19. 作业模板¶
job template 是用于运行 Ansible 作业的定义和参数集。作业模板对于多次执行同一作业很有用。作业模板还可促进 Ansible playbook 内容的重复使用和团队之间的协作。
The Templates menu opens a list of the job templates that are currently available. The default view is collapsed (Compact), showing the template name, template type, and the timestamp of last job that ran using that template. You can click Expanded (arrow next to each entry) to expand to view more information. This list is sorted alphabetically by name, but you can sort by other criteria, or search by various fields and attributes of a template.
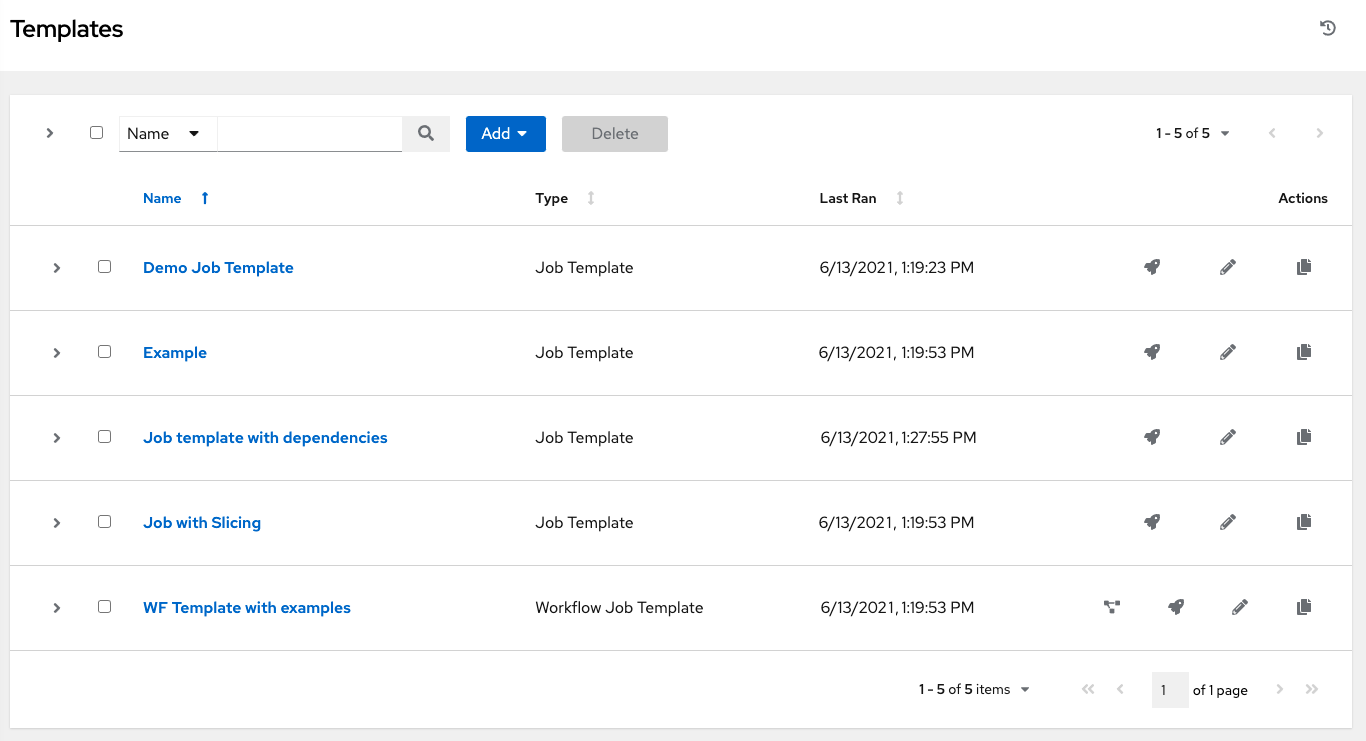
From this screen, you can launch ( ), edit (
), edit ( ), and copy (
), and copy ( ) a job template. To delete a job template, you must select one or more templates and click the Delete button. Before deleting a job template, be sure it is not used in a workflow job template.
) a job template. To delete a job template, you must select one or more templates and click the Delete button. Before deleting a job template, be sure it is not used in a workflow job template.
注解
如果删除了由其他工作项目使用的项,则会打开一条信息,列出会受到删除影响的项,并提示您确认删除。一些界面会包括无效的或以前已被删除的项,因此它们将无法运行。以下是这类信息的一个示例:

注解
作业模板可以用来构建工作流模板。旁边显示工作流可视化工具 (![]() ) 图标的模板为工作流模板。点击此图标可通过图形方式构建工作流。作业模板中的许多参数允许您启用 Prompt on Launch,这些参数可在工作流级别进行修改,且不会影响在作业模板级别分配的值。如需了解相关说明,请参阅 工作流可视化工具 部分。
) 图标的模板为工作流模板。点击此图标可通过图形方式构建工作流。作业模板中的许多参数允许您启用 Prompt on Launch,这些参数可在工作流级别进行修改,且不会影响在作业模板级别分配的值。如需了解相关说明,请参阅 工作流可视化工具 部分。
19.1. 创建作业模板¶
要创建新作业模板,请执行以下操作:
点 Add 按钮,然后从菜单列表中选择 Job Template。
在以下字段中输入相关信息:
Name:输入作业名称。
Description:根据需要输入任意描述(可选)。
Job Type:选择作业类型:
Run:启动时执行 playbook,在所选主机上运行 Ansible 任务。
Check:执行 playbook 的“dry run”并报告将要进行的更改,而无需实际进行更改。不支持检查模式的任务将被跳过,且不会报告潜在的更改。
Prompt on Launch:如果选择此选项,即使提供了默认值,也会在启动时提示您选择运行或检查作业类型。
注解
有关作业类型的更多信息,请参阅 Ansible 文档的 Playbooks: Special Topics 部分。
Inventory:从当前登录的用户可用的清单中选择要用于此作业模板的清单。
Prompt on Launch:如果选择此选项,即使提供了默认值,也会在启动时提示您选择要针对哪个清单来运行此作业模板。
Project:从当前登录的用户可用的项目中选择要用于此作业模板的项目。
SCM Branch:仅当您选择允许分支覆盖的项目时,才会出现此字段。指定要在作业运行中使用的覆盖分支。如果留空,则使用项目中指定的 SCM 分支(或提交散列或标签)。有关更多详情,请参阅 job branch overriding。
Prompt on Launch:如果选择此选项,即使提供了默认值,也会在启动时提示您选择一个 SCM 分支。
Playbook:从可用的 playbook 中选择要使用这个作业模板启动的 playbook。此字段会自动填充选定项目的项目基本路径中的 playbook 名称。或者,如果未列出 playbook 的名称,您可以输入它,例如要您与该 playbook 一起运行的文件的名称(类似
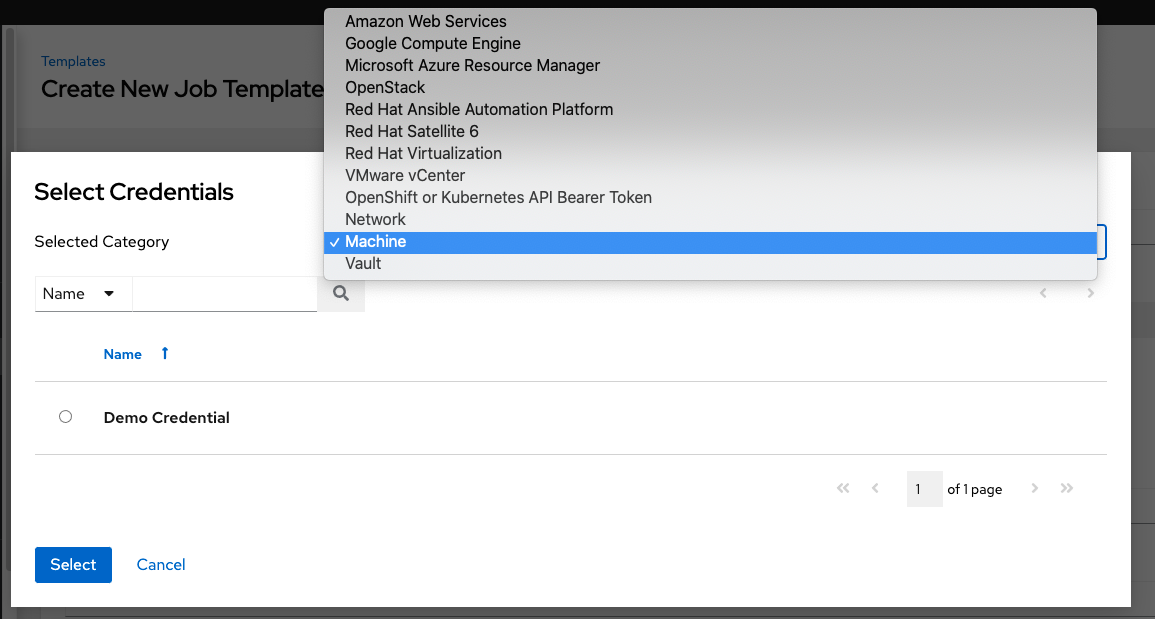
foo.yml)。如果输入无效的文件名,模板将会显示错误,或者导致作业失败。Credentials:点击
 按钮以打开单独的窗口。从可用的选项中选择要用于此作业模板的凭证。如果列表较长,请使用下拉菜单按凭证类型进行过滤。
按钮以打开单独的窗口。从可用的选项中选择要用于此作业模板的凭证。如果列表较长,请使用下拉菜单按凭证类型进行过滤。
注解
Some credential types are not listed because they do not apply to certain job templates.
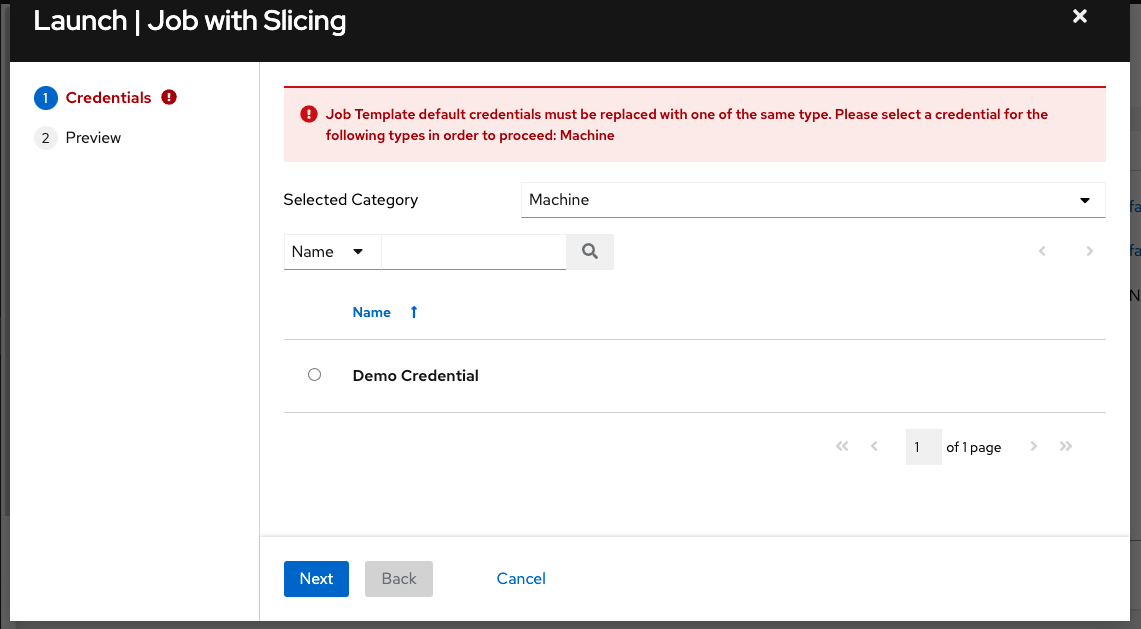
Prompt on Launch:如果选择此选项,在启动具有默认机器凭证的作业模板时,如果在启动前未将默认机器凭证替换为另一个机器凭证,您将无法在 Prompt 对话框中删除默认机器凭证。或者,您可以添加更多您认为合适的凭证。以下是此类消息的示例:
Forks:执行 playbook 时使用的并行或同步进程数量。如果为零则代表使用 Ansible 默认设置,即 5 个并行进程,除非在
/etc/ansible/ansible.cfg中被覆盖。Limit:用于进一步限制受 playbook 管理或影响的主机列表的主机模式。可以用冒号(“:”)来分隔多个模式。与核心 Ansible 一样,“a:b”表示“在组 a 或 b 中”,“a:b:&c”表示“在 a 或 b 中但必须在 c 中”,“a:!b”表示“在 a 中且一定不在 b 中”。
Prompt on Launch:如果选择此选项,即使提供了默认值,也会在启动时提示您选择一个限制。
注解
更多信息和示例请参阅 Ansible 文档中的 Patterns。
Verbosity:在 playbook 执行时,控制 Ansible 生成的输出等级。选择从 Normal 到各种 Verbose 或 Debug 设置的详细程度。此项仅出现在“详情”报告视图中。Verbose 日志记录中包括所有命令的输出。Debug 日志记录非常详细,并包含了在特定支持实例中很有用的有关 SSH 操作的信息。大多数用户不需要查看调试模式输出。
警告
详细程度 5 会导致 automation controller 在作业运行时大量阻断,这可能会延迟报告作业已完成(即使它已经完成),并可能导致浏览器标签页锁定。
Prompt on Launch:如果选择此选项,即使提供了默认值,也会在启动时提示您选择一个详细程度。
Job Tags:提供以逗号分隔的 playbook 标签列表,以指定应执行 playbook 的哪些部分。有关更多信息和示例,请参阅 Ansible 文档中的 Tags。
Prompt on Launch:如果选择此选项,即使提供了默认值,也会在启动时提示您选择一个作业标签。
Skip Tags:提供以逗号分隔的 playbook 标签列表,以跳过执行 playbook 的某些任务或部分。有关更多信息和示例,请参阅 Ansible 文档中的 Tags。
Prompt on Launch:如果选择此选项,即使提供了默认值,也会在启动时提示您选择一个要跳过的标签。
Labels:提供描述此作业模板的可选标签,如“dev”或“test”。标签可用于对显示中的作业模板和完成的作业进行分组和过滤。
在将标签添加到作业模板时会创建标签。标签使用作业模板中提供的项目关联到单个机构。如果机构成员具有编辑权限(如 admin 角色),则他们可在作业模板中创建标签。
保存作业模板后,标签会显示在 Expanded 视图的作业模板概述中。
点击标签旁边的“x”可删除它。标签被删除后,便不再与作业或作业模板关联,该标签会从机构标签列表中永久删除。
在启动时,作业会继承作业模板中的标签。如果从作业模板中删除某个标签,它也会从作业中删除。
Instance Groups:点击
按钮以打开单独的窗口。选择要在其上面运行此作业模板的实例组。如果列表较长,请使用搜索功能来缩小选项范围。Job Slicing:指定您希望此作业模板运行的分片数。每个分片将针对清单的一部分运行相同的任务。如需了解更多有关作业分片的信息,请参阅 任务分片。
Timeout:允许您指定在任务被取消前可以运行该任务的时间限度(以秒为单位)。默认为 0,即没有作业超时。
Show Changes:允许您查看 Ansible 任务所做的更改。
Prompt on Launch:如果选择此选项,即使提供了默认值,也会在启动时提示您选择是否显示更改。
Options: Specify options for launching this template, if necessary.
Privilege Escalation: If checked, you enable this playbook to run as an administrator. This is the equivalent of passing the
--becomeoption to theansible-playbookcommand.Provisioning Callbacks: If checked, you enable a host to call back to automation controller via the REST API and invoke the launch of a job from this job template. Refer to 置备回调 for additional information.
Enable Webhook:打开与用于启动作业模板的预定义 SCM 系统 Web 服务进行接口的功能。当前支持的 SCM 系统为 GitHub 和 GitLab。
如果您启用 Webhook,会显示其他字段,提示输入更多信息:

Webhook Service:从中选择侦听 Webhook 的服务
Webhook URL:自动填充将 POST 请求发送到的 Webhook 服务的 URL。
Webhook Key:生成的共享 secret,供 Webhook 服务用来签署发送到 automation controller 的有效负载。必须在 Webhook 服务上的设置中对此进行配置,以使 automation controller 接受来自该服务的 Webhook。
**Webhook Credential**(可选):提供 GitHub 或 GitLab 个人访问令牌 (PAT) 作为凭证,用来向 Webhook 服务发回状态更新。在可以选择之前,凭证必须存在。请参阅 凭证类型 以创建一个凭证。
有关设置 Webhook 的更多信息,请参阅 使用 Webhook。
Concurrent Jobs: If checked, you are allowing jobs in the queue to run simultaneously if not dependent on one another. Check this box if you want to run job slices simultaneously. Refer to 决定 automation controller 容量和作业的影响 for additional information.
Enable Fact Storage: When checked, automation controller will store gathered facts for all hosts in an inventory related to the job running.
Extra Variables:
向 playbook 传递额外的命令行变量。这是 ansible-playbook 的“-e”或“--extra-vars”命令行参数,记录在 Ansible 文档中,请参阅 Passing Variables on the Command Line。
使用 YAML 或 JSON 提供键/值对。这些变量具有最大优先级值并且会覆盖在其他位置指定的其他变量。示例值可能为:
git_branch: production release_version: 1.5如需更多信息,请参阅 额外变量。
Prompt on Launch:如果选择此选项,即使提供了默认值,也会在启动时提示您选择一个命令行变量。
注解
如果您希望能够在计划中指定 extra_vars,您必须在作业模板中为 EXTRA VARIABLES 选择 Prompt on Launch,或者在作业模板中启用问卷调查,然后那些回答的问卷调查问题将成为 extra_vars。

当您完成作业模板详情配置后,请点击 Save。
Saving the template does not exit the job template page but advances to the Job Template Details tab for viewing. After saving the template, you can click Launch to launch the job, or click Edit to add or change the attributes of the template, such as permissions, notifications, view completed jobs, and add a survey (if the job type is not a scan). You must first save the template prior to launching, otherwise, the Launch button remains grayed-out.

You can verify the template is saved when the newly created template appears on the Templates list view.
19.2. 添加权限¶
在 Access 选项卡中,点 Add 按钮。
选择要添加的用户或团队并点 Next
点名称旁边的复选框从列表中选择一个或多个用户或团队,将它们添加为成员并点 Next。
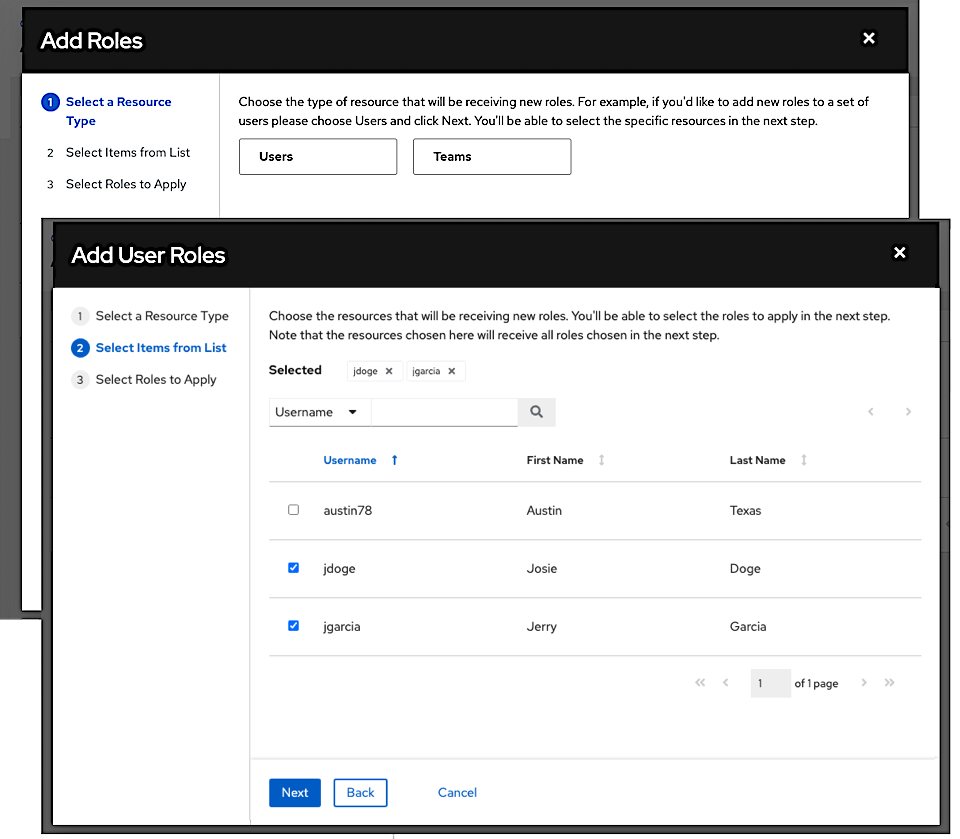
在这个示例中,选择了两个用户来添加。
选择您希望所选用户或团队具有的角色。请确保向下滚动以获得完整的角色列表。不同的资源有不同的可用选项。

点 Save 按钮将角色应用到所选用户或团队,并将它们添加为成员。
将关闭 Add Users/Teams 窗口,以显示为每个用户和团队分配的更新角色。

若要删除特定用户的角色,可单击其资源旁边的解除关联(x)按钮。
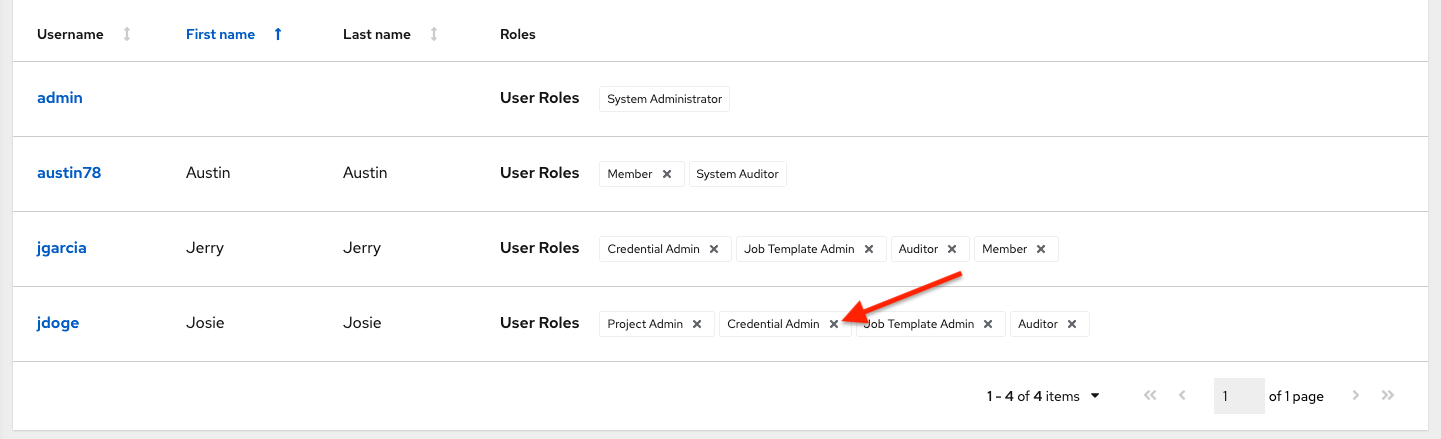
这会出现确认对话框,要求您确认解除关联。
19.3. 使用通知¶
Clicking the Notifications tab allows you to review any notification integrations you have setup and their statuses, if they have ran.

请使用切换按钮启用或禁用要与特定模板搭配使用的通知。更多详情请参阅 启用和禁用通知。
If no notifications have been set up, click the Add button to create a new notification. Refer to 通知类型 for additional details on configuring various notification types and extended messaging.
19.4. 查看完成的作业¶
Completed Jobs 标签页提供了已运行的作业模板列表。点击 Expanded 查看每个作业的详情,包括其状态、ID 和名称、作业类型、启动和完成的时间、谁启动了作业,以及使用了哪个模板、清单、项目和凭证。您可以使用任何这些条件过滤已完成的作业列表。

在此列表中显示的切片作业会进行相应标记,包含已运行的分片作业数量:

19.5. 调度¶
从 Schedules 标签页访问特定作业模板的计划。

19.5.1. 调度作业模板¶
要调度作业模板运行,请点击 Schedules 标签页。
如果已经设置了调度,请检查、编辑或启用/禁用您的调度首选项。
如果还没有设置调度,请参阅 调度 了解更多信息。
如果在 Credentials 字段中选择了 Prompt on Launch,当您为作业模板创建或编辑调度信息时,Schedules 表单的底部将显示 Prompt 按钮。如果没有在保存前将默认机器凭证替换为另一个机器凭证,您将无法在 Prompt 对话框中删除默认机器凭证。以下是此类消息的示例:
注解
为了能够在计划中设置 extra_vars,您必须在作业模板中为 EXTRA VARIABLES 选择 Prompt on Launch,或者在作业模板中启用问卷调查,然后那些回答的问卷调查问题将成为 extra_vars。
19.6. 调查¶
在作业模板创建或编辑屏幕中,运行或检查作业类型将提供一种设置问卷调查的方法。问卷调查为 playbook 设置额外变量,类似于“Prompt for Extra Variables”,但是以用户友好的问答方式进行。问卷调查还可允许验证用户输入。点 Survey 标签页创建问卷调查。
问卷调查的用例有很多。例如,运营人员可能希望向开发人员提供一个无需高级 Ansible 知识即可运行的“推送到阶段”按钮。启动时,该任务可能会提示输入问题的回答,例如:“我们应该发布什么标签?”
可以询问很多类型的问题,包括多项选择题。
19.6.1. 创建问卷调查¶
要创建问卷调查,请执行以下操作:
Click the Survey tab and click the Add button.
问卷调查可由任何数量的问题组成。对每个问题,请输入以下信息:
Name:询问用户的问题
**Description**(可选):向用户询问的问题描述。
Answer Variable Name:将用户回答存储在其中的 Ansible 变量名称。这是供 playbook 使用的变量。变量名称不能包含空格。
Answer Type:从以下问题类型中选择。
Text:单行文本。您可以为该回答设置最小和最大长度(字符数)。
Textarea:多行文本字段。您可以为该回答设置最小和最大长度(字符数)。
Password:回答被视为敏感信息,和实际密码的处理方式很像。您可以为该回答设置最小和最大长度(字符)。
Multiple Choice (single select):选项列表,每次只能选择其中一个选项。请在 Multiple Choice Options 框中输入选项,每行一个。
Multiple Choice (multiple select):列表选项,每次可选择其中任意数量的选项。在 Multiple Choice Options 框中输入选项,每行一个。
Integer:整数。您可以为该回答设置最小和最大长度(字符数)。
Float:小数。您可以为该答案设置最小和最大长度(字符数)。
Required:用户是否需要回答这个问题。
Minimum length and Maximum length: Specify if a certain length in the answer is required.
Default Answer:问题的默认回答。这个值在界面中预先填充,并在用户未提供回答时使用。

Once you have entered the question information, click Save to add the question.
The survey question displays in the Survey list. For any question, you can click to edit the question, or check the box next to each question and click Delete to delete the question, or use the toggle button at the top of the screen to enable or disable the survey prompt(s).
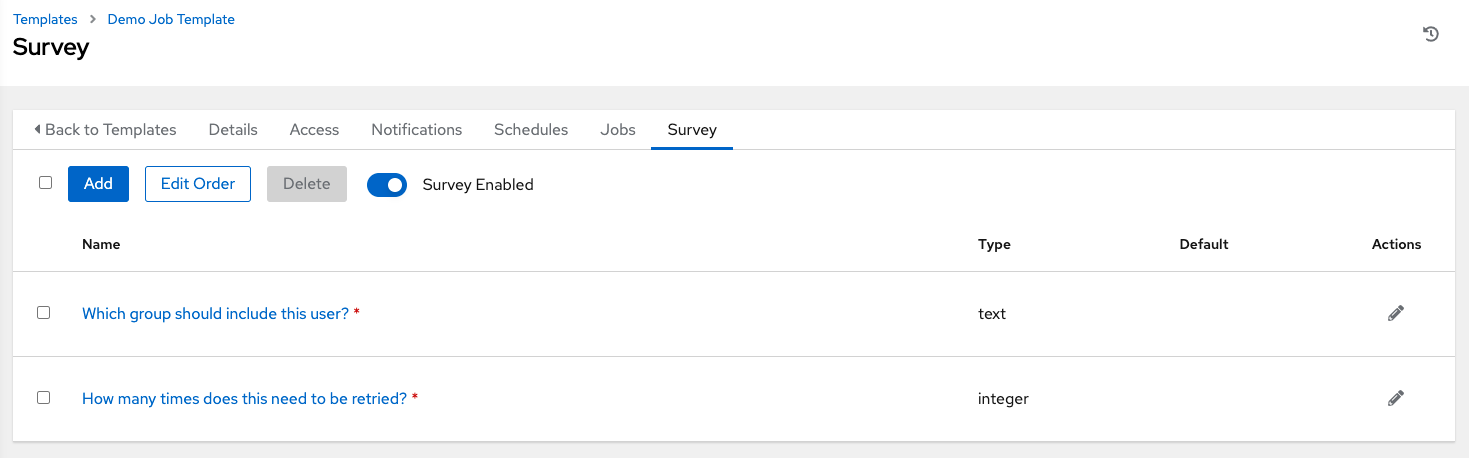
If you have more than one survey question, use the Edit Order button to rearrange the order of the questions by clicking and dragging on the grid icon.
To add more questions, click the Add button to add additional questions.
19.6.2. 可选的问卷调查问题¶
问卷调查问题的 Required 设置决定了对于与之交互的用户,回答是不是可选的。
在后台,可选的问卷调查变量可在 extra_vars 中传递给 playbook,即使没有填写也一样。
如果非文本变量(输入类型)标记为可选,且未填写,则不会将任何问卷调查
extra_var传递给 playbook。如果文本输入或文本区域输入标记为可选,未填充,且最小
length > 0,则不会将任何问卷调查extra_var传递给 playbook。如果文本输入或文本区域输入标记为可选,未填写,且最小
length === 0,则会将该问卷调查extra_var传递给 playbook,并将值设为空字符串 ( "" )。
19.7. 启动作业模板¶
automation controller 的主要优点是 Ansible playbook 的按钮式部署。您可以轻松地配置模板,以存储您通常会在命令行上传递给 ansible-playbook 的所有参数,不仅仅包括 playbook,还包括清单、凭证、额外变量以及您可在命令行上指定的所有选项和设置。
更简单的部署意味着每次都能以相同的方式运行 playbook,可以提高一致性,并且您可以委托职责。即使用户不是 Ansible 专家,也可以运行由其他人编写的 playbook。
通过以下任一方式启动作业模板:
从左侧导航栏上的 Templates 菜单或在 Job Template Details 视图中访问作业模板列表,滚动到底部以从模板列表中访问
按钮。

在要启动的作业模板的作业模板视图中,点击 Launch。
作业可能需要额外信息才能运行。启动时可能会要求提供以下数据:
设置的凭证
为任意参数选择
Prompt on Launch选项已设置为 Ask 的密码
问卷调查(如果已经为作业模板配置了问卷调查)
额外变量(如果作业模板要求提供)
注解
如果一个作业有用户提供的值,则这些值会在重新启动时被考虑。如果用户没有指定值,作业会使用作业模板中的默认值。作业并不会按当前的状态原样重新启动。在重新启动时用户的输入会被应用到作业模板中。
以下是一个作业启动示例,它提示输入作业标签,并运行 调查 中创建的示例问卷调查。
注解
在一个标签页中输入值,然后返回上一个标签页,然后再继续进入下一个标签页会导致在剩余标签页中需要重新提供值。请安装提示出现的顺序填写标签页来避免出现这种情况。
除了作业模板和问卷调查中设置的额外变量之外,automation controller 还会自动将以下变量添加到作业环境中:
awx_job_id:此作业运行的作业 IDawx_job_launch_type:用于说明作业启动方式的描述:manual:作业是由用户手动启动的。
relaunch:作业是通过重启来启动的。
callback:作业是通过主机回调启动的。
scheduled:作业是由一个调度启动的。
dependency:作业是作为另一个作业的依赖项启动的。
workflow:作业是从工作流作业中启动的。
sync:作业是从项目同步启动的。
scm:作业是作为清单 SCM 同步创建的。
awx_job_template_id:此作业运行使用的作业模板 IDawx_job_template_name:此作业使用的作业模板名称awx_project_revision:此特定作业使用的源树的修订标识符(它还与作业的字段scm_revision相同)awx_project_scm_branch:作业模板使用的项目配置的默认项目 SCM 分支awx_job_scm_branch如果作业覆盖了 SCM 分支,其值将显示在此显示awx_user_email: The user email of the controller user that started this job. This is not available for callback or scheduled jobs.awx_user_first_name: The user's first name of the controller user that started this job. This is not available for callback or scheduled jobs.awx_user_id: The user ID of the controller user that started this job. This is not available for callback or scheduled jobs.awx_user_last_name: The user's last name of the controller user that started this job. This is not available for callback or scheduled jobs.awx_user_name: The user name of the controller user that started this job. This is not available for callback or scheduled jobs.awx_schedule_id:启动了此作业的调度的 ID(如果适用)awx_schedule_name:启动了此作业的调度的名称(如果适用)awx_workflow_job_id:启动了此作业的工作流作业的 ID(如果适用)awx_workflow_job_name:启动了此作业的工作流作业的名称(如果适用)。请注意,这还与工作流作业模板相同。awx_inventory_id:此作业使用的清单的 ID(如果适用)awx_inventory_name:此作业使用的清单的名称(如果适用)
For compatibility, all variables are also given an "awx" prefix, for example, awx_job_id.
启动后,automation controller 会在 Jobs 标签页下自动将 Web 浏览器重定向到此作业的 Job Status 页面。
注解
您可以从列表视图中重新启动最新的作业,以便针对指定清单中的所有主机或者仅仅是失败的主机重新运行。更多详情请参阅 Automation Controller User Guide 中的 Jobs
当分片作业正在运行时,作业列表会显示工作流和作业分片,以及用于单独查看其详情的链接。
19.8. 复制作业模板¶
If you choose to copy Job Template, it does not copy any associated schedule, notifications, or permissions. Schedules and notifications must be recreated by the user or admin creating the copy of the Job Template. The user copying the Job Template will be granted the admin permission, but no permissions are assigned (copied) to the Job Template.
从左侧导航栏上的 Templates 菜单或在 Job Template Details 视图中访问作业模板列表,滚动到底部以从模板列表中访问它。
Click the
button associated with the template you want to copy.
The new template with the name of the template from which you copied and a timestamp displays in the list of templates.
Click to open the new template and click Edit.
将 Name 字段的内容替换为新名称,并提供或者修改其他字段中的条目以完成此页面。
完成后请点击 Save。
19.9. 扫描作业模板¶
Scan jobs are no longer supported starting with automation controller 3.2. This system tracking feature was used as a way to capture and store facts as historical data. Facts are now stored in the controller via fact caching. For more information, see 事实缓存.
如果在 automation controller 3.2 之前的系统中有作业模板扫描作业,它们已被转换为运行类型(类似与正常作业模板),并且保留了其相关资源(例如清单、凭证)。默认情况下会为没有相关项目的作业模板扫描作业分配一个特殊的 playbook,或者您可以使用自己的扫描 playbook 指定一个项目。为每个机构创建了一个指向 https://github.com/ansible/tower-fact-modules 的项目,并将作业模板设为 playbook https://github.com/ansible/tower-fact-modules/blob/master/scan_facts.yml。
19.9.1. 事实扫描 Playbook¶
扫描作业 playbook scan_facts.yml 包含三个 fact scan modules``(软件包、服务和文件)的调用以及 Ansible 的标准事实收集。``scan_facts.yml playbook 文件类似如下:
- hosts: all
vars:
scan_use_checksum: false
scan_use_recursive: false
tasks:
- scan_packages:
- scan_services:
- scan_files:
paths: '{{ scan_file_paths }}'
get_checksum: '{{ scan_use_checksum }}'
recursive: '{{ scan_use_recursive }}'
when: scan_file_paths is defined
scan_files 事实模块是唯一接受参数的模块,通过扫描作业模板中的 extra_vars 传递。
scan_file_paths: '/tmp/'
scan_use_checksum: true
scan_use_recursive: true
scan_file_paths参数可能有多个设置(如/tmp/或/var/log)。scan_use_checksum和scan_use_recursive参数也可以设为 false 或省略。省略等同于 false 设置。
扫描作业模板应启用 become 并使用使 become 成为可能的凭证。您可以通过从 Options 菜单中选中 Enable Privilege Escalation 来启用 become:

19.9.2. scan_facts.yml 支持的操作系统¶
如果您将 scan_facts.yml playbook 与“使用事实缓存”搭配使用,请确保您的操作系统受支持:
Red Hat Enterprise Linux 5、6 和 7
Ubuntu 16.04(Unbuntu 支持已被弃用并将在以后的发行版本中删除)
OEL 6 和 7
SLES 11 和 12
Debian 6、7、8
Fedora 22、23、24
Amazon Linux 2016.03
Windows Server 2008 及更新版本
请注意,其中有些操作系统可能需要进行初始配置,才能运行 python 和/或访问扫描模块依赖的 python 软件包(比如 python-apt)。
19.9.3. 预扫描设置¶
以下的 playbook 示例配置了特定发行版运行扫描,以便可以针对它们运行扫描作业。
Bootstrap Ubuntu (16.04)
---
- name: Get Ubuntu 16, and on ready
hosts: all
sudo: yes
gather_facts: no
tasks:
- name: install python-simplejson
raw: sudo apt-get -y update
raw: sudo apt-get -y install python-simplejson
raw: sudo apt-get install python-apt
Bootstrap Fedora (23, 24)
---
- name: Get Fedora ready
hosts: all
sudo: yes
gather_facts: no
tasks:
- name: install python-simplejson
raw: sudo dnf -y update
raw: sudo dnf -y install python-simplejson
raw: sudo dnf -y install rpm-python
19.9.4. 自定义事实扫描¶
自定义事实扫描的 playbook 与上方的事实扫描 Playbook 类似。例如,只使用自定义 scan_foo Ansible 事实模块的 playbook 类似如下:
scan_custom.yml:
- hosts: all
gather_facts: false
tasks:
- scan_foo:
scan_foo.py:
def main():
module = AnsibleModule(
argument_spec = dict())
foo = [
{
"hello": "world"
},
{
"foo": "bar"
}
]
results = dict(ansible_facts=dict(foo=foo))
module.exit_json(**results)
main()
要使用自定义事实模块,请确保它位于扫描作业模板中使用的 Ansible 项目的 /library/ 子目录中。此事实扫描模块非常简单,返回一组硬编码的事实:
[
{
"hello": "world"
},
{
"foo": "bar"
}
]
如需更多信息,请参阅 Ansible 文档的 Module Provided 'Facts' 部分。
19.10. 事实缓存¶
The controller can store and retrieve facts on a per-host basis through an Ansible Fact Cache plugin. This behavior is configurable on a per-job template basis. Fact caching is turned off by default but can be enabled to serve fact requests for all hosts in an inventory related to the job running. This allows you to use job templates with --limit while still having access to the entire inventory of host facts. A global timeout setting that the plugin enforces per-host, can be specified (in seconds) through the Job Settings menu:

Upon launching a job that uses fact cache (use_fact_cache=True), the controller will store all ansible_facts associated with each host in the inventory associated with the job. The Ansible Fact Cache plugin that ships with automation controller will only be enabled on jobs with fact cache enabled (use_fact_cache=True).
When a job that has fact cache enabled (use_fact_cache=True) finishes running, the controller will restore all records for the hosts in the inventory. Any records with update times newer than the currently stored facts per-host will be updated in the database.
New and changed facts will be logged via automation controller's logging facility. Specifically, to the system_tracking namespace or logger. The logging payload will include the fields:
host_name
inventory_id
ansible_facts
where ansible_facts is a dictionary of all Ansible facts for host_name in the controller inventory, inventory_id.
注解
如果主机名包含正斜杠 (/),事实缓存将不适用于该主机。如果清单中有 100 个主机,其中一个主机的名称中有一个 /,其中的 99 个主机仍会收集事实。
19.10.1. 事实缓存的好处¶
相较于运行事实收集,事实缓存会节省大量时间。如果您在一个针对一千个主机和 fork 运行的作业中有一个 playbook,您可以轻松地花 10 分钟来收集所有这些主机的事实。但是如果您定期运行一个作业,第一次运行会缓存这些事实,而下一次运行只需从数据库中拉取它们。这会大幅削减针对大型清单(包括智能清单)的作业运行时间。
注解
Do not modify the ansible.cfg file to apply fact caching. Custom fact caching could conflict with the controller's fact caching feature. It is recommended to use the fact caching module that comes with automation controller. Fact caching is not supported for isolated nodes.
您可以选择在作业模板窗口的 Options 字段中启用缓存的事实以在作业中使用它。

要清除事实,您需要运行 Ansible clear_facts meta task。以下是使用 Ansible clear_facts 元任务的示例 playbook。
- hosts: all
gather_facts: false
tasks:
- name: Clear gathered facts from all currently targeted hosts
meta: clear_facts
The API endpoint for fact caching can be found at: http://<controller server name>/api/v2/hosts/x/ansible_facts.
19.11. 使用云凭证¶
云凭证可以在同步相应的云清单时使用。云凭证还可能与作业模板关联,并包含在运行时环境中,供 playbook 使用。当前支持的云凭证:
19.11.1. OpenStack¶
The sample playbook below invokes the nova_compute Ansible OpenStack cloud module and requires credentials to do anything meaningful, and specifically requires the following information: auth_url, username, password, and project_name. These fields are made available to the playbook via the environmental variable OS_CLIENT_CONFIG_FILE, which points to a YAML file written by the controller based on the contents of the cloud credential. This sample playbook loads the YAML file into the Ansible variable space.
OS_CLIENT_CONFIG_FILE 示例:
clouds:
devstack:
auth:
auth_url: http://devstack.yoursite.com:5000/v2.0/
username: admin
password: your_password_here
project_name: demo
Playbook 示例:
- hosts: all
gather_facts: false
vars:
config_file: "{{ lookup('env', 'OS_CLIENT_CONFIG_FILE') }}"
nova_tenant_name: demo
nova_image_name: "cirros-0.3.2-x86_64-uec"
nova_instance_name: autobot
nova_instance_state: 'present'
nova_flavor_name: m1.nano
nova_group:
group_name: antarctica
instance_name: deceptacon
instance_count: 3
tasks:
- debug: msg="{{ config_file }}"
- stat: path="{{ config_file }}"
register: st
- include_vars: "{{ config_file }}"
when: st.stat.exists and st.stat.isreg
- name: "Print out clouds variable"
debug: msg="{{ clouds|default('No clouds found') }}"
- name: "Setting nova instance state to: {{ nova_instance_state }}"
local_action:
module: nova_compute
login_username: "{{ clouds.devstack.auth.username }}"
login_password: "{{ clouds.devstack.auth.password }}"
19.11.2. Amazon Web Services¶
Amazon Web Services 云凭证在 playbook 执行过程中作为以下环境变量公开(在作业模板中,选择您的设置所需的云凭证):
AWS_ACCESS_KEY_IDAWS_SECRET_ACCESS_KEY
All of the AWS modules will implicitly use these credentials when run via the controller without having to set the aws_access_key_id or aws_secret_access_key module options.
19.11.3. Google¶
Google 云凭证在 playbook 执行过程中作为以下环境变量公开(在作业模板中,选择您的设置所需的云凭证):
GCE_EMAILGCE_PROJECTGCE_CREDENTIALS_FILE_PATH
All of the Google modules will implicitly use these credentials when run via the controller without having to set the service_account_email, project_id, or pem_file module options.
19.11.4. Azure¶
Azure 云凭证在 playbook 执行过程中作为以下环境变量公开(在作业模板中,选择您的设置所需的云凭证):
AZURE_SUBSCRIPTION_IDAZURE_CERT_PATH
All of the Azure modules implicitly use these credentials when run via the controller without having to set the subscription_id or management_cert_path module options.
19.11.5. VMware¶
VMware 云凭证在 playbook 执行过程中作为以下环境变量公开(在作业模板中,选择您的设置所需的云凭证):
VMWARE_USERVMWARE_PASSWORDVMWARE_HOST
以下示例 playbook 演示了这些凭证的使用情况:
- vsphere_guest:
vcenter_hostname: "{{ lookup('env', 'VMWARE_HOST') }}"
username: "{{ lookup('env', 'VMWARE_USER') }}"
password: "{{ lookup('env', 'VMWARE_PASSWORD') }}"
guest: newvm001
from_template: yes
template_src: linuxTemplate
cluster: MainCluster
resource_pool: "/Resources"
vm_extra_config:
folder: MyFolder
19.12. 置备回调¶
Provisioning callbacks are a feature of Automation Controller that allow a host to initiate a playbook run against itself, rather than waiting for a user to launch a job to manage the host from the Automation Controller console. Please note that provisioning callbacks are only used to run playbooks on the calling host. Provisioning callbacks are meant for cloud bursting (i.e. new instances with a need for client to server communication for configuration (such as transmitting an authorization key)), not to run a job against another host. This provides for automatically configuring a system after it has been provisioned by another system (such as AWS auto-scaling, or a OS provisioning system like kickstart or preseed) or for launching a job programmatically without invoking the Automation Controller API directly. The Job Template launched only runs against the host requesting the provisioning.
通常这会通过 firstboot 类型脚本或从 cron 访问。
To enable callbacks, check the Provisioning Callbacks checkbox in the Job Template. This displays the Provisioning Callback URL for this job template.
注解
If you intend to use Automation Controller's provisioning callback feature with a dynamic inventory, Update on Launch should be set for the inventory group used in the Job Template.

Callbacks also require a Host Config Key, to ensure that foreign hosts with the URL cannot request configuration. Please provide a custom value for Host Config Key. The host key may be reused across multiple hosts to apply this job template against multiple hosts. Should you wish to control what hosts are able to request configuration, the key may be changed at any time.
要通过 REST 手动回调,请查看 UI 中的回调 URL,其格式为:
https://<CONTROLLER_SERVER_NAME>/api/v2/job_templates/7/callback/
The '7' in this sample URL is the job template ID in Automation Controller.
来自主机的请求必须是 POST。以下是一个使用 curl 的示例(全部在一行):
curl -k -f -i -H 'Content-Type:application/json' -XPOST -d '{"host_config_key": "redhat"}' \
https://<CONTROLLER_SERVER_NAME>/api/v2/job_templates/7/callback/
The requesting host must be defined in your inventory for the callback to succeed. If Automation Controller fails to locate the host either by name or IP address in one of your defined inventories, the request is denied. When running a Job Template in this way, the host initiating the playbook run against itself must be in the inventory. If the host is missing from the inventory, the Job Template will fail with a "No Hosts Matched" type error message.
注解
If your host is not in inventory and Update on Launch is set for the inventory group, Automation Controller attempts to update cloud based inventory source before running the callback.
成功请求会在 Jobs 标签页中生成一个条目,可以在其中查看结果和历史记录。
While the callback can be accessed via REST, the suggested method of using the callback is to use one of the example scripts that ships with Automation Controller - /usr/share/awx/request_tower_configuration.sh (Linux/UNIX) or /usr/share/awx/request_tower_configuration.ps1 (Windows). Usage is described in the source code of the file by passing the -h flag, as shown below:
./request_tower_configuration.sh -h
Usage: ./request_tower_configuration.sh <options>
Request server configuration from Ansible Tower.
OPTIONS:
-h Show this message
-s Controller server (e.g. https://ac.example.com) (required)
-k Allow insecure SSL connections and transfers
-c Host config key (required)
-t Job template ID (required)
-e Extra variables
This script has some intelligence, it knows how to retry commands and is therefore a more robust way to use callbacks than a simple curl request. As written, the script retries once per minute for up to ten minutes.
注解
请注意,这是一个示例脚本。如果您在检测到失败情况时需要更多的动态行为,应编辑这个脚本,因为任何非 200 的错误代码都可能不是需要重试的暂时性错误。
Most likely you will use callbacks with dynamic inventory in Automation Controller, such as pulling cloud inventory from one of the supported cloud providers. In these cases, along with setting Update On Launch, be sure to configure an inventory cache timeout for the inventory source, to avoid hammering of your Cloud's API endpoints. Since the request_tower_configuration.sh script polls once per minute for up to ten minutes, a suggested cache invalidation time for inventory (configured on the inventory source itself) would be one or two minutes.
While we recommend against running the request_tower_configuration.sh script from a cron job, a suggested cron interval would be perhaps every 30 minutes. Repeated configuration can be easily handled by scheduling in Automation Controller, so the primary use of callbacks by most users is to enable a base image that is bootstrapped into the latest configuration upon coming online. To do so, running at first boot is a better practice. First boot scripts are just simple init scripts that typically self-delete, so you would set up an init script that called a copy of the request_tower_configuration.sh script and make that into an autoscaling image.
19.12.1. 将额外变量传递给配置回调¶
就像您可以在常规作业模板中传递 extra_vars 一样,您也可以将它们传递到配置回调。要传递 extra_vars,发送的数据必须作为应用程序/json(作为内容类型)成为 POST 请求主体的一部分。在添加您自己的 extra_vars 进行传递时,请使用以下 JSON 格式作为示例:
'{"extra_vars": {"variable1":"value1","variable2":"value2",...}}'
您还可以使用 curl 将额外变量传递给作业模板调用,如以下示例所示:
root@localhost:~$ curl -f -H 'Content-Type: application/json' -XPOST \
-d '{"host_config_key": "redhat", "extra_vars": "{\"foo\": \"bar\"}"}' \
https://<CONTROLLER_SERVER_NAME>/api/v2/job_templates/7/callback
有关详情请参阅 Launching Jobs with Curl。
19.13. 额外变量¶
注解
只有在以下条件之一被满足时,传递给作业启动 API 的 extra_vars 才有效:
它们与启用的问卷调查(survey)中的变量对应
ask_variables_on_launch被设为 True
When you pass survey variables, they are passed as extra variables (extra_vars) within the controller. This can be tricky, as passing extra variables to a job template (as you would do with a survey) can override other variables being passed from the inventory and project.
例如,假设您为清单定义了一个变量 debug = true。在作业模板问卷调查中完全有可能覆盖 debug = true 这个变量。
为确保不覆盖您需要传递的变量,请通过在问卷调查中重新定义变量来确保将其包括在内。请记住,可以在清单、组和主机级别定义额外的变量。
如果指定 ALLOW_JINJA_IN_EXTRA_VARS 参数,请参阅 Automation Controller Administration Guide 的 Controller Tips and Tricks 部分,以便在控制器 UI 的 Jobs Settings 屏幕中进行配置。
注解
作业模板额外变量字典与 Survey 变量合并。
以下是 YAML 和 JSON 格式的 extra_vars 的一些简化示例:
YAML 格式的配置:
launch_to_orbit: true
satellites:
- sputnik
- explorer
- satcom
JSON 格式的配置:
{
"launch_to_orbit": true,
"satellites": ["sputnik", "explorer", "satcom"]
}
下表记录了 automation controller 中的变量优先级的行为(层次结构)与 Ansible 中的变量优先级比较情况。
Automation Controller Variable Precedence Hierarchy (last listed wins)

19.13.1. 重新启动作业模板¶
重新启动通过将 launch_type 设置为 relaunch 来表示,而不是手动重新启动作业。重新启动行为与启动行为的偏差在于它**不**继承 extra_vars。
作业重新启动不会通过继承逻辑。它会使用为重新启动的作业计算的相同 extra_vars。
例如,假设您启动一个没有 extra_vars 的作业模板,导致创建一个名为 j1 的作业。下一步,假设您编辑作业模板,并加入一些 extra_vars``(如添加 ``"{ "hello": "world" }")。
重新启动 j1 导致创建 j2,但是由于没有继承逻辑,而且 j1 没有 extra_vars,j2 将没有任何 extra_vars。
继续前面的示例,如果您启动了包含您在创建 j1 之后添加的 extra_vars 的作业模板,创建的重新启动作业 (j3) 将包括 extra_vars。重新启动 j3 会导致创建 j4,其中也包括 extra_vars。