:vars]
controller=security
分離グループモデルでは、「コントローラー」インスタンスは、SSH 経由で一連の Ansible Playbook を使用して「分離」インスタンスと対話します。インストール時には、デフォルトで RSA 鍵が無作為に作成され、認証キーとしてすべての「分離」インスタンスに配布されます。その鍵に対応する秘密鍵は暗号化され、Tower データベースに保存されます。この鍵はジョブの実行時に、「コントローラー」インスタンスから「分離」インスタンスへの認証を行う際に使用します。
ジョブが「分離」インスタンスで実行されるように予定されている場合:
「コントローラー」インスタンスは、ジョブの実行に必要なメタデータをコンパイルし、「分離」インスタンスにコピーします。
メタデータが、分離ホストに同期されたら、「コントローラー」インスタンスは「分離」インスタンスでプロセスを開始し、メタデータを使って
ansible/ansible-playbookの実行を開始します。Playbook が実行されると、(標準出力やジョブインベントなど) ジョブのアーティファクトが「分離」インスタンスのディスクに書き込まれます。ジョブが「分離」インスタンスで実行されると、「コントローラー」インスタンスは「分離」インスタンスから定期的に (標準出力やジョブイベントなど) ジョブのアーティファクトをコピーし、「分離」インスタンスでジョブが完了するまで、ジョブのアーティファクトを使用します。
注釈
分離して実行中にオフラインになると、コントローラーノードは失敗します。Tower ノードが再起動するか、ディスパッチャーが Playbook の実行中に停止すると、対象のノードで実行中のジョブが失敗し、ディスパッチャーがオンラインになっても起動しません。
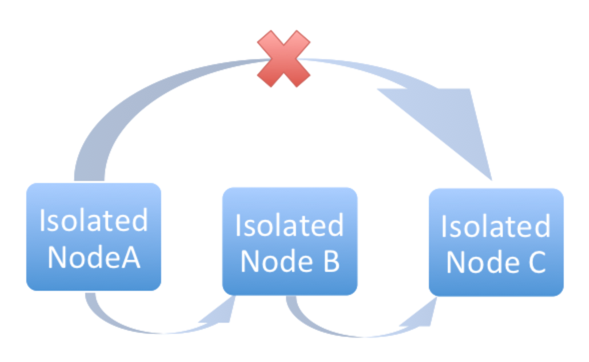
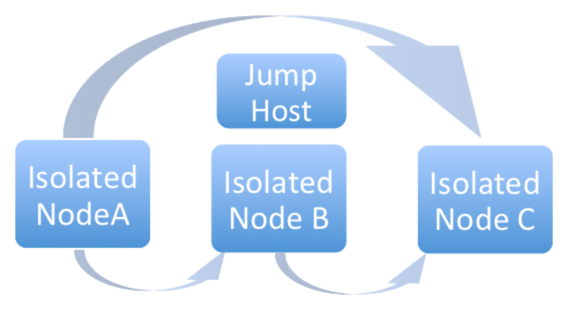
分離グループ (ノード) は、コントローラーグループに所属するインスタンスだけのアクセスを許可するセキュリティールールを持つ VPC の内部でのみ存在できるように作成されます。「コントローラー」インスタンスから「分離」インスタンスへの SSH 経由の受信トラフィックのみが必要です。分離ノードをプロビジョニングする場合は、インストールマシンは分離ノードに接続できる必要があります。分離ノードに直接アクセスできないが、他のホスト経由で間接的に到達できる場合には、SSH 設定で ProxyCommand を使用して「ジャンプホスト」を指定して、インストーラーを実行してください。
分離グループの推奨のシステム設定は以下のとおりです。
名前が
isolated_group_towerのグループは作成しないでください。Tower グループや他の一般的なインスタンスグループに分離インスタンスを配置しないでください。
コントローラー変数を分離グループの全インスタンスのグループ変数またはホスト変数として定義します。この変数については、同じグループ内にある分離インスタンスに異なる値を割り当てられないようにしてください。割り当ててしまうと、予期せぬ動作が発生する可能性があります。
複数の分離グループに分離インスタンスを配置しないでください。
通常のグループや分離グループにはインスタンスを配置しないでください。
分離インスタンスは、RHEL 7 以降にインストールできます。
分離グループに関連付けられている以下の期間は、設定 (
 ) メニューの ジョブ タブで設定できます。
) メニューの ジョブ タブで設定できます。分離インスタンスでのステータスチェックの間隔: 分離インスタンスで実行中のジョブに対して次回にステータスチェックを行うまでスリープ状態になる時間はデフォルトでは 30 秒となっています。
分離インスタンスでの起動のタイムアウト: 分離インスタンスでジョブを起動する時のデフォルトのタイムアウト時間は 600 秒 (10 分) です。これには、分離インスタンスにソースコントロールファイル (Playbook) をコピーするために必要な時間が含まれます。
分離インスタンスでの接続のタイムアウト: 分離インスタンスとの通信時に使用する Ansible SSH 接続のタイムアウトはデフォルトで 10 秒となっています。この値は想定されるネットワークのレイテンシーよりも大幅に大きな値になるはずです。
分離グループには、Tower ユーザーインターフェースのインスタンスグループのリストビューで、適宜ラベルが付けられます。
9.2. コンテナーグループ¶
注釈
コンテナーグループ機能はテクノロジープレビュー機能で、今後のリリースで変更になる可能性があります。
Ansible Tower は、Container Groups をサポートしています。これにより、Tower がスタンドアロンとしてインストールされているか、仮想環境またはコンテナーにインストールされているかに関係なく、Tower でジョブを実行できます。コンテナーグループは、仮想環境内のリソースのプールとして機能します。OpenShift または Kubernetes コンテナーを指すインスタンスグループを作成できます。OpenShift または Kubernetes コンテナーは、Playbook の実行中のみ存在する Pod としてオンデマンドでプロビジョニングされるジョブ環境です。これは一時的な実行モデルと呼ばれ、すべてのジョブ実行に対してクリーンな環境を確保します。
場合によっては、実行環境を「常時オン」にしておくことが望ましい場合があります。これは、インスタンスの作成時に設定されます。
9.2.1. コンテナーグループの作成¶
ContainerGroup は、OpenShift または Kubernetes クラスターに接続できる資格情報が割り当てられた InstanceGroup です。Kubernetes または OpenShift でコンテナーグループを設定するには、まず、以下が必要です。
起動の対象となる namespace (「default」 namespace はありますが、ほとんどの場合はお客様によって異なります)
この namespace で Pod を起動および管理可能なロールを持つサービスアカウント
そのサービスアカウントに関連付けられたトークン (Kubernetes または OpenShift ベアラートークン)
クラスターに関連付けられた CA 証明書
コンテナーグループを作成するには、以下を実行します。
Tower のユーザーインターフェースを使用して、コンテナーグループで使用される OpenShift または Kubernetes API ベアラートークンの資格情報を作成します。詳細については、Ansible Tower User Guide の「新規認証情報の追加」を参照してください。
インスタンスグループの設定ウィンドウ
 に移動して、新しいコンテナーグループを作成します。
に移動して、新しいコンテナーグループを作成します。
 ボタンをクリックして、Create Container Group を選択します。
ボタンをクリックして、Create Container Group を選択します。
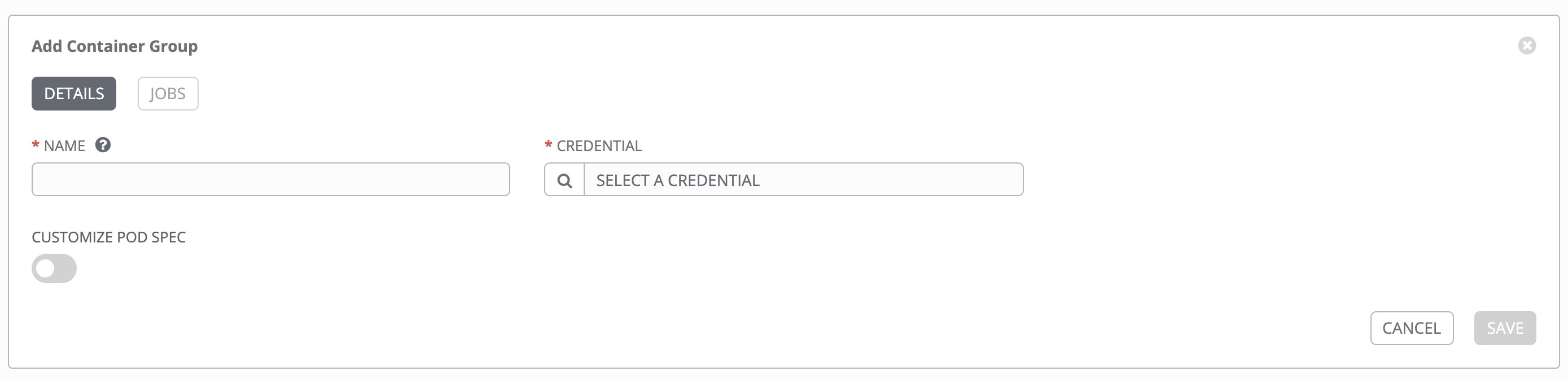
新しいコンテナーグループの名前を入力し、以前に作成した資格情報を選択して、コンテナーグループに割り当てます。
9.2.2. Pod 仕様のカスタマイズ¶
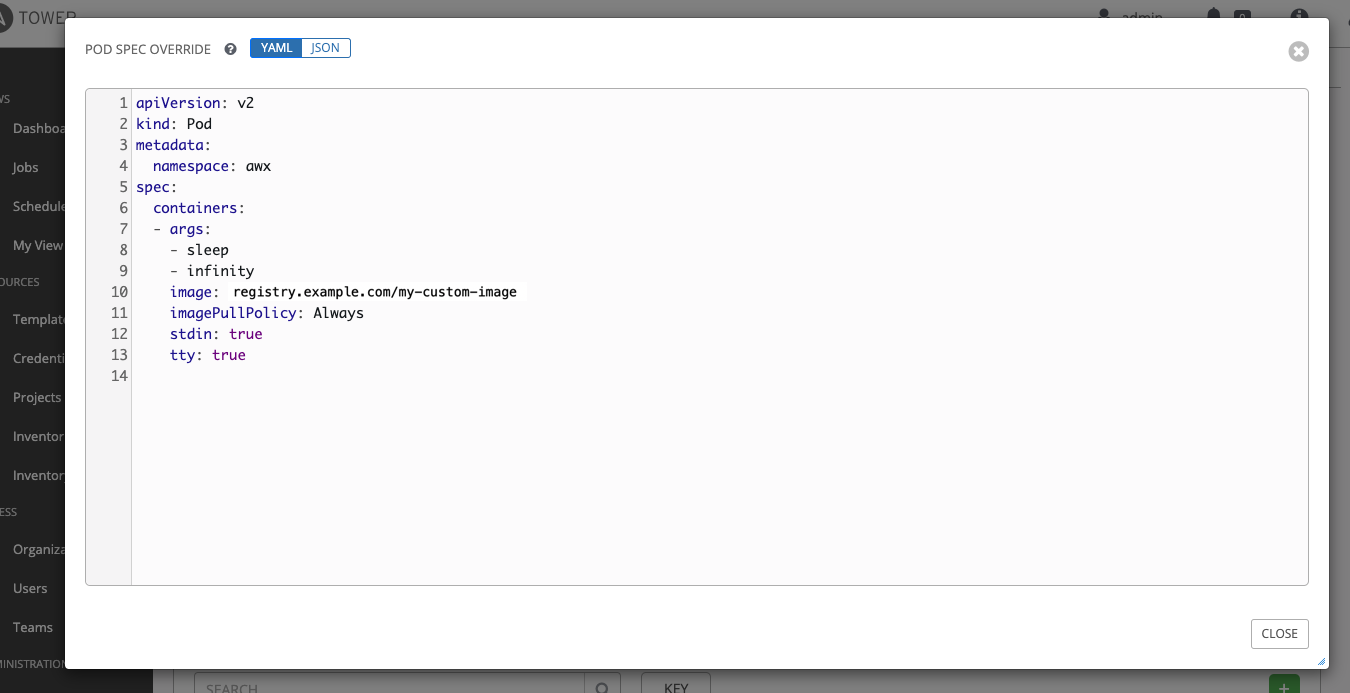
Tower にはデフォルトのシンプルな Pod の仕様が用意されていますが、カスタムの YAML (または JSON) ドキュメントを指定して、デフォルトの Pod の仕様をオーバーライドすることができます。このフィールドでは、有効な Pod JSON または YAML として「シリアル化」できる任意のカスタムフィールド (image または namespace など) が使用可能です。オプションの完全な一覧は Kubernetes documentation にあります。
Pod の仕様をカスタマイズするには、Pod Spec Override フィールドを使用します。トグルを使用して Pod Spec Override フィールドを有効化、展開し、作業が完了したら Save をクリックします。

必要に応じて、追加のカスタマイズを指定できます。カスタマイズウィンドウ全体を表示するには、Expand をクリックします。
注釈
デフォルトのコンテナグループイメージは、registry.redhat.com からプルします。つまり、イメージのプルシークレット (imagePullSecrets) は、Pod 仕様で指定する必要がありますい。イメージのプルシークレットを作成する方法は、Red Hat Container Registry Authentication article の「他のセキュアなレジストリーからのイメージを参照する pod の許可」を参照してください
コンテナーグループが正常に作成されると、新規に作成されたコンテナーグループの Details タブがそのまま表示され、コンテナーグループの情報をレビューして編集することができます。これは、Instance Group リンクから編集 ( ) ボタンをクリックして開くメニューと同じです。また、Instances を編集して、このインスタンスグループに関連付けられた Jobs をレビューすることも可能です。
) ボタンをクリックして開くメニューと同じです。また、Instances を編集して、このインスタンスグループに関連付けられた Jobs をレビューすることも可能です。
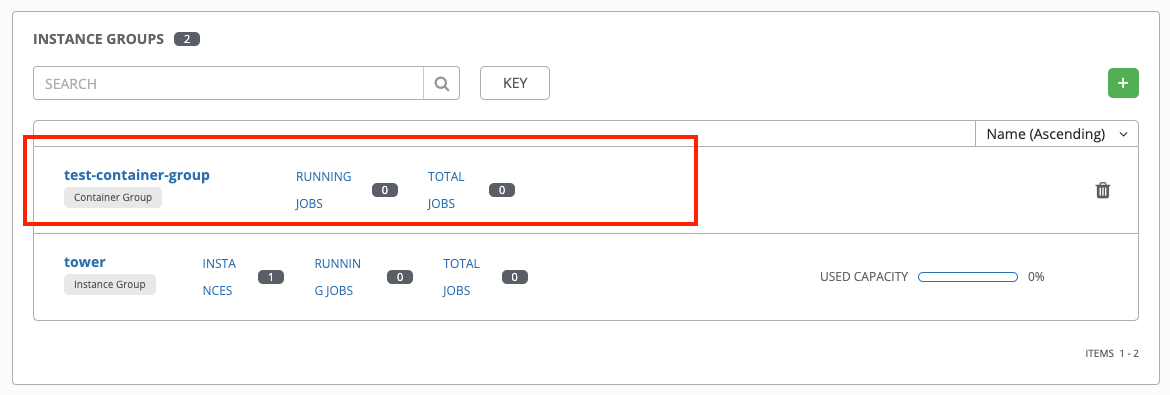
コンテナーグループとインスタンスグループは適宜ラベル付けされます。
注釈
カスタムの Pod 仕様を指定している場合でも、デフォルトの pod_spec が変更されていると、アップグレードが困難な場合があります。マニフェストの多くは、namespace が個別に指定された任意の namespace に適用することができ、大抵の場合はその namespace をオーバーライドするだけですみます。同様に、Tower の各種リリースのデフォルトイメージをデフォルトのジョブランナーコンテナーの各種バージョンに固定する場合も注意が必要です。デフォルトイメージが Pod の仕様で定義されている場合、デフォルトの Pod 仕様に対して行われた新しいデフォルトの変更は、アップグレードには反映されません。
9.2.3. コンテナーグループ機能の検証¶
コンテナーのデプロイと終了を確認するには、以下を実行します。
模擬インベントリーを作成し、インスタンスグループ フィールドにコンテナーグループの名前を入力してコンテナーグループをそのインベントリーに関連付けます。詳細については、Ansible Tower User Guide の「新規インベントリーの追加」を参照してください。
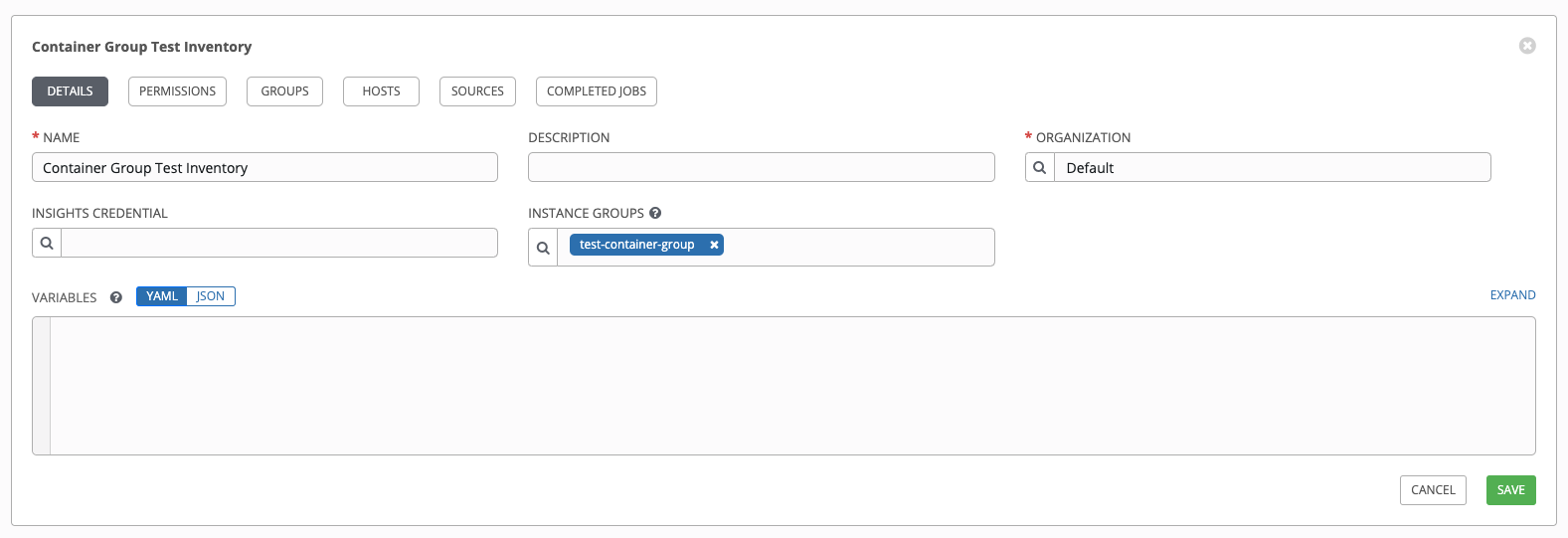
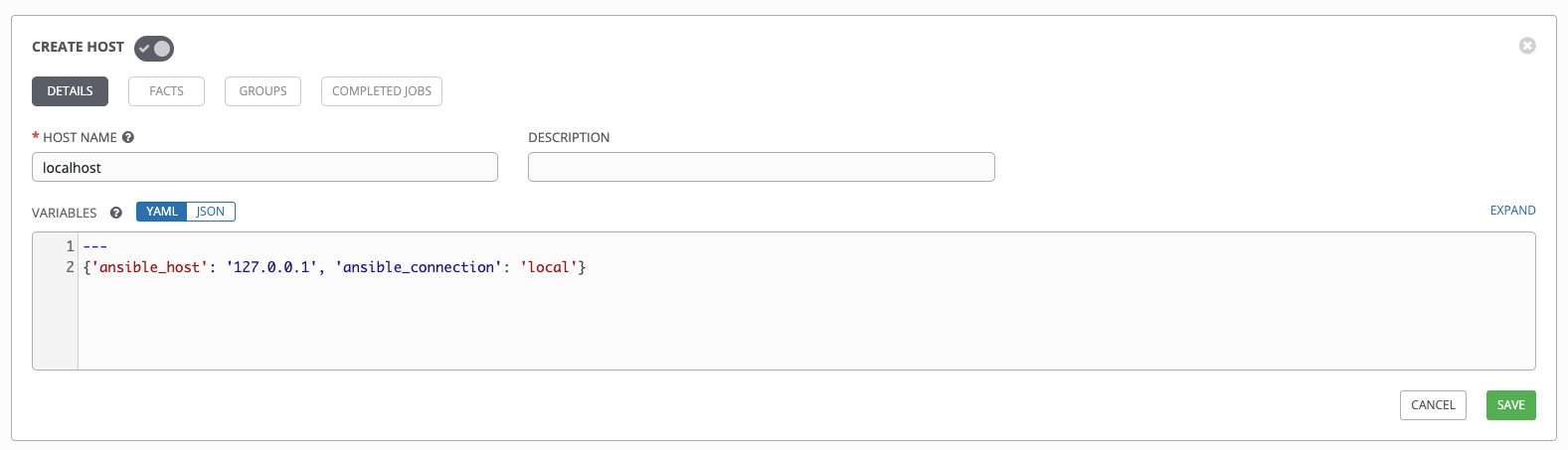
以下の変数を使用して、インベントリーに「localhost」ホストを作成します。
{'ansible_host': '127.0.0.1', 'ansible_connection': 'local'}
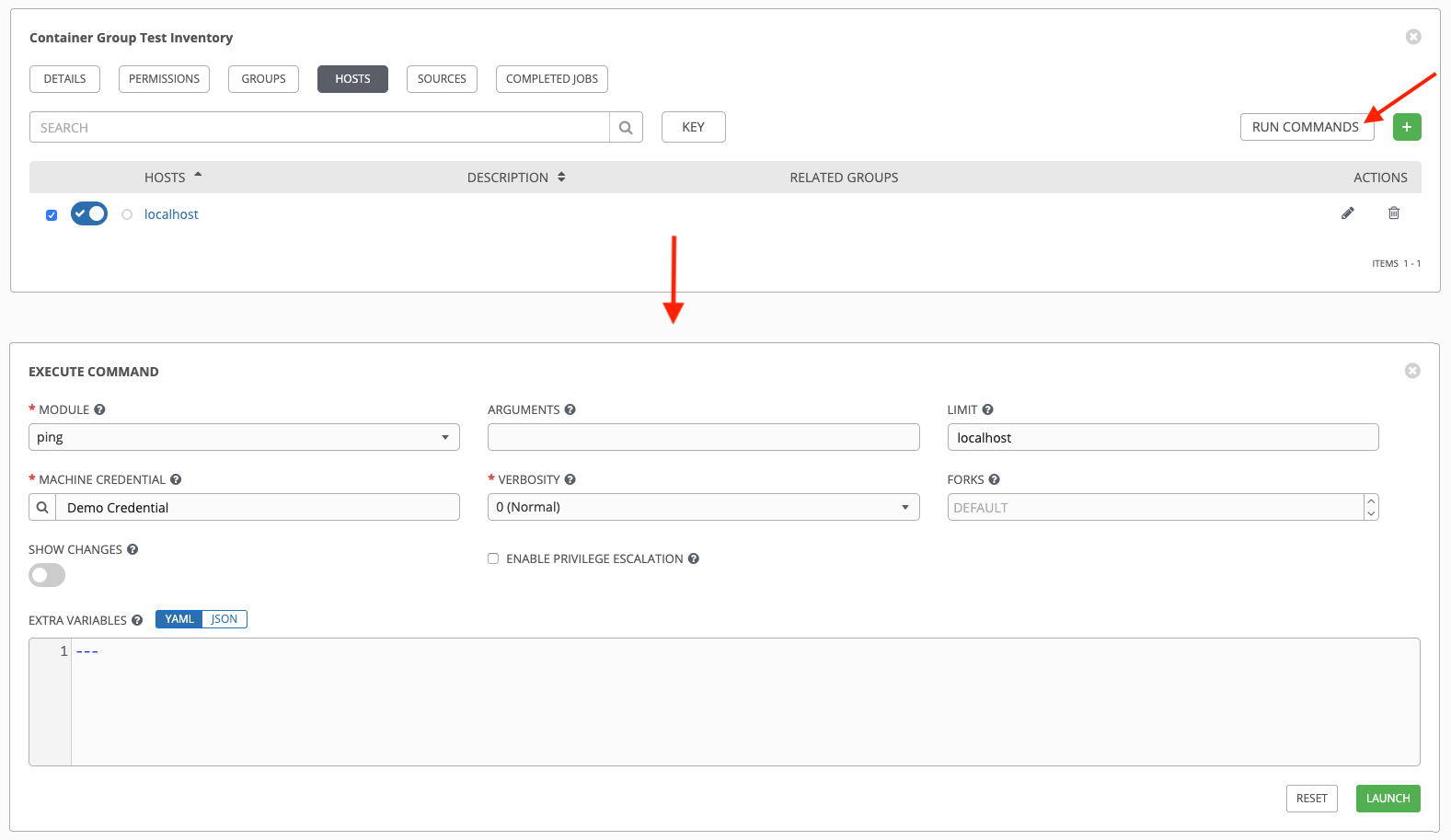
ping または setup モジュールを使用して、localhost に対してアドホックジョブを起動します。マシンの認証情報 フィールドは必須ですが、このシンプルなテストではどちらを選択してもかまいません。
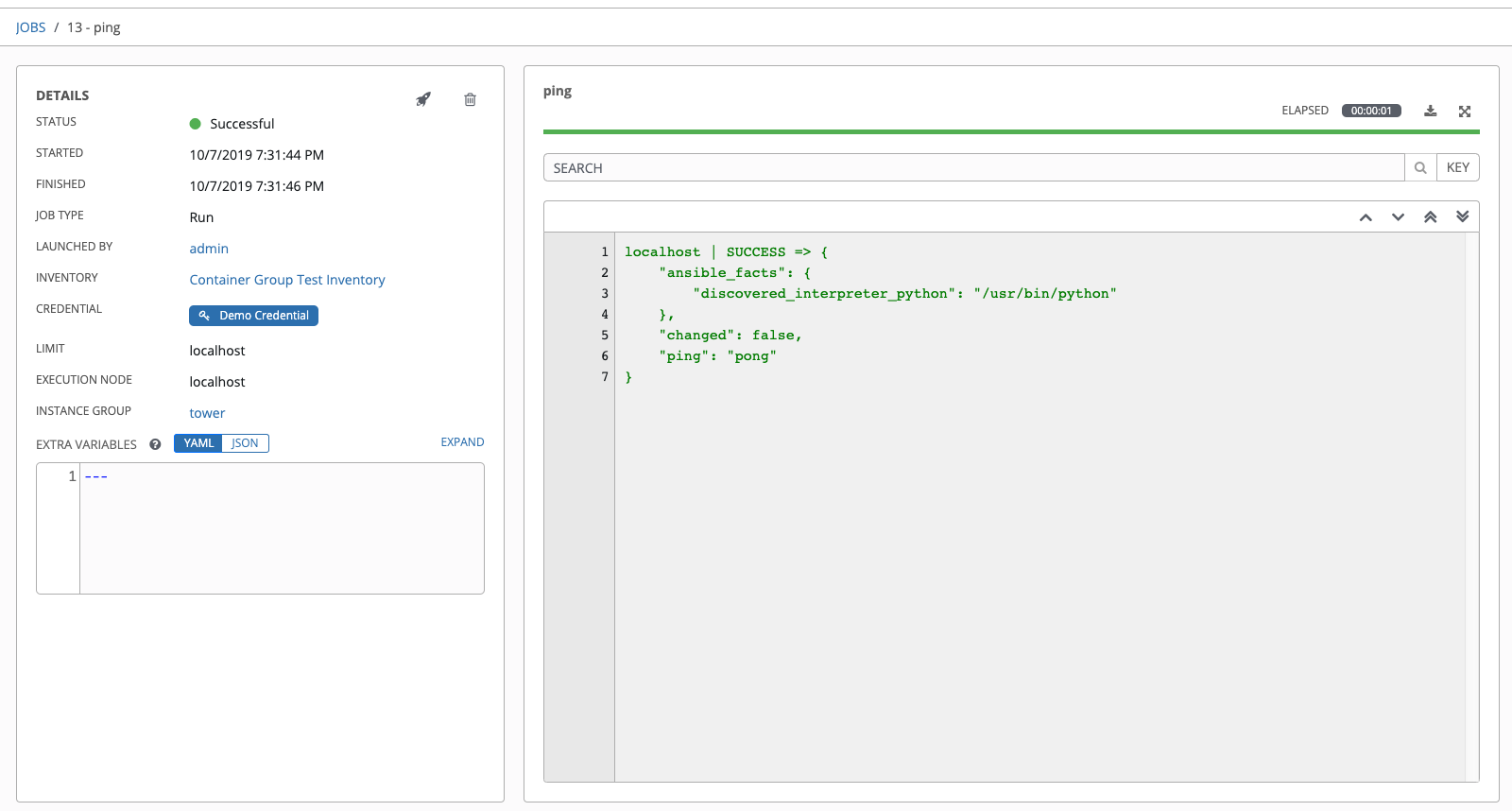
ジョブの詳細ビューに、アドホックジョブの 1 つを使用してコンテナーに正常に到達したことが表示されます。
OpenShift または Kubernetes UI を使用している場合には、Pod のデプロイ時や終了時に、Pod が表示されたり非表示になったりします。また、CLI を使用して namespace で get pod の操作を実行すると、これらの同じイベントがリアルタイムで発生するのを確認できます。
9.2.4. コンテナーグループジョブの表示¶
コンテナーグループに関連付けられたジョブを実行すると、そのジョブの詳細を 詳細 ビューと、関連付けられたインスタンスグループ、および起動した実行ノードで確認できます。
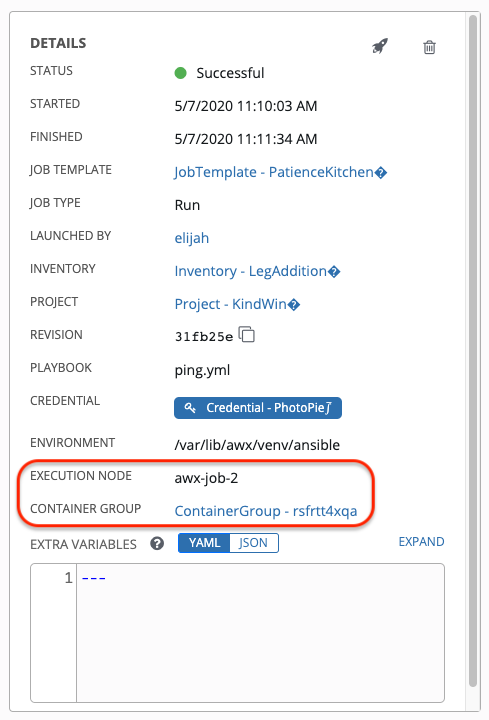
9.2.5. Kubernetes の障害状態¶
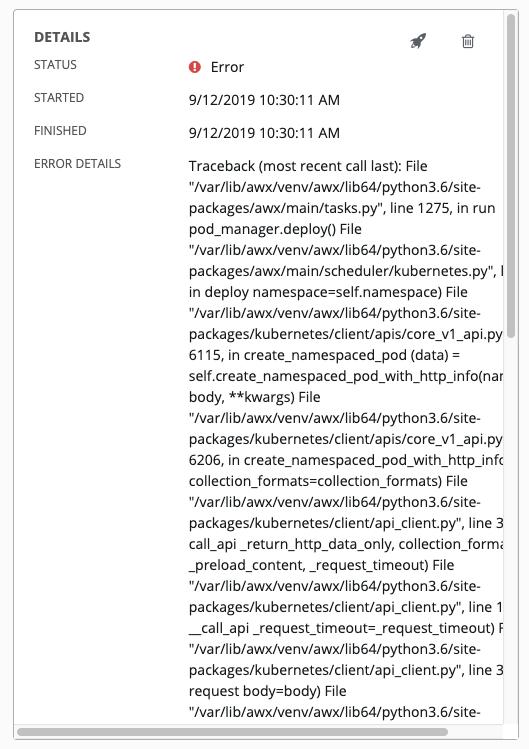
コンテナーグループを実行しており、Kubernetes からリソースのクォータを超えたという応答があると、Tower はジョブを保留状態のままにします。他の障害では、以下の例のように、障害の理由を示す エラーの詳細 フィールドのトレースバックになります。
9.2.6. コンテナーの容量制限¶
コンテナーの容量制限と割り当ては、Kubernetes API のオブジェクトを介して定義されます。
特定の名前空間内のすべてのポッドに制限を設定するには、
LimitRangeオブジェクトを使用します。Configure Default Memory Requests and Limits for a Namespace は、Kubernetes のドキュメントを参照してください。Tower によって起動されたポッド定義に直接制限を設定するには、「Customize the Pod spec」を参照し、Kubernetes のドキュメントを参照してオプションを Assign Memory Resources to Containers and Pods に設定します。
注釈
コンテナーグループは、通常のノードが使用する容量アルゴリズムを使用しません。たとえば、フォークの数をジョブテンプレートレベルで明示的に設定する必要があります。Tower でフォークが構成されている場合、その設定はコンテナーに渡されます。