26. Jobs¶
A job is an instance of automation controller launching an Ansible playbook against an inventory of hosts.
The Jobs link displays a list of jobs and their statuses--shown as completed successfully or failed, or as an active (running) job. The default view is collapsed (Compact) with the job name, status, job type, and start/finish times, but you can expand to see more information. You can sort this list by various criteria, and perform a search to filter the jobs of interest.
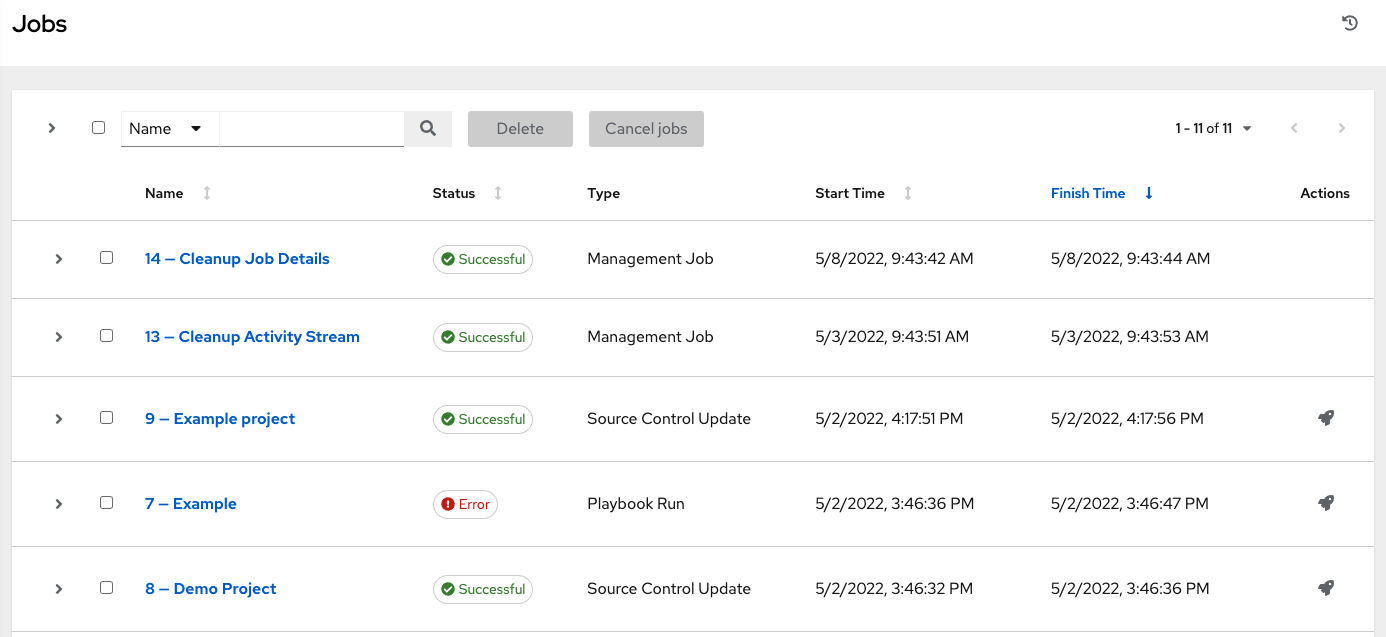
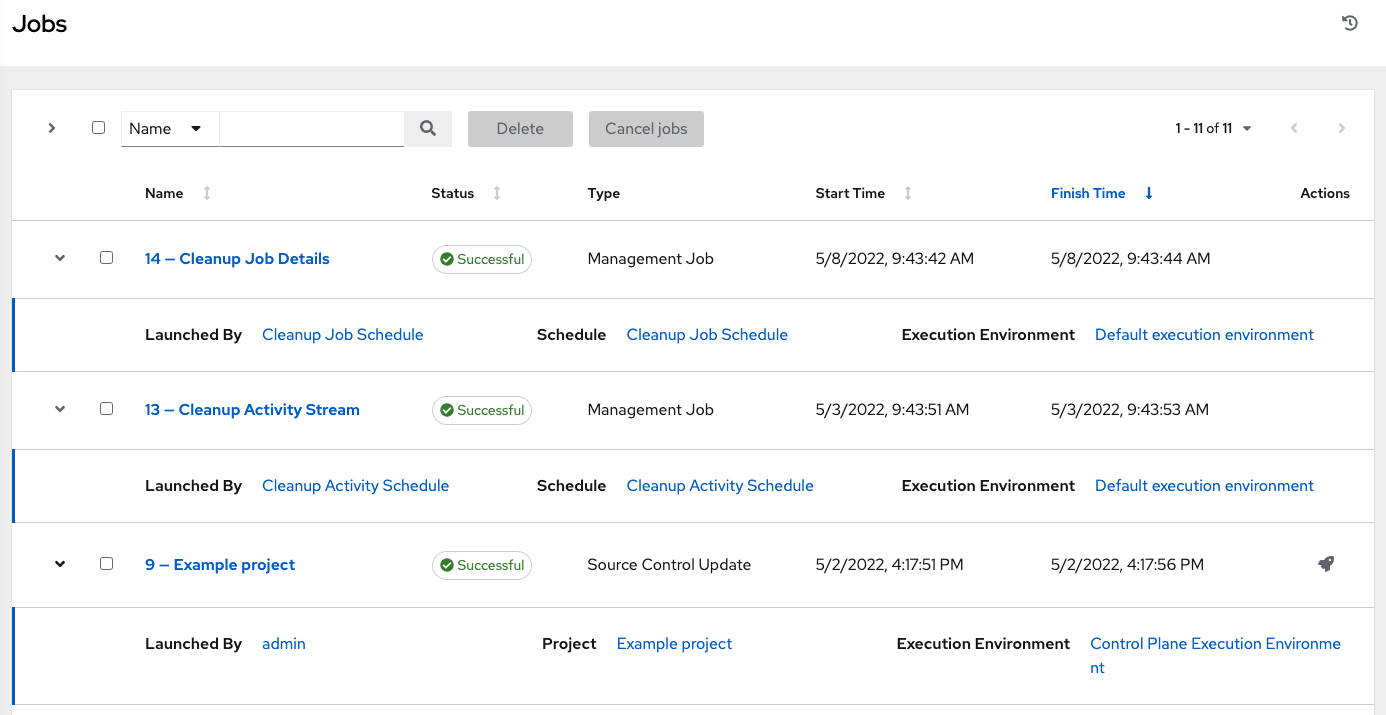
Actions you can take from this screen include viewing the details and standard output of a particular job, relaunching ( ) jobs, or removing selected jobs. The relaunch operation only applies to relaunches of playbook runs and does not apply to project/inventory updates, system jobs, workflow jobs, etc.
) jobs, or removing selected jobs. The relaunch operation only applies to relaunches of playbook runs and does not apply to project/inventory updates, system jobs, workflow jobs, etc.
When a job relaunches, you are directed the Jobs Output screen as the job runs. Clicking on any type of job also takes you to the Job Output View for that job, where you can filter jobs by various criteria:
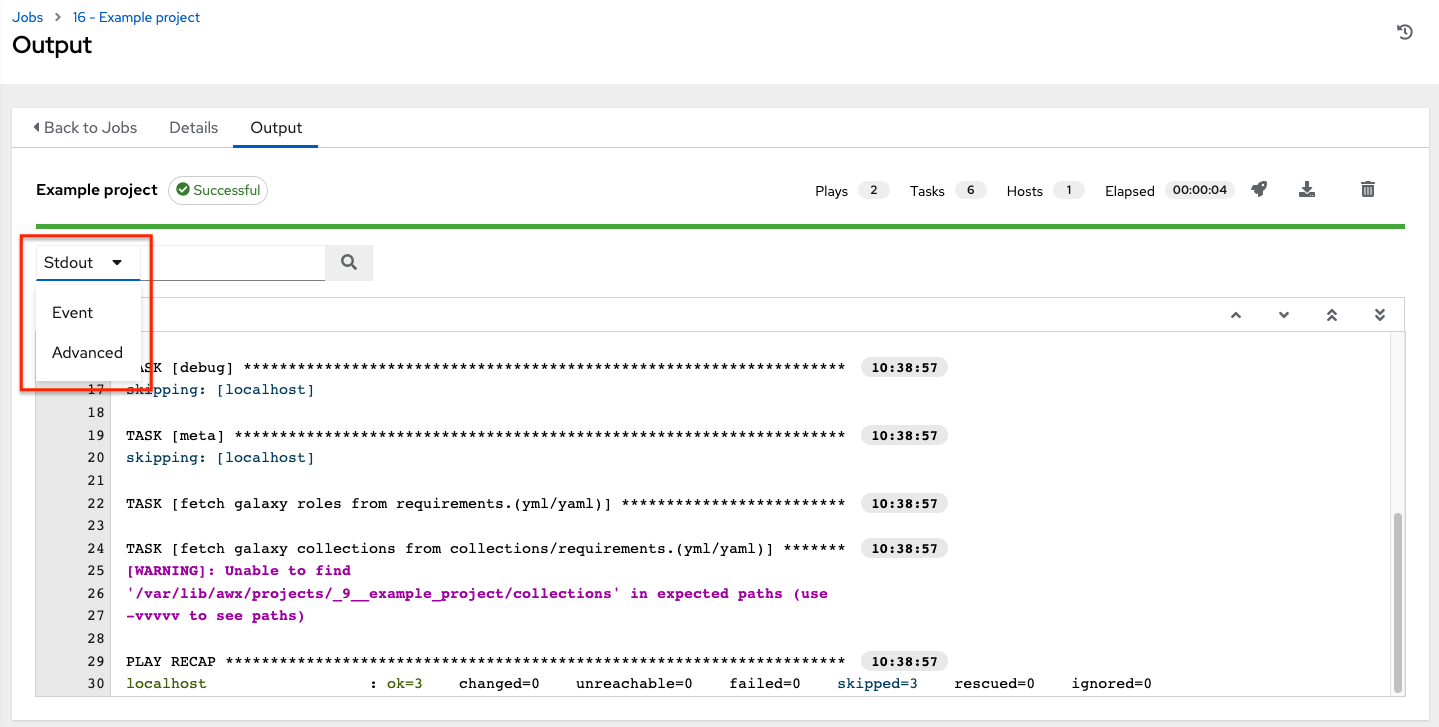
The Stdout option is the default display that shows the job processes and output
The Event option allows you to filter by the event(s) of interest, such as errors, host failures, host retries, items skipped, etc. You can include as many events in the filter as necessary.

The Advanced option is a refined search that allows you a combination of including or excluding criteria, searching by key, or by lookup type. For details about using Search, refer to the Search chapter.
26.1. Inventory Sync Jobs¶
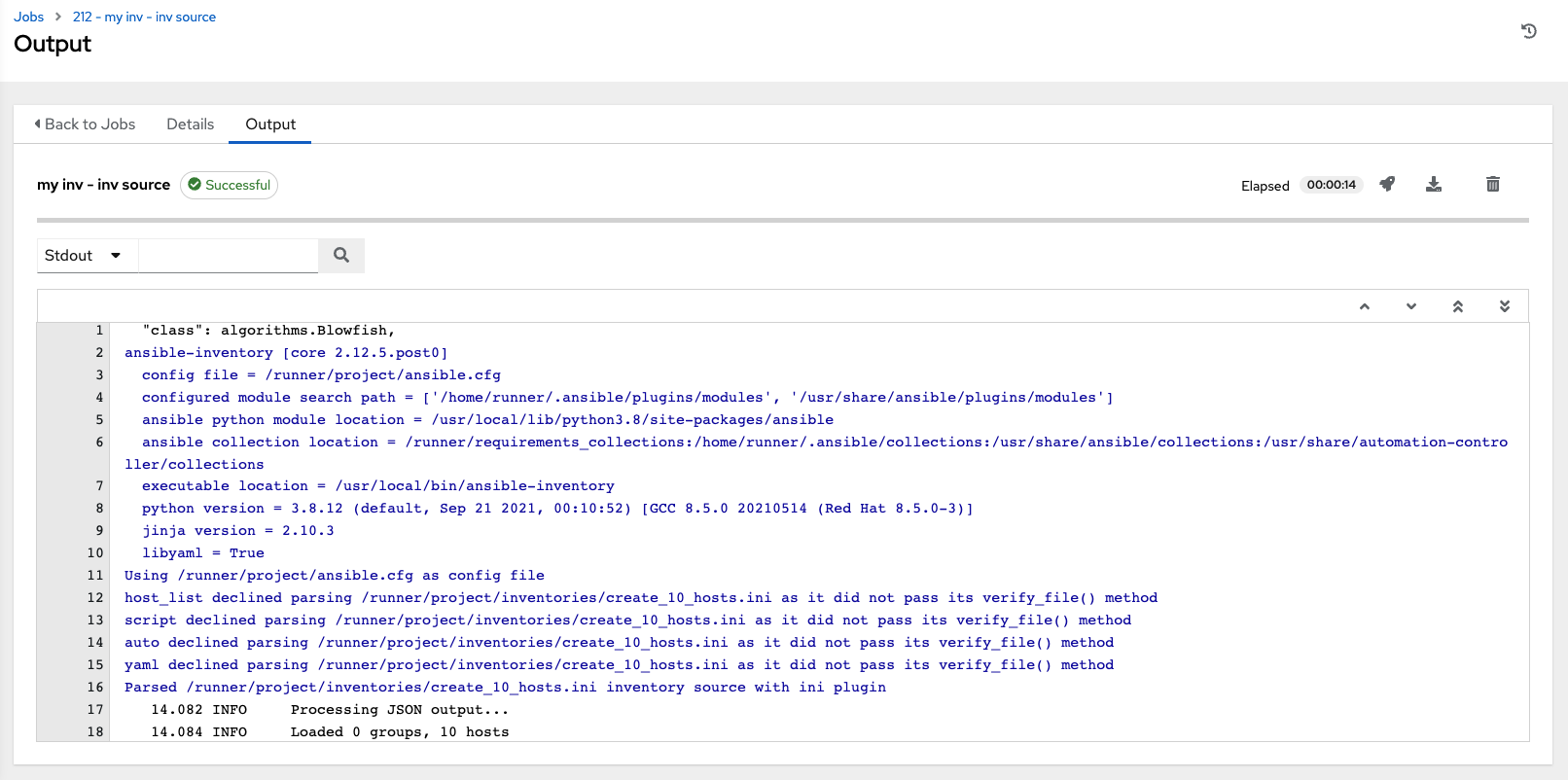
When an inventory sync is executed, the full results automatically display in the Output tab. This shows the same information you would see if you ran it through the Ansible command line, and can be useful for debugging. The ANSIBLE_DISPLAY_ARGS_TO_STDOUT is set to False by default for all playbook runs. This matches Ansible's default behavior. This does not display task arguments in task headers in the Job Detail interface to avoid leaking certain sensitive module parameters to stdout. If you wish to restore the prior behavior (despite the security implications), you can set ANSIBLE_DISPLAY_ARGS_TO_STDOUT to True via the AWX_TASK_ENV configuration setting. For more details, refer to the ANSIBLE_DISPLAY_ARGS_TO_STDOUT.
The icons at the top right corner of the Output tab allow you to relaunch (), download ( ) the job output, or delete (
) the job output, or delete ( ) the job.
) the job.
注釈
An inventory update can be performed while a related job is running. In cases where you have a big project (around 10 GB), disk space on /tmp may be an issue.
26.1.1. Inventory sync details¶
Access the Details tab to provide details about the job execution.
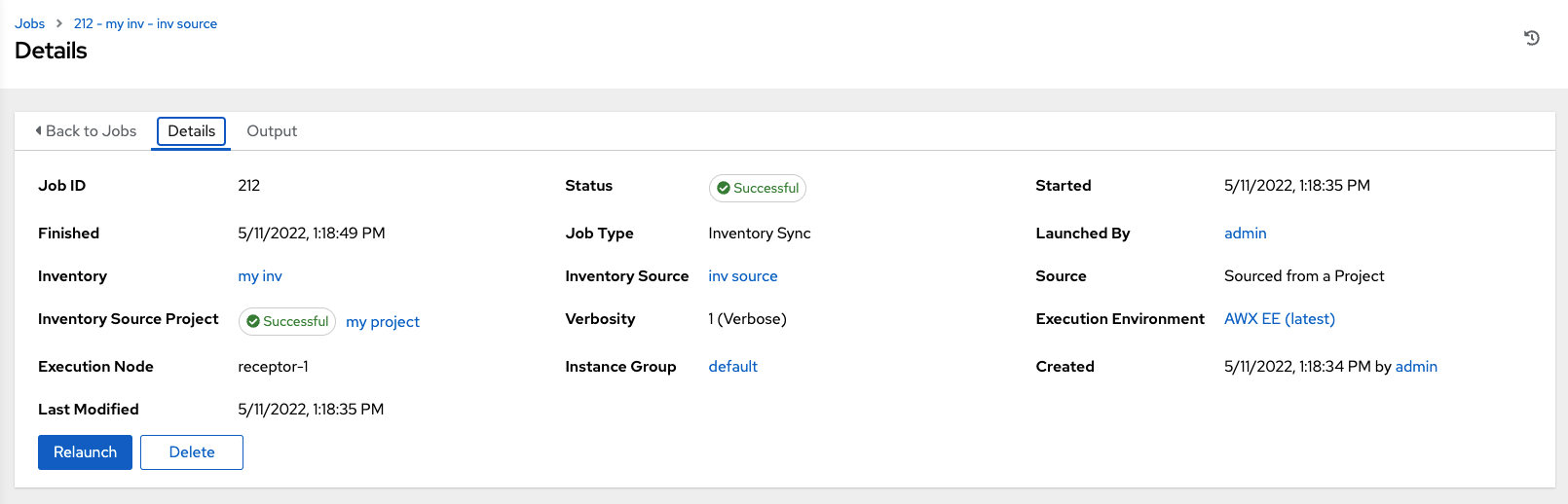
Notable details of the job executed are:
Status: Can be any of the following:
Pending - The inventory sync has been created, but not queued or started yet. Any job, not just inventory source syncs, will stay in pending until it’s actually ready to be run by the system. Reasons for inventory source syncs not being ready include dependencies that are currently running (all dependencies must be completed before the next step can execute), or there is not enough capacity to run in the locations it is configured to.
Waiting - The inventory sync is in the queue waiting to be executed.
Running - The inventory sync is currently in progress.
Successful - The inventory sync job succeeded.
Failed - The inventory sync job failed.
Inventory: The name of the associated inventory group.
Source: The type of cloud inventory.
Inventory Source Project: The project used as the source of this inventory sync job.
Execution Environment: The execution environment used.
Execution node: The node used to execute the job.
Instance Group: The name of the instance group used with this job (controller is the default instance group).
By clicking on these items, where appropriate, you can view the corresponding job templates, projects, and other objects.
26.2. SCM Inventory Jobs¶
When an inventory sourced from an SCM is executed, the full results automatically display in the Output tab. This shows the same information you would see if you ran it through the Ansible command line, and can be useful for debugging. The icons at the top right corner of the Output tab allow you to relaunch (), download () the job output, or delete () the job.
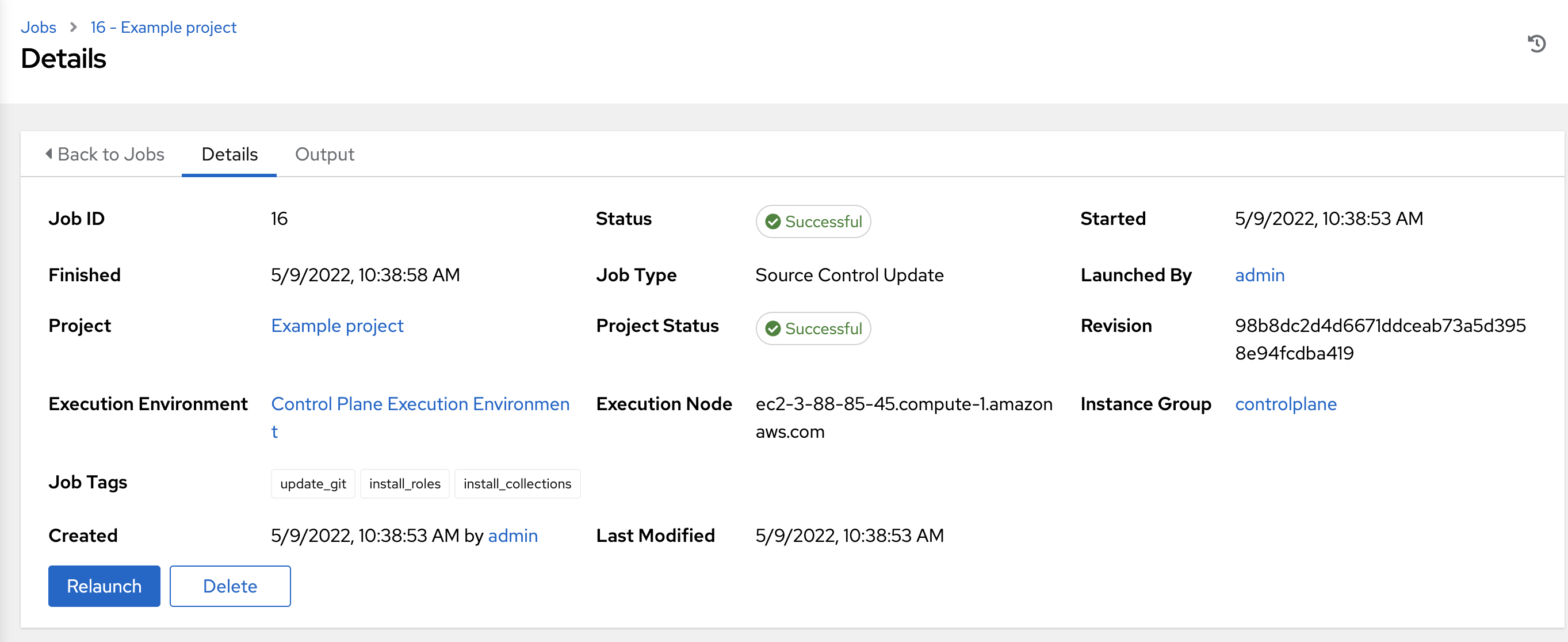
26.2.1. SCM inventory details¶
Access the Details tab to provide details about the job execution and its associated project.
Notable details of the job executed are:
Status: Can be any of the following:
Pending - The SCM job has been created, but not queued or started yet. Any job, not just SCM jobs, will stay in pending until it’s actually ready to be run by the system. Reasons for SCM jobs not being ready include dependencies that are currently running (all dependencies must be completed before the next step can execute), or there is not enough capacity to run in the locations it is configured to.
Waiting - The SCM job is in the queue waiting to be executed.
Running - The SCM job is currently in progress.
Successful - The last SCM job succeeded.
Failed - The last SCM job failed.
Job Type: SCM jobs display Source Control Update.
Project: The name of the project.
Project Status: Indicates whether the associated project was successfully updated.
Revision: Indicates the revision number of the sourced project that was used in this job.
Execution Environment: Specifies the execution environment used to run this job.
Execution Node: Indicates the node on which the job ran.
Instance Group: Indicates the instance group on which the job ran, if specified.
Job Tags: Tags show the various job operations executed.
By clicking on these items, where appropriate, you can view the corresponding job templates, projects, and other objects.
26.3. Playbook Run Jobs¶
When a playbook is executed, the full results automatically display in the Output tab. This shows the same information you would see if you ran it through the Ansible command line, and can be useful for debugging.
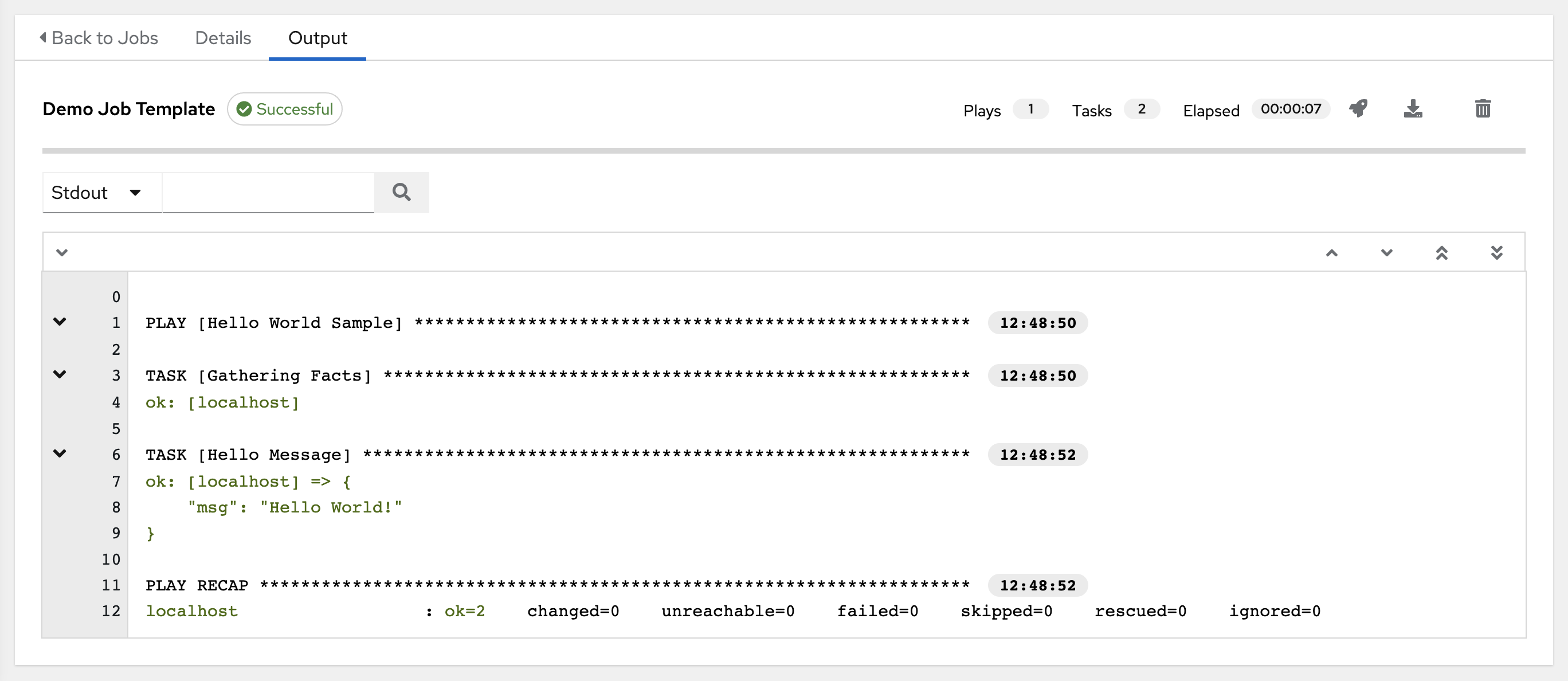
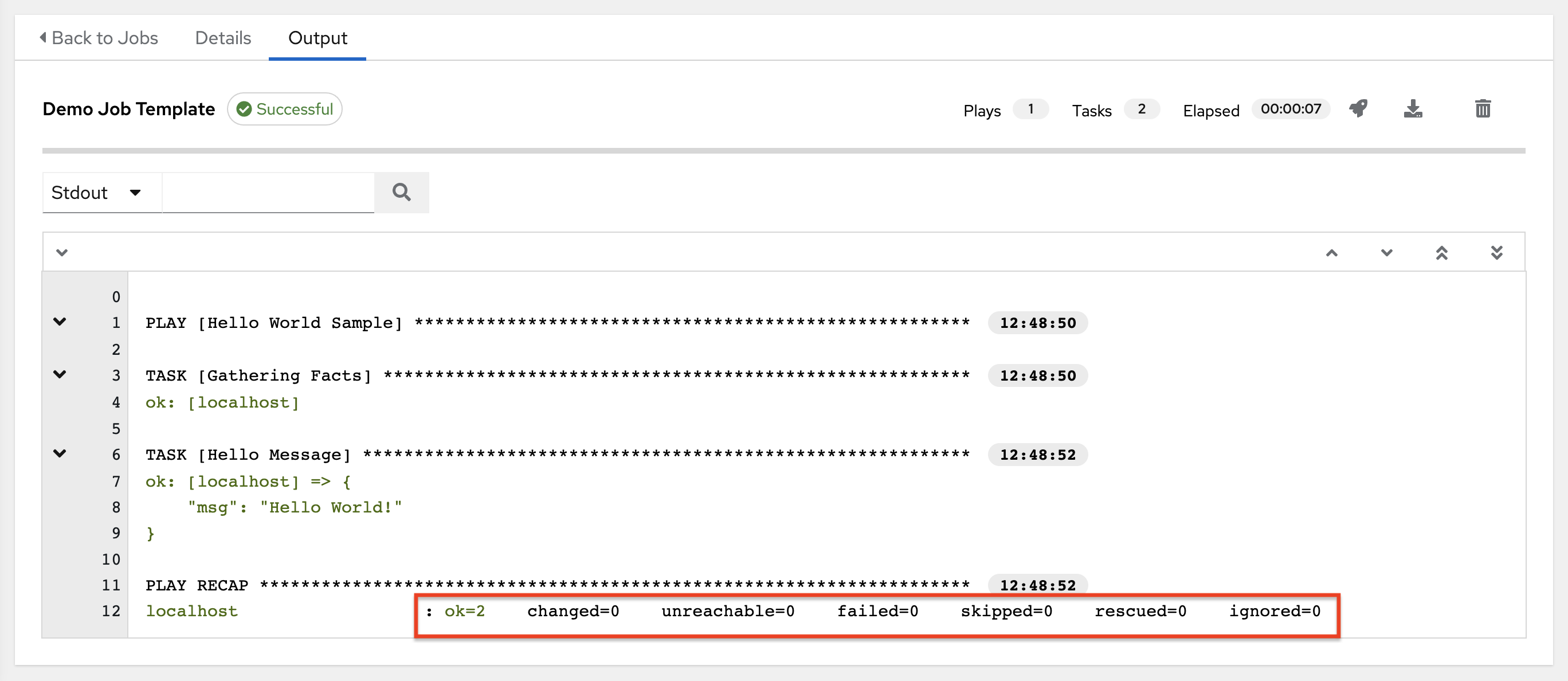
The events summary captures a tally of events that were run as part of this playbook:
the number of times this playbook has ran in the Plays field
the number of tasks associated with this playbook in the Tasks field
the number of hosts associated with this playbook in the Hosts field
the amount of time it took to complete the playbook run in the Elapsed field

The icons next to the events summary allow you to relaunch (), download () the job output, or delete () the job.
The host status bar runs across the top of the Output view. Hover over a section of the host status bar and the number of hosts associated with that particular status displays.

The output for a Playbook job is also accessible after launching a job from the Jobs tab of its Job Templates page.
Clicking on the various line item tasks in the output, you can view its host details.
26.3.1. Search¶
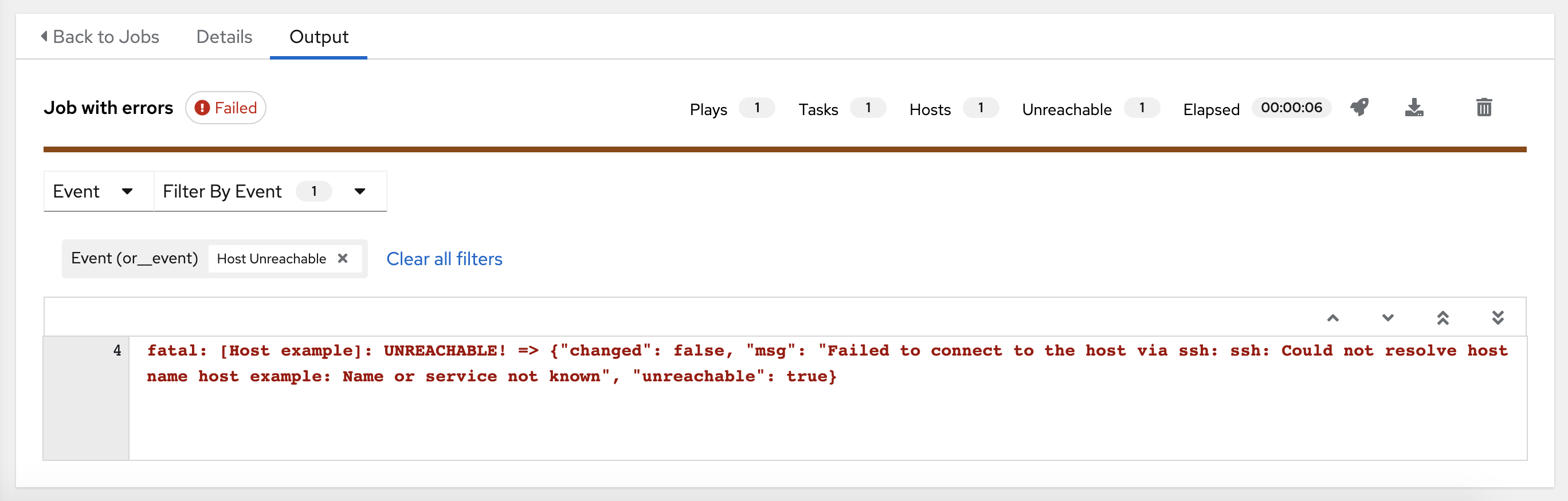
Use Search to look up specific events, hostnames, and their statuses. To filter only certain hosts with a particular status, specify one of the following valid statuses:
OK: the playbook task returned "Ok".
Changed: the playbook task actually executed. Since Ansible tasks should be written to be idempotent, tasks may exit successfully without executing anything on the host. In these cases, the task would return Ok, but not Changed.
Failed: the task failed. Further playbook execution was stopped for this host.
Unreachable: the host was unreachable from the network or had another fatal error associated with it.
Skipped: the playbook task was skipped because no change was necessary for the host to reach the target state.
Rescued: introduced in Ansible 2.8, this shows the tasks that failed and then executes a rescue section.
Ignored: introduced in Ansible 2.8, this shows the tasks that failed and have
ignore_errors: yesconfigured.
These statuses also display at bottom of each Stdout pane, in a group of "stats" called the Host Summary fields.
The example below shows a search with only unreachable hosts.
For more details about using the Search, refer to the Search chapter.
The standard output view displays all the events that occur on a particular job. By default, all rows are expanded so that all the details are displayed. Use the collapse-all button (![]() ) to switch to a view that only contains the headers for plays and tasks. Click the (
) to switch to a view that only contains the headers for plays and tasks. Click the (![]() ) button to view all lines of the standard output.
) button to view all lines of the standard output.
Alternatively, you can display all the details of a specific play or task by clicking on the arrow icons next to them. Click an arrow from sideways to downward to expand the lines associated with that play or task. Click the arrow back to the sideways position to collapse and hide the lines.
Things to note when viewing details in the expand/collapse mode:
Each displayed line that is not collapsed has a corresponding line number and start time.
An expand/collapse icon is at the start of any play or task after the play or task has completed.
If querying for a particular play or task, it will appear collapsed at the end of its completed process.
In some cases, an error message will appear, stating that the output may be too large to display. This occurs when there are more than 4000 events. Use the search and filter for specific events to bypass the error.
Click on a line of an event from the Standard Out pane and a Host Events dialog displays in a separate window. This window shows the host that was affected by that particular event.
注釈
Upgrading to the latest versions of Ansible Automation Platform involves progressively migrating all historical playbook output and events. This migration process is gradual, and happens automatically in the background after installation is complete. Installations with very large amounts of historical job output (tens, or hundreds of GB of output) may notice missing job output until migration is complete. Most recent data will show up at the top of the output, followed by older events. Migrating jobs with a large amount of events may take longer than jobs with a smaller amount.
26.3.2. Host Details¶
The Host Details dialog shows information about the host affected by the selected event and its associated play and task:
the Host
the Status
the type of run in the Play field
the type of Task
if applicable, the Ansible Module for the task, and any arguments for that module
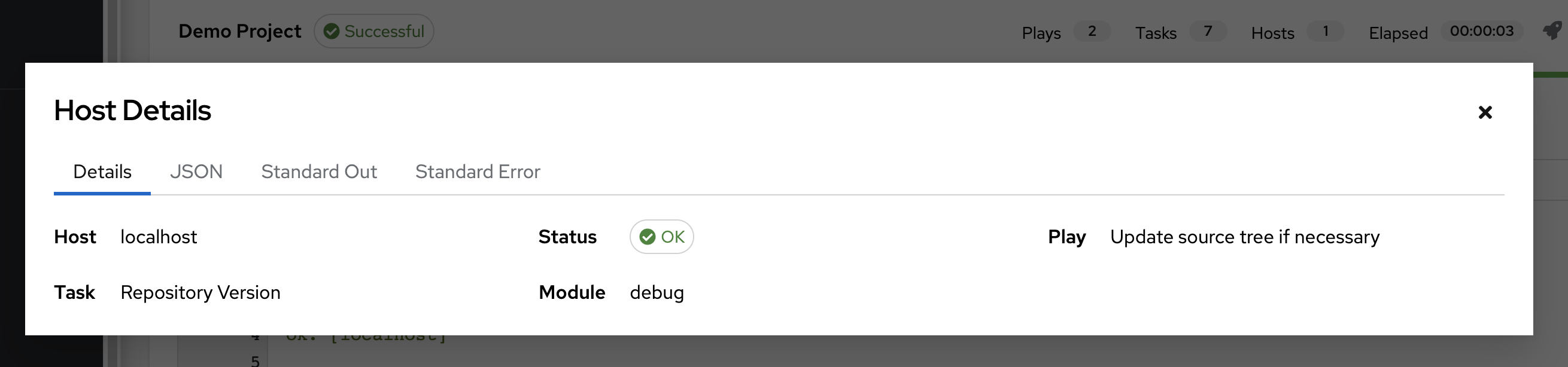
To view the results in JSON format, click on the JSON tab. To view the output of the task, click the Standard Out. To view errors from the output, click Standard Error.
26.3.3. Playbook run details¶
Access the Details tab to provide details about the job execution.
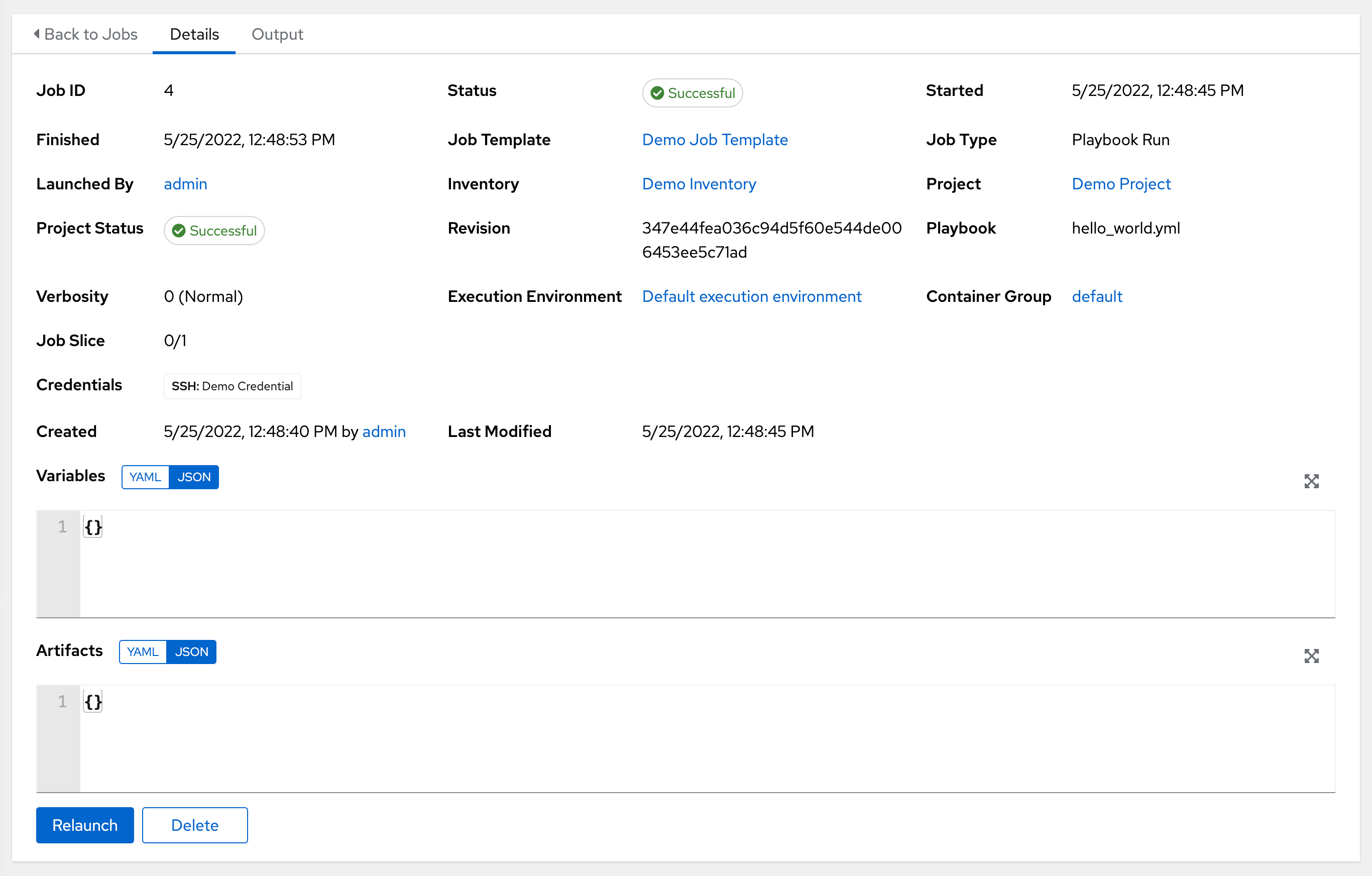
Notable details of the job executed are:
Status: Can be any of the following:
Pending - The playbook run has been created, but not queued or started yet. Any job, not just playbook runs, will stay in pending until it is actually ready to be run by the system. Reasons for playbook runs not being ready include dependencies that are currently running (all dependencies must be completed before the next step can execute), or there is not enough capacity to run in the locations it is configured to.
Waiting - The playbook run is in the queue waiting to be executed.
Running - The playbook run is currently in progress.
Successful - The last playbook run succeeded.
Failed - The last playbook run failed.
Job Template: The name of the job template from which this job was launched.
Inventory: The inventory selected to run this job against.
Project: The name of the project associated with the launched job.
Project Status: The status of the project associated with the launched job.
Playbook: The playbook used to launch this job.
Execution Environment: The name of the execution environment used in this job.
Container Group: The name of the container group used in this job.
Credentials: The credential(s) used in this job.
Extra Variables: Any extra variables passed when creating the job template are displayed here.
By clicking on these items, where appropriate, you can view the corresponding job templates, projects, and other objects.
26.4. Automation Controller Capacity Determination and Job Impact¶
This section describes how to determine capacity for instance groups and its impact to your jobs. For container groups, see Container capacity limits in the Automation Controller Administration Guide.
The automation controller capacity system determines how many jobs can run on an instance given the amount of resources available to the instance and the size of the jobs that are running (referred to as Impact). The algorithm used to determine this is based entirely on two things:
How much memory is available to the system (
mem_capacity)How much CPU is available to the system (
cpu_capacity)
Capacity also impacts Instance Groups. Since Groups are made up of instances, likewise, instances can be assigned to multiple groups. This means that impact to one instance can potentially affect the overall capacity of other Groups.
Instance Groups (not instances themselves) can be assigned to be used by jobs at various levels (see Clustering). When the Task Manager is preparing its graph to determine which group a job will run on, it will commit the capacity of an Instance Group to a job that hasn’t or isn’t ready to start yet.
Finally, in smaller configurations, if only one instance is available for a job to run, the Task Manager will allow that job to run on the instance even if it pushes the instance over capacity. This guarantees that jobs themselves won't get stuck as a result of an under-provisioned system.
Therefore, Capacity and Impact is not a zero-sum system relative to jobs and instances/Instance Groups.
For information on sliced jobs and their impact to capacity, see Job slice execution behavior.
26.4.1. Resource determination for capacity algorithm¶
The capacity algorithms are defined in order to determine how many forks a system is capable of running simultaneously. This controls how many systems Ansible itself will communicate with simultaneously. Increasing the number of forks a automation controller system is running will, in general, allow jobs to run faster by performing more work in parallel. The trade-off is that this will increase the load on the system, which could cause work to slow down overall.
Automation controller can operate in two modes when determining capacity. mem_capacity (the default) will allow you to over-commit CPU resources while protecting the system from running out of memory. If most of your work is not CPU-bound, then selecting this mode will maximize the number of forks.
26.4.1.1. Memory relative capacity¶
mem_capacity is calculated relative to the amount of memory needed per fork. Taking into account the overhead for internal components, this comes out to be about 100MB per fork. When considering the amount of memory available to Ansible jobs, the capacity algorithm will reserve 2GB of memory to account for the presence of other services. The algorithm formula for this is:
(mem - 2048) / mem_per_fork
As an example:
(4096 - 2048) / 100 == ~20
Therefore, a system with 4GB of memory would be capable of running 20 forks. The value mem_per_fork can be controlled by setting the settings value (or environment variable) SYSTEM_TASK_FORKS_MEM, which defaults to 100.
26.4.1.2. CPU relative capacity¶
Often, Ansible workloads can be fairly CPU-bound. In these cases, sometimes reducing the simultaneous workload allows more tasks to run faster and reduces the average time-to-completion of those jobs.
Just as the mem_capacity algorithm uses the amount of memory need per fork, the cpu_capacity algorithm looks at the amount of CPU resources is needed per fork. The baseline value for this is 4 forks per core. The algorithm formula for this is:
cpus * fork_per_cpu
For example, a 4-core system:
4 * 4 == 16
The value fork_per_cpu can be controlled by setting the settings value (or environment variable) SYSTEM_TASK_FORKS_CPU which defaults to 4.
26.4.2. Capacity job impacts¶
When selecting the capacity, it's important to understand how each job type affects capacity.
It's helpful to understand what forks mean to Ansible: https://www.ansible.com/blog/ansible-performance-tuning (see the section on "Know Your Forks").
The default forks value for Ansible is 5. However, if automation controller knows that you're running against fewer systems than that, then the actual concurrency value will be lower.
When a job is run, automation controller will add 1 to the number of forks selected to compensate for the Ansible parent process. So if you are running a playbook against 5 systems with a forks value of 5, then the actual forks value from the perspective of Job Impact will be 6.
26.4.2.1. Impact of job types in automation controller¶
Jobs and Ad-hoc jobs follow the above model, forks + 1. If you set a fork value on your job template, your job capacity value will be the minimum of the forks value supplied, and the number of hosts that you have, plus one. The plus one is to account for the parent Ansible process.
Instance capacity determines which jobs get assigned to any specific instance. Jobs and ad hoc commands use more capacity if they have a higher forks value.
Other job types have a fixed impact:
Inventory Updates: 1
Project Updates: 1
System Jobs: 5
If you don’t set a forks value on your job template, your job will use Ansible’s default forks value of five. Even though Ansible defaults to five forks, it will use fewer if your job has fewer than five hosts. In general, setting a forks value higher than what the system is capable of could cause trouble by running out of memory or over-committing CPU. So, the job template fork values that you use should fit on the system. If you have playbooks using 1000 forks but none of your systems individually has that much capacity, then your systems are undersized and at risk of performance or resource issues.
26.4.2.2. Selecting the right capacity¶
Selecting a capacity out of the CPU-bound or the memory-bound capacity limits is, in essence, selecting between the minimum or maximum number of forks. In the above examples, the CPU capacity would allow a maximum of 16 forks while the memory capacity would allow 20. For some systems, the disparity between these can be large and often times you may want to have a balance between these two.
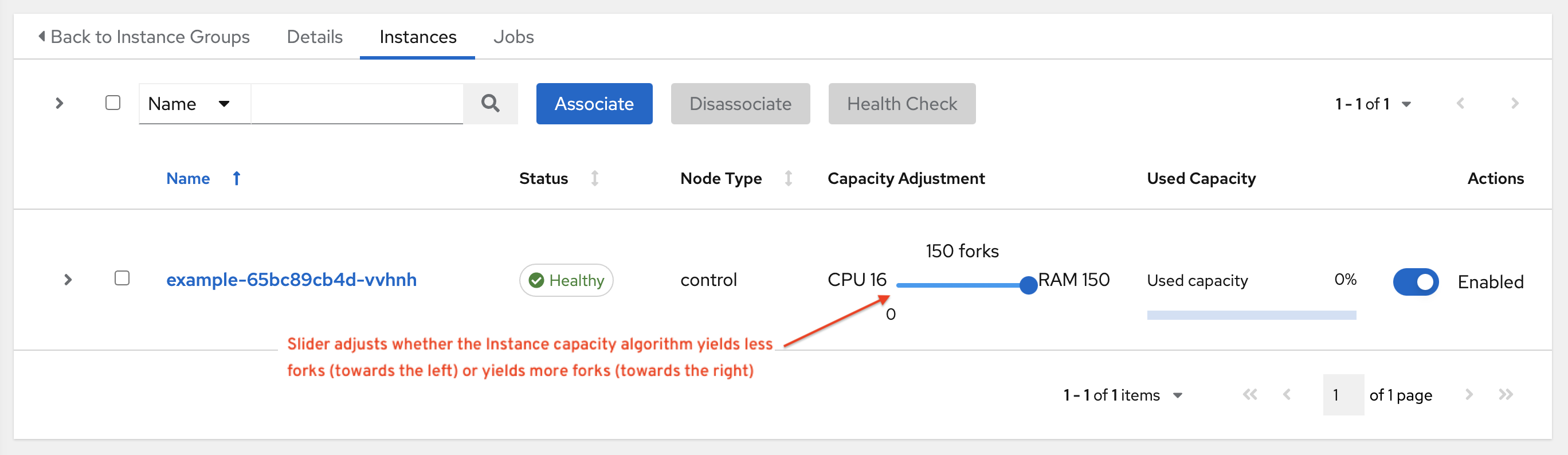
The instance field capacity_adjustment allows you to select how much of one or the other you want to consider. It is represented as a value between 0.0 and 1.0. If set to a value of 1.0, then the largest value will be used. The above example involves memory capacity, so a value of 20 forks would be selected. If set to a value of 0.0 then the smallest value will be used. A value of 0.5 would be a 50/50 balance between the two algorithms which would be 18:
16 + (20 - 16) * 0.5 == 18
To view or edit the capacity in the user interface, select the Instances tab of the Instance Group.
26.5. Job branch overriding¶
Projects specify the branch, tag, or reference to use from source control in the scm_branch field. These are represented by the values specified in the Project Details fields as shown.
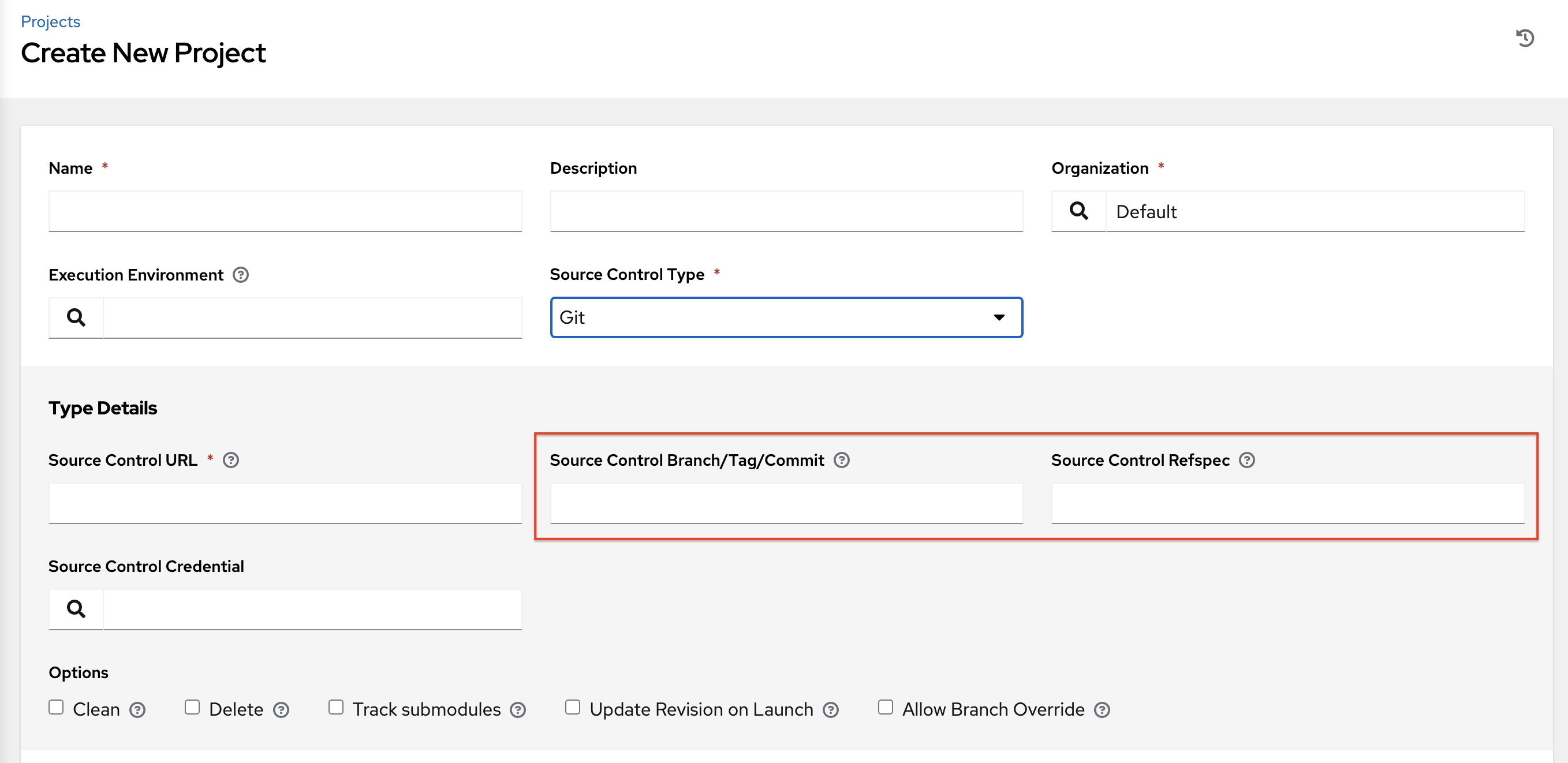
Projects have the option to "Allow Branch Override". When checked, project admins can delegate branch selection to the job templates that use that project (requiring only project use_role).

26.5.1. Source tree copy behavior¶
Every job run has its own private data directory. This directory contains a copy of the project source tree for the given
scm_branch the job is running. Jobs are free to make changes to the project folder and make use of those changes while it is still running. This folder is temporary and is cleaned up at the end of the job run.
If Clean is checked, automation controller discards modified files in its local copy of the repository through use of the force parameter in its respective Ansible modules pertaining to git or Subversion.

26.5.2. Project revision behavior¶
Typically, during a project update, the revision of the default branch (specified in the SCM Branch field of the project) is stored when updated, and jobs using that project will employ this revision. Providing a non-default SCM Branch (not a commit hash or tag) in a job, the newest revision is pulled from the source control remote immediately before the job starts. This revision is shown in the Source Control Revision field of the job and its respective project update.
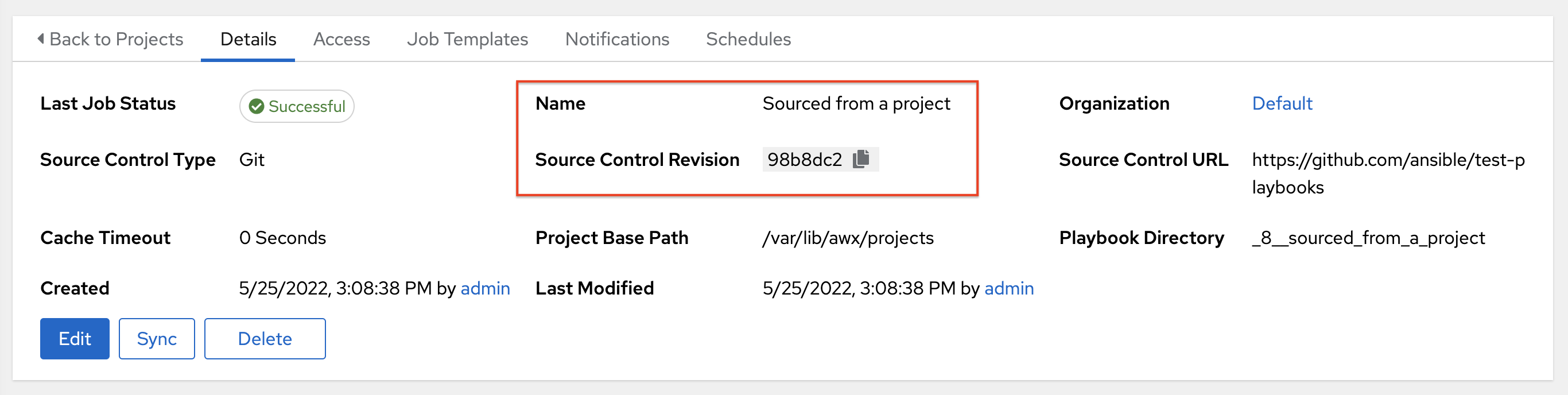
Consequently, offline job runs are impossible for non-default branches. To be sure that a job is running a static version from source control, use tags or commit hashes. Project updates do not save the revision of all branches, only the project default branch.
The SCM Branch field is not validated, so the project must update to assure it is valid. If this field is provided or prompted for, the Playbook field of job templates will not be validated, and you will have to launch the job template in order to verify presence of the expected playbook.
26.5.3. Git Refspec¶
The SCM Refspec field specifies which extra references the update should download from the remote. Examples are:
refs/*:refs/remotes/origin/*: fetches all references, including remotes of the remote
refs/pull/*:refs/remotes/origin/pull/*(GitHub-specific): fetches all refs for all pull requests
refs/pull/62/head:refs/remotes/origin/pull/62/head: fetches the ref for that one GitHub pull request
For large projects, you should consider performance impact when using the 1st or 2nd examples here.
The SCM Refspec parameter affects the availability of the project branch, and can allow access to references not otherwise available. The examples above allow the user to supply a pull request from the SCM Branch, which would not be possible without the SCM Refspec field.
The Ansible git module fetches refs/heads/* by default. This means that a project's branches and tags (and commit hashes therein) can be used as the SCM Branch if SCM Refspec is blank. The value specified in the SCM Refspec field affects which SCM Branch fields can be used as overrides. Project updates (of any type) will perform an extra git fetch command to pull that refspec from the remote.
For example: You could set up a project that allows branch override with the 1st or 2nd refspec example --> Use this in a job template that prompts for the SCM Branch --> A client could launch the job template when a new pull request is created, providing the branch pull/N/head --> The job template would run against the provided GitGub pull request reference.
For more information on the Ansible git module, see https://docs.ansible.com/ansible/latest/modules/git_module.html.