16. 作业模板¶
job template 是用于运行 Ansible 作业的定义和参数集。作业模板对于多次执行同一作业很有用。作业模板还可促进 Ansible playbook 内容的重复使用和团队之间的协作。虽然 REST API 允许直接执行作业,但 Tower 要求您先创建一个作业模板。
(![]() ) 菜单会打开当前可用的作业模板列表。默认视图为折叠状态 (Compact),显示模板名称、模板类型和使用该模板运行的作业的状态,但您可以点击 Expanded 查看更多信息。该列表按名称字母顺序排序,但您可以按照其他条件排序,或者根据模板的不同字段和属性进行搜索。
) 菜单会打开当前可用的作业模板列表。默认视图为折叠状态 (Compact),显示模板名称、模板类型和使用该模板运行的作业的状态,但您可以点击 Expanded 查看更多信息。该列表按名称字母顺序排序,但您可以按照其他条件排序,或者根据模板的不同字段和属性进行搜索。
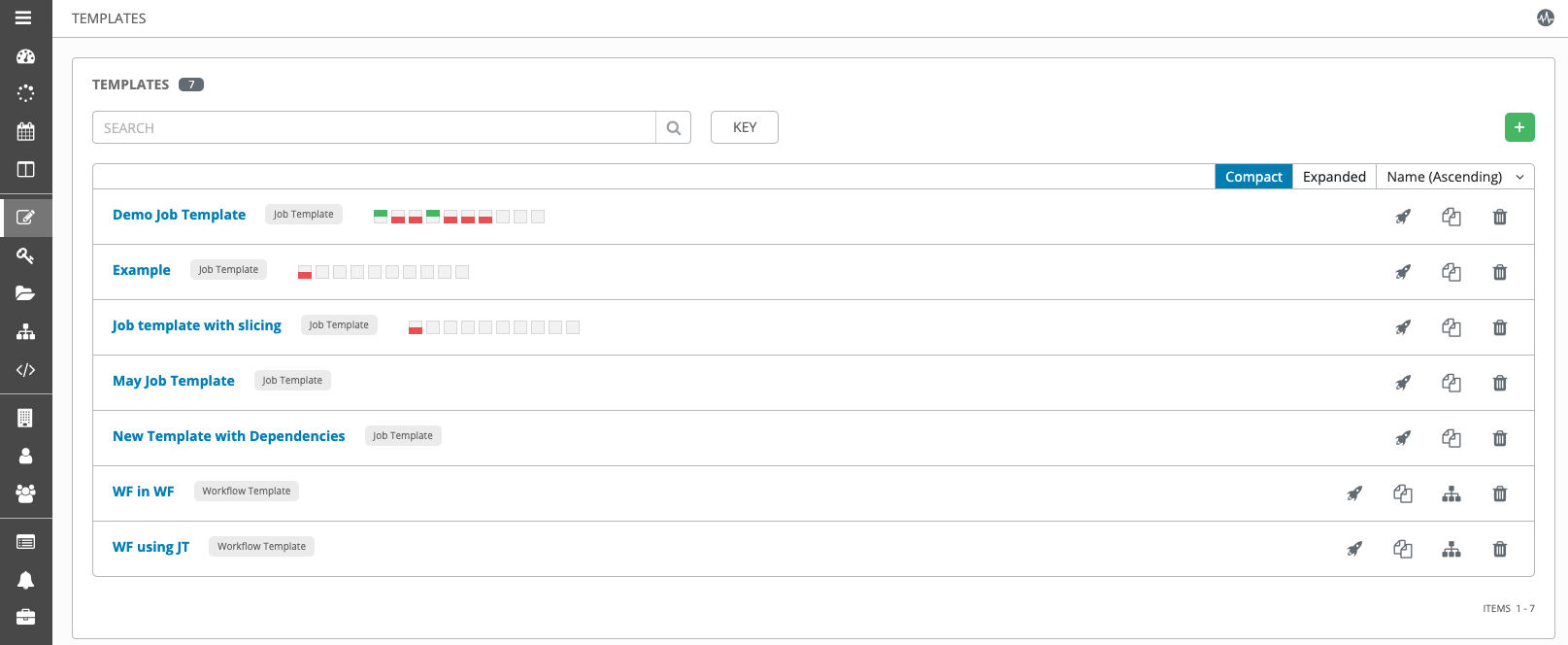
在此屏幕中,您可以启动 ( )、复制 (
)、复制 (  ) 和删除 (
) 和删除 (  ) 作业模板。删除作业模板前,请确保它不在工作流作业模板中使用。
) 作业模板。删除作业模板前,请确保它不在工作流作业模板中使用。
注解
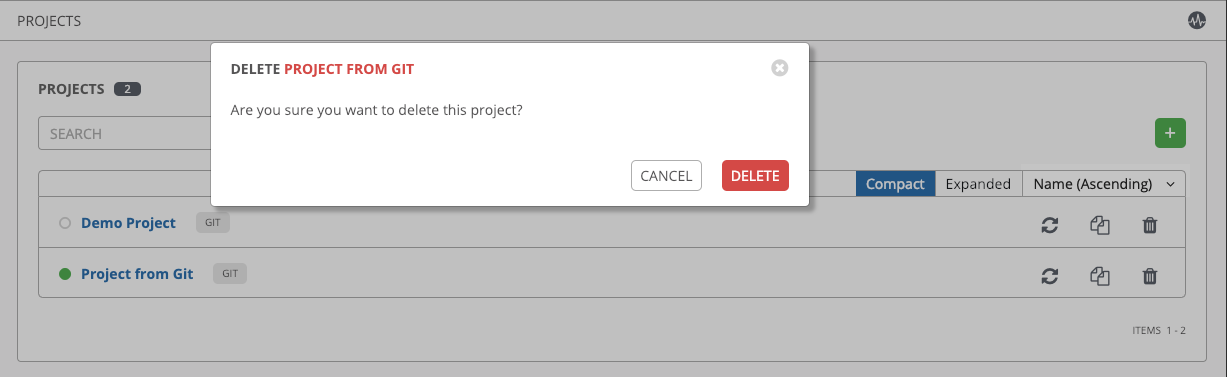
如果删除了由其他工作项目使用的项,则会打开一条信息,列出会受到删除影响的项,并提示您确认删除。一些界面会包括无效的或以前已被删除的项,因此它们将无法运行。以下是这类信息的一个示例:
注解
作业模板可以用来构建工作流模板。旁边显示工作流可视化工具 (![]() ) 图标的模板为工作流模板。点击此图标可通过图形方式构建工作流。作业模板中的许多参数允许您启用 Prompt on Launch,这些参数可在工作流级别进行修改,且不会影响在作业模板级别分配的值。如需了解相关说明,请参阅 工作流可视化工具 部分。
) 图标的模板为工作流模板。点击此图标可通过图形方式构建工作流。作业模板中的许多参数允许您启用 Prompt on Launch,这些参数可在工作流级别进行修改,且不会影响在作业模板级别分配的值。如需了解相关说明,请参阅 工作流可视化工具 部分。
16.1. 创建作业模板¶
要创建新作业模板,请执行以下操作:
点击
 按钮,然后从菜单列表中选择 Job Template。
按钮,然后从菜单列表中选择 Job Template。
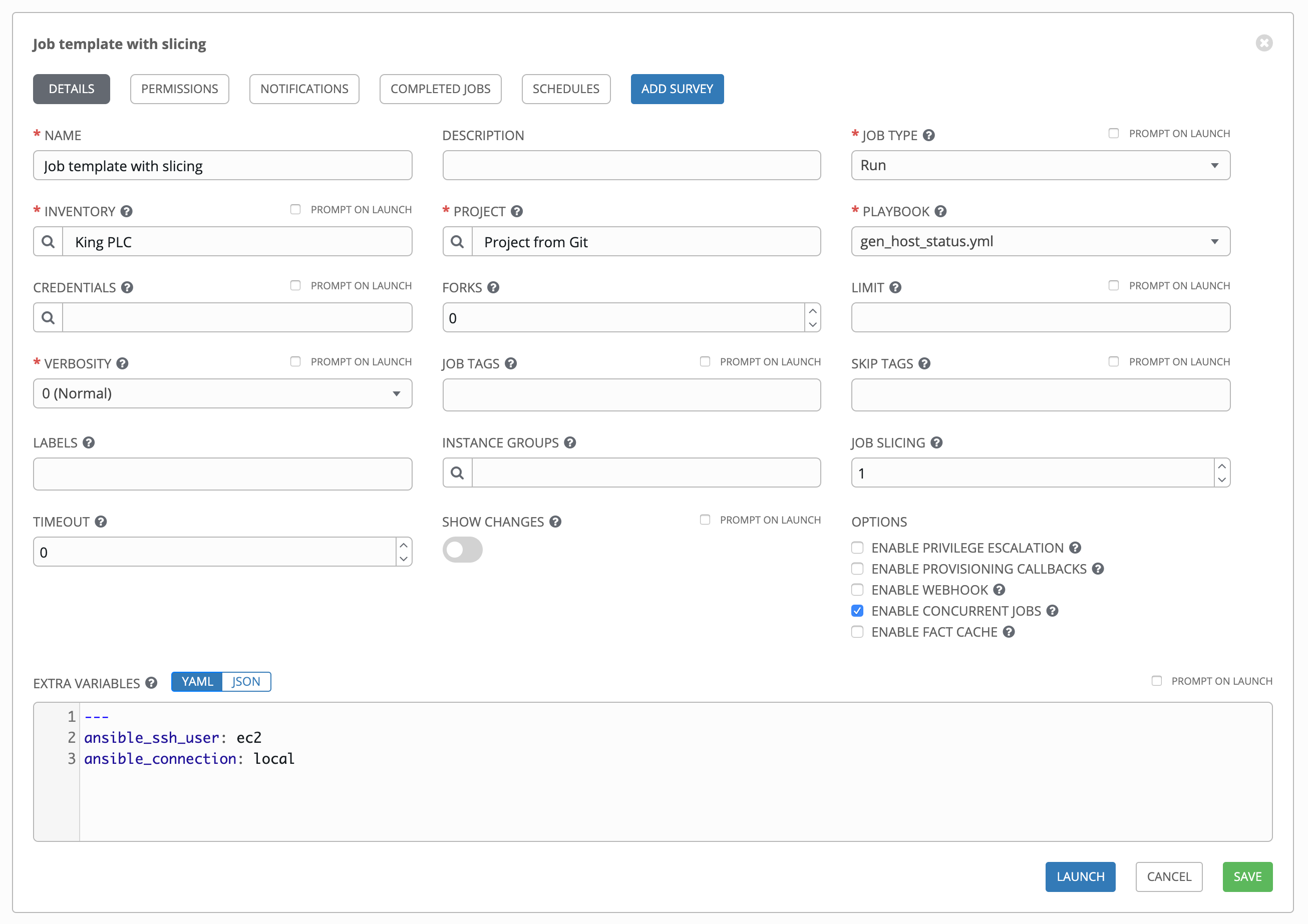
在以下字段中输入相关信息:
Name:输入作业名称。
Description:根据需要输入任意描述(可选)。
Job Type:选择作业类型:
Run:启动时执行 playbook,在所选主机上运行 Ansible 任务。
Check:执行 playbook 的“dry run”并报告将要进行的更改,而无需实际进行更改。不支持检查模式的任务将被跳过,且不会报告潜在的更改。
Prompt on Launch:如果选择此选项,即使提供了默认值,也会在启动时提示您选择运行或检查作业类型。
注解
有关作业类型的更多信息,请参阅 Ansible 文档的 Playbooks: Special Topics 部分。
Inventory:从当前登录的 Tower 用户可用的清单中选择要用于此作业模板的清单。
Prompt on Launch:如果选择此选项,即使提供了默认值,也会在启动时提示您选择要针对哪个清单来运行此作业模板。
Project:从当前登录的 Tower 用户可用的项目中选择要用于此作业模板的项目。
SCM Branch:仅当您选择允许分支覆盖的项目时,才会出现此字段。指定要在作业运行中使用的覆盖分支。如果留空,则使用项目中指定的 SCM 分支(或提交散列或标签)。有关更多详情,请参阅 job branch overriding。
Prompt on Launch:如果选择此选项,即使提供了默认值,也会在启动时提示您选择一个 SCM 分支。
Playbook:从可用的 playbook 中选择要使用这个作业模板启动的 playbook。此字段会自动填充选定项目的项目基本路径中的 playbook 名称。或者,如果未列出 playbook 的名称,您可以输入它,例如要您与该 playbook 一起运行的文件的名称(类似
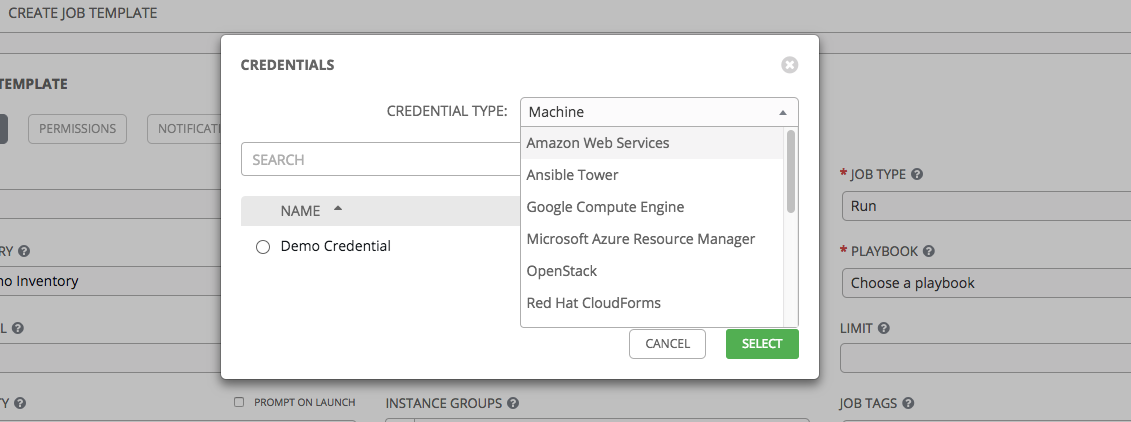
foo.yml)。如果输入无效的文件名,模板将会显示错误,或者导致作业失败。Credentials:点击
 按钮以打开单独的窗口。从可用的选项中选择要用于此作业模板的凭证。如果列表较长,请使用下拉菜单按凭证类型进行过滤。
按钮以打开单独的窗口。从可用的选项中选择要用于此作业模板的凭证。如果列表较长,请使用下拉菜单按凭证类型进行过滤。
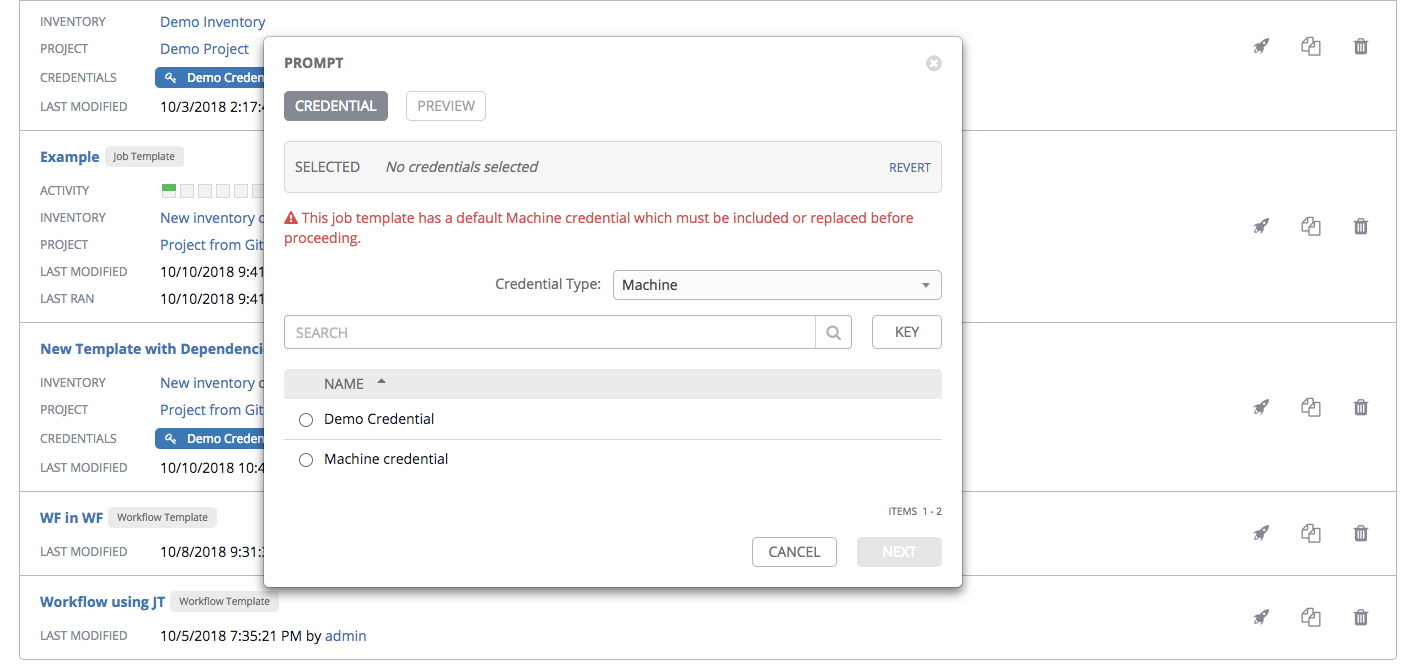
Prompt on Launch:如果选择此选项,在启动具有默认机器凭证的作业模板时,如果在启动前未将默认机器凭证替换为另一个机器凭证,您将无法在 Prompt 对话框中删除默认机器凭证。或者,您可以添加更多您认为合适的凭证。以下是此类消息的示例:
Forks:执行 playbook 时使用的并行或同步进程数量。如果为零则代表使用 Ansible 默认设置,即 5 个并行进程,除非在
/etc/ansible/ansible.cfg中被覆盖。Limit:用于进一步限制受 playbook 管理或影响的主机列表的主机模式。可以用冒号(“:”)来分隔多个模式。与核心 Ansible 一样,“a:b”表示“在组 a 或 b 中”,“a:b:&c”表示“在 a 或 b 中但必须在 c 中”,“a:!b”表示“在 a 中且一定不在 b 中”。
Prompt on Launch:如果选择此选项,即使提供了默认值,也会在启动时提示您选择一个限制。
注解
更多信息和示例请参阅 Ansible 文档中的 Patterns。
Verbosity:在 playbook 执行时,控制 Ansible 生成的输出等级。选择从 Normal 到各种 Verbose 或 Debug 设置的详细程度。此项仅出现在“详情”报告视图中。Verbose 日志记录中包括所有命令的输出。Debug 日志记录非常详细,并包含了在特定支持实例中很有用的有关 SSH 操作的信息。大多数用户不需要查看调试模式输出。
警告
详细程度 5 会导致 Tower 在作业运行时大量阻断,这可能会延迟报告作业已完成(即使它已经完成),并可能导致浏览器标签页锁定。
Prompt on Launch:如果选择此选项,即使提供了默认值,也会在启动时提示您选择一个详细程度。
Job Tags:提供以逗号分隔的 playbook 标签列表,以指定应执行 playbook 的哪些部分。有关更多信息和示例,请参阅 Ansible 文档中的 Tags。
Prompt on Launch:如果选择此选项,即使提供了默认值,也会在启动时提示您选择一个作业标签。
Skip Tags:提供以逗号分隔的 playbook 标签列表,以跳过执行 playbook 的某些任务或部分。有关更多信息和示例,请参阅 Ansible 文档中的 Tags。
Prompt on Launch:如果选择此选项,即使提供了默认值,也会在启动时提示您选择一个要跳过的标签。
Labels:提供描述此作业模板的可选标签,如“dev”或“test”。标签可用于对 Tower 显示中的作业模板和完成的作业进行分组和过滤。
在将标签添加到作业模板时会创建标签。标签使用作业模板中提供的项目关联到单个机构。如果机构成员具有编辑权限(如 admin 角色),则他们可在作业模板中创建标签。
保存作业模板后,标签会显示在 Expanded 视图的作业模板概述中。
点击标签旁边的“x”可删除它。标签被删除后,便不再与作业或作业模板关联,该标签会从机构标签列表中永久删除。
在启动时,作业会继承作业模板中的标签。如果从作业模板中删除某个标签,它也会从作业中删除。


Instance Groups:点击
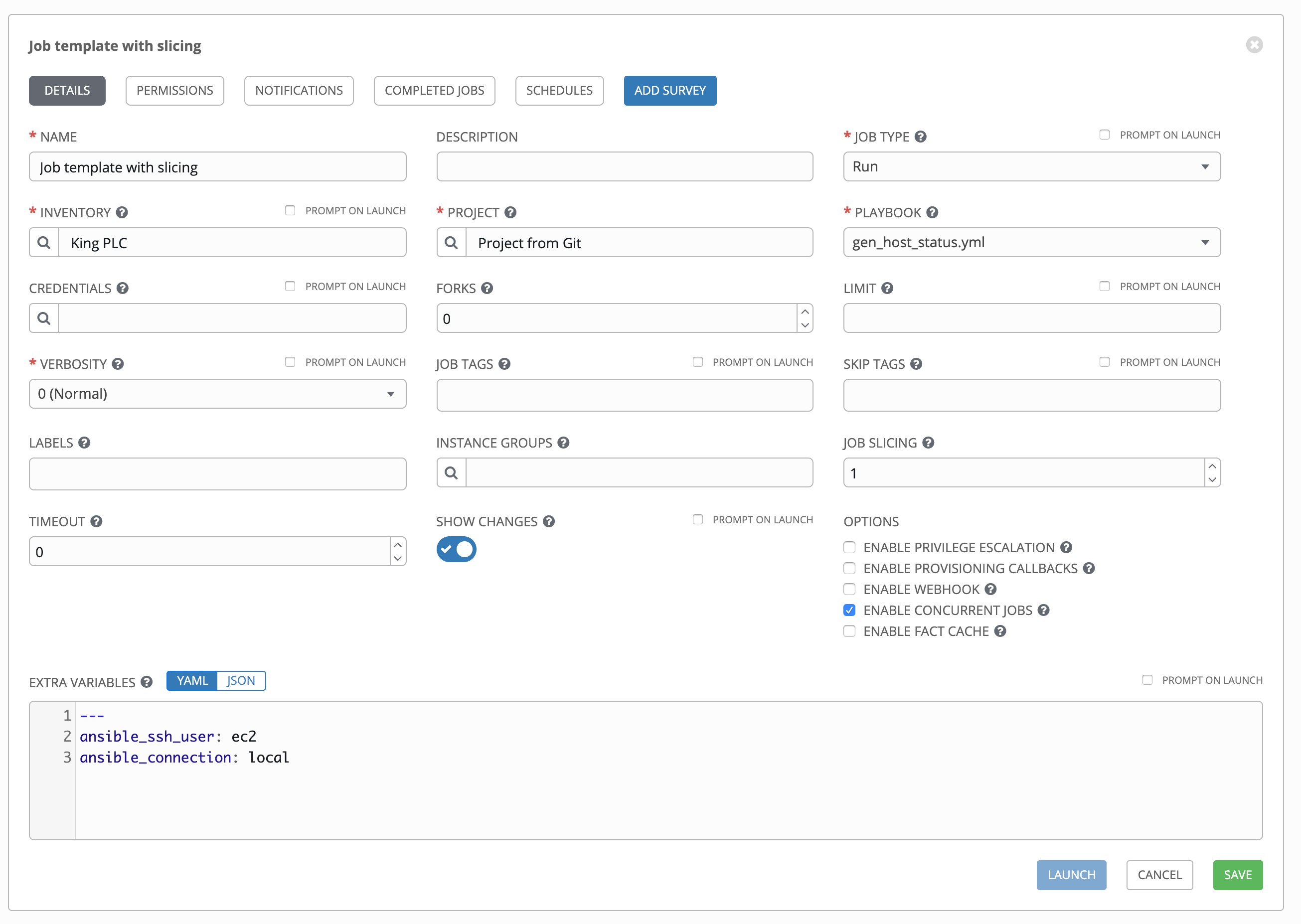
按钮以打开单独的窗口。选择要在其上面运行此作业模板的实例组。如果列表较长,请使用搜索功能来缩小选项范围。Job Slicing:指定您希望此作业模板运行的分片数。每个分片将针对清单的一部分运行相同的任务。如需了解更多有关作业分片的信息,请参阅 任务分片。
Timeout:允许您指定在任务被取消前 Tower 可运行该任务的时间限度(以秒为单位)。默认为 0,即没有作业超时。
Show Changes:允许您查看 Ansible 任务所做的更改。
Prompt on Launch:如果选择此选项,即使提供了默认值,也会在启动时提示您选择是否显示更改。
Options:提供描述此作业模板的可选标签,如“dev”或“test”。标签可用于对 Tower 显示中的作业模板和完成的作业进行分组和过滤。
Enable Privilege Escalation:如果启用此项,请以管理员身份运行此 playbook。这等同于将
--become选项传递给ansible-playbook命令。Enable Provisioning Callbacks:启用主机通过 Tower API 回调至 Tower,并调用从该作业模板启动作业。如需了解更多信息,请参阅 置备回调。
Enable Webhook:打开与用于启动作业模板的预定义 SCM 系统 Web 服务进行接口的功能。当前支持的 SCM 系统为 GitHub 和 GitLab。
如果您启用 Webhook,会显示其他字段,提示输入更多信息:

Webhook Service:从中选择侦听 Webhook 的服务
**Webhook Credential**(可选):提供 GitHub 或 GitLab 个人访问令牌 (PAT) 作为凭证,用来向 Webhook 服务发回状态更新。在可以选择之前,凭证必须存在。请参阅 凭证类型 以创建一个凭证。
Save 后,在查看或编辑时会显示其他字段并保持可见。
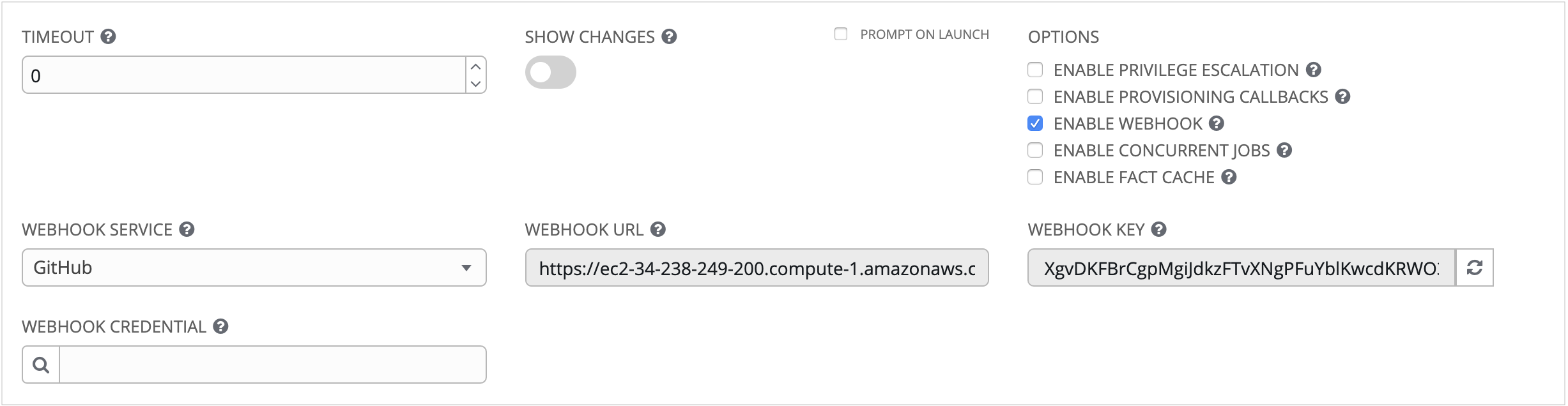
Webhook URL:自动填充将 POST 请求发送到的 Webhook 服务的 URL。
Webhook Key:生成的共享 secret,供 Webhook 服务用来签署发送到 Tower 的有效负载。必须在 Webhook 服务上的设置中对此进行配置,以使 Tower 接受来自该服务的 Webhook。
有关设置 Webhook 的更多信息,请参阅 使用 Webhook。
Enable Concurrent Jobs:如果队列中的作业不相互依赖,允许它们同时运行。如果您想同时运行作业分片,请选中此复选框。如需了解更多信息,请参阅 Ansible Tower 容量确定和作业影响。
Enable Fact Cache:启用时,Tower 将为与作业运行相关的清单中的所有主机激活 Ansible 事实缓存插件。
Extra Variables:
向 playbook 传递额外的命令行变量。这是 ansible-playbook 的“-e”或“--extra-vars”命令行参数,记录在 Ansible 文档中,请参阅 Passing Variables on the Command Line。
使用 YAML 或 JSON 提供键/值对。这些变量具有最大优先级值并且会覆盖在其他位置指定的其他变量。示例值可能为:
git_branch: production release_version: 1.5有关额外变量的更多信息,请参阅 额外变量。
Prompt on Launch:如果选择此选项,即使提供了默认值,也会在启动时提示您选择一个命令行变量。
注解
如果您希望能够在计划中指定 extra_vars,您必须在作业模板中为 EXTRA VARIABLES 选择 Prompt on Launch,或者在作业模板中启用问卷调查,然后那些回答的问卷调查问题将成为 extra_vars。
当您完成作业模板详情配置后,请点击 Save。
保存该模板不会退出作业模板页面,而是会保留在作业模板详情视图中以在需要时进行进一步编辑。在保存模板后,您可以点击 Launch 来启动作业,或者继续添加更多有关模板的属性,如权限、通知,查看已完成的作业,以及添加一个调查问卷(如果作业类型不是扫描)。在启动之前,您必须先保存模板,否则 Launch 按钮将一直灰显。
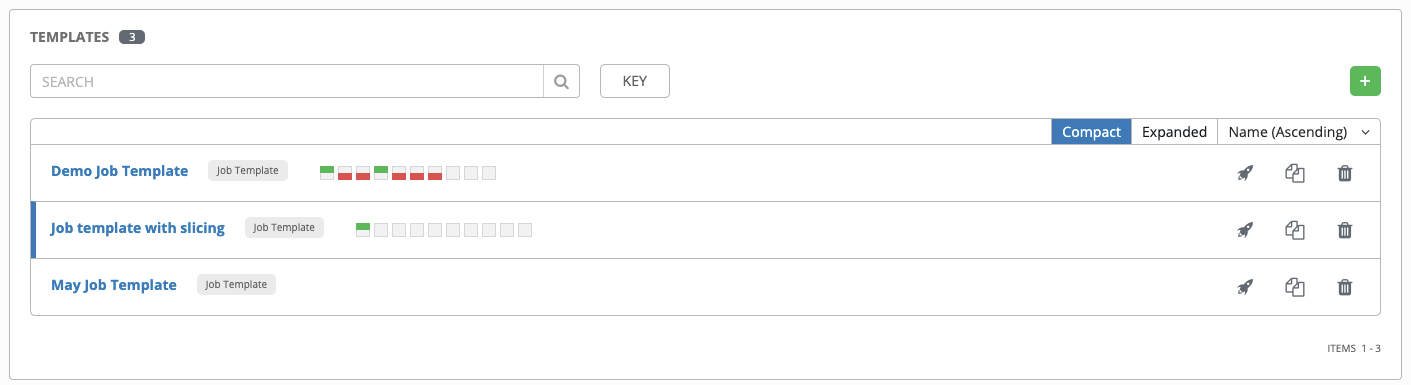
当新创建的模板出现在屏幕底部的模板列表中时,您可以确认模板已保存。
16.2. 添加权限¶
Permissions 标签页允许您为用户和团队成员审核、授权、编辑和删除相关权限。要为特定用户分配这个资源的权限:
点击**Permissions** 标签页。
点击
按钮,打开 Add Users/Teams 窗口。
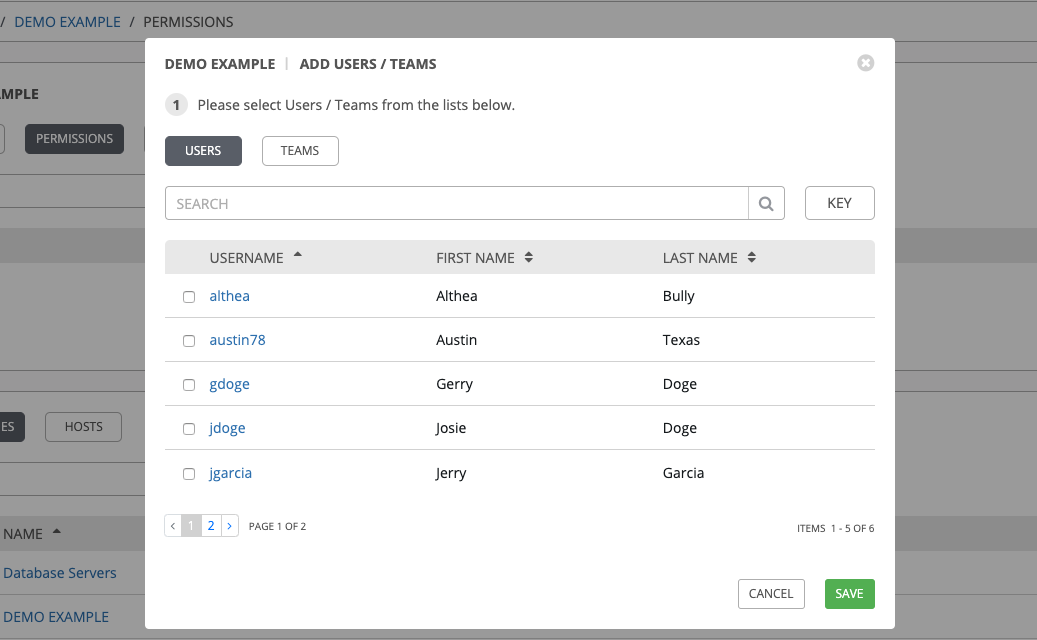
指定将分配访问权限的用户或团队,然后为其分配特定的角色:
点击需要选择的用户或团队名称旁的复选框来选择它们。
注解
您可以同时选择多个用户和团队,方法是在没有保存的情况下在 Users 和 Teams 标签页中进行选择。
选择后,窗口将展开,以便您为选择的每个用户或团队从下拉菜单中选择一个角色。
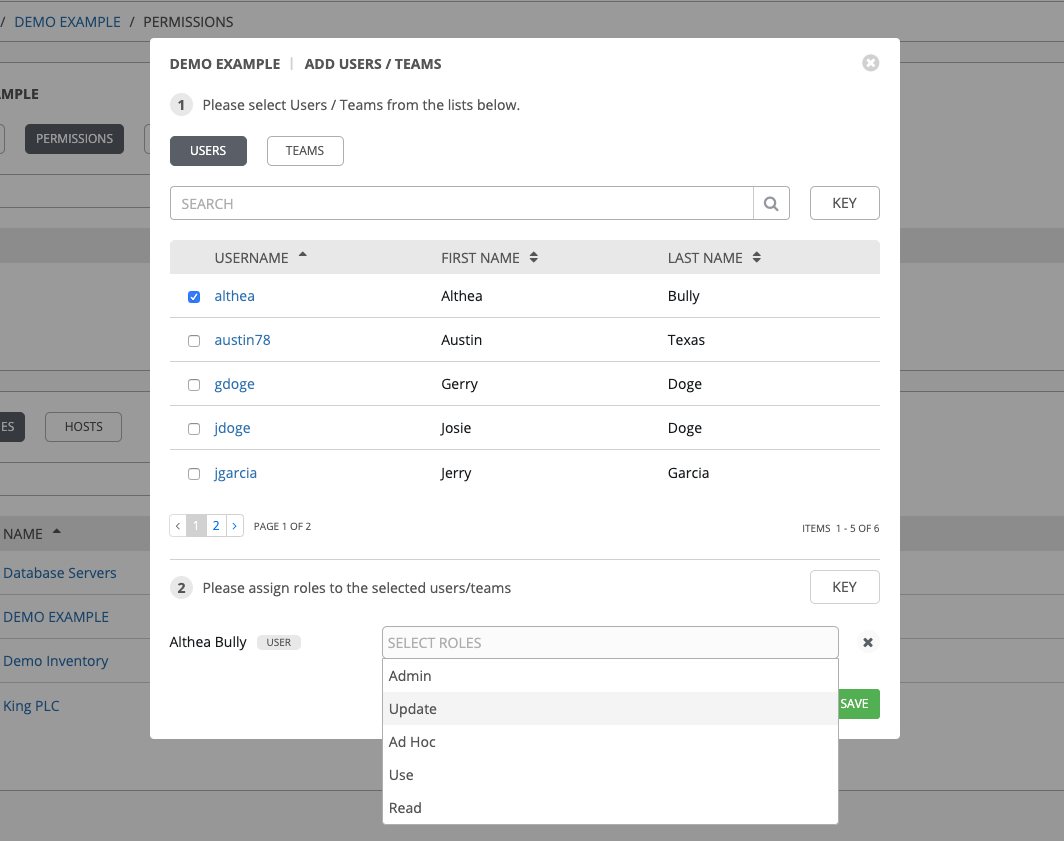
上面的例子显示了与清单关联的选项. 不同的资源有不同的可用选项:
Admin 允许读、运行和编辑权限(适用于所有资源)
Use 允许使用作业模板中的资源(适用于除作业模板以外的所有资源)
Update 允许通过 SCM 更新项目(适用于项目和 inventory)
AdPriority 允许使用 Ad Hoc 命令(适用于 inventory)
Execute 允许启动作业模板(适用于作业模板)
Read 允许只读访问(适用于所有资源)
小技巧
使用角色选择栏中的 Key 按钮显示每个角色的描述信息。如需更多信息,请参阅本指南的 角色 部分。
选择应用到所选用户或团队的角色。
注解
您可以同时为多个用户和团队分配角色,方法是在没有保存的情况下在 Users 和 Teams 标签页中进行设置。
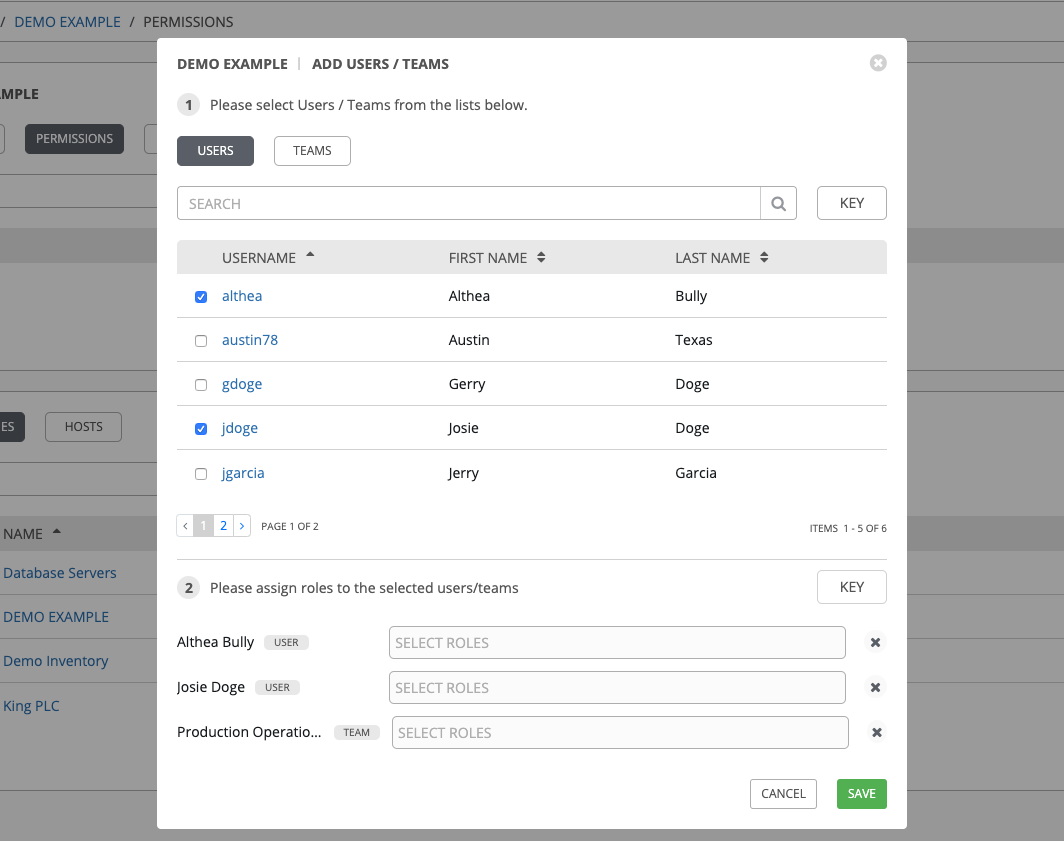
查看为每个用户和团队分配的角色。
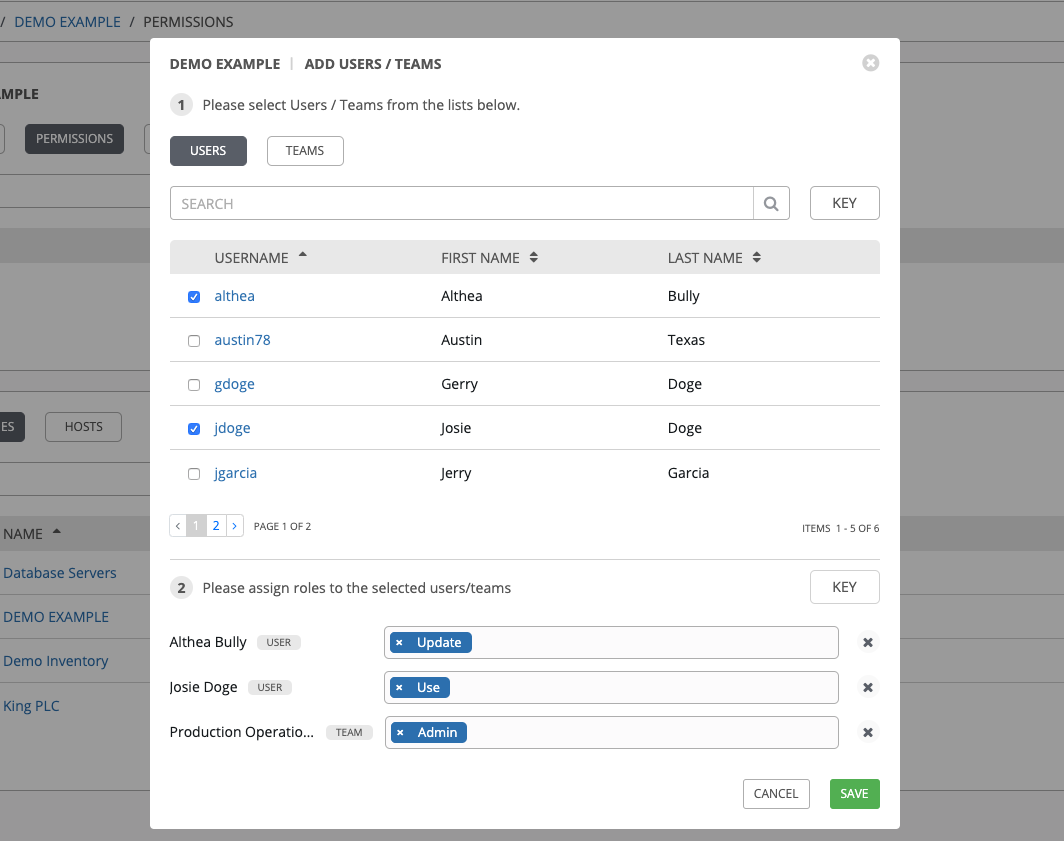
完成后,点击 保存,然后关闭 Add Users/Teams 窗口以显示为每个用户和团队分配的更新角色。

要删除特定用户的权限,请点击其资源旁的 Disassociate (x) 按钮。

这会出现确认对话框,要求您确认解除关联。
16.3. 使用通知¶
点击 Notifications 标签页可以查看您设置的任何通知集成。
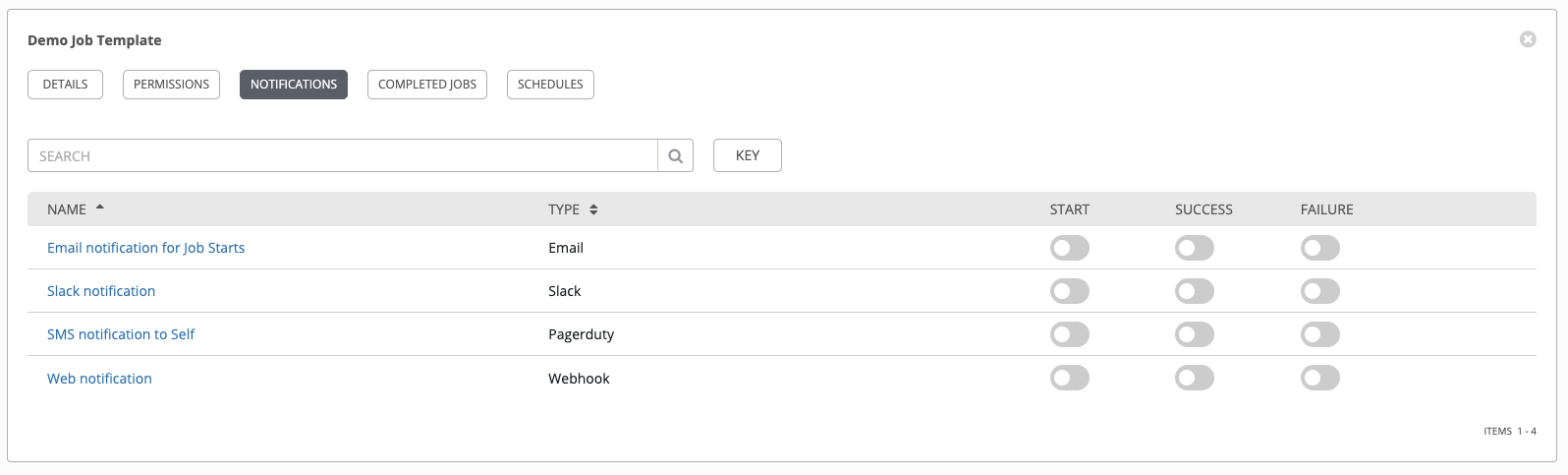
请使用切换按钮启用或禁用要与特定模板搭配使用的通知。更多详情请参阅 启用和禁用通知。
如果没有设置通知,请点击灰色框内的 NOTIFICATIONS 链接来创建新通知。
有关配置各种通知类型的其他详情,请参阅 通知类型。
16.4. 查看完成的作业¶
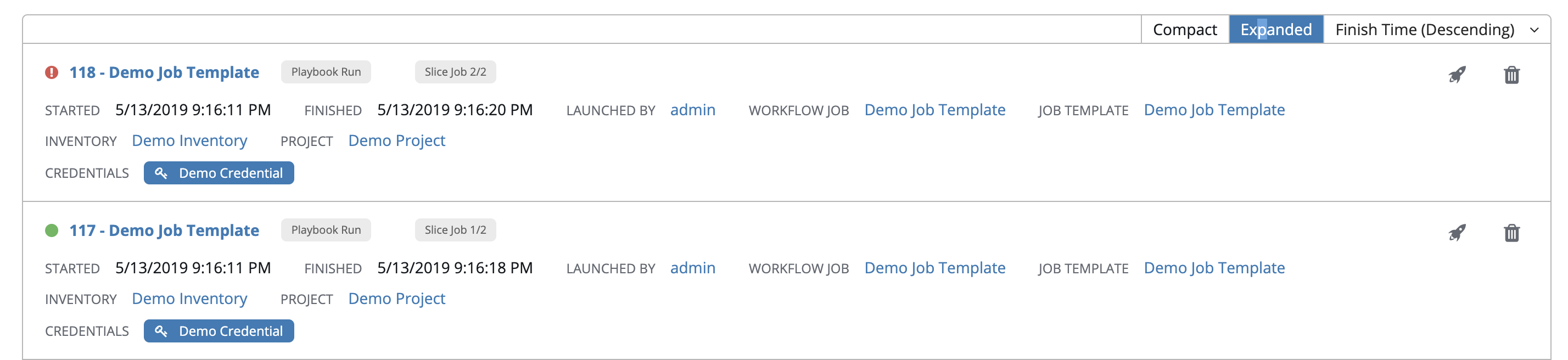
Completed Jobs 标签页提供了已运行的作业模板列表。点击 Expanded 查看每个作业的详情,包括其状态、ID 和名称、作业类型、启动和完成的时间、谁启动了作业,以及使用了哪个模板、清单、项目和凭证。您可以使用任何这些条件过滤已完成的作业列表。
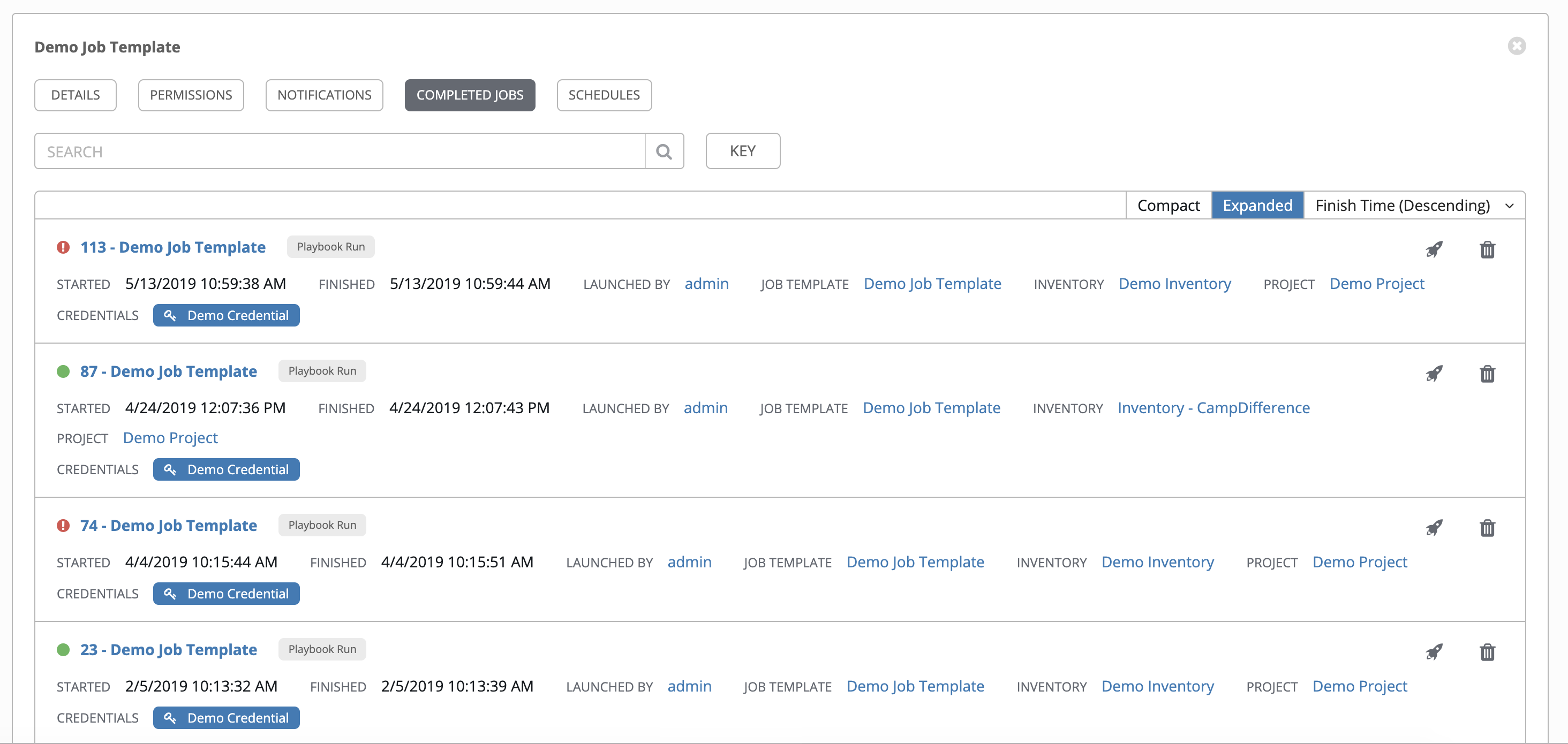
在此列表中显示的切片作业会进行相应标记,包含已运行的分片作业数量:
16.5. 调度¶
从 Schedules 标签页访问特定作业模板的计划。
16.5.1. 调度作业模板¶
要调度作业模板运行,请点击 Schedules 标签页。
如果已经设置了计划,请检查、编辑或启用/禁用您的计划首选项。
如果还没有设置计划,请参阅 调度 了解更多信息。
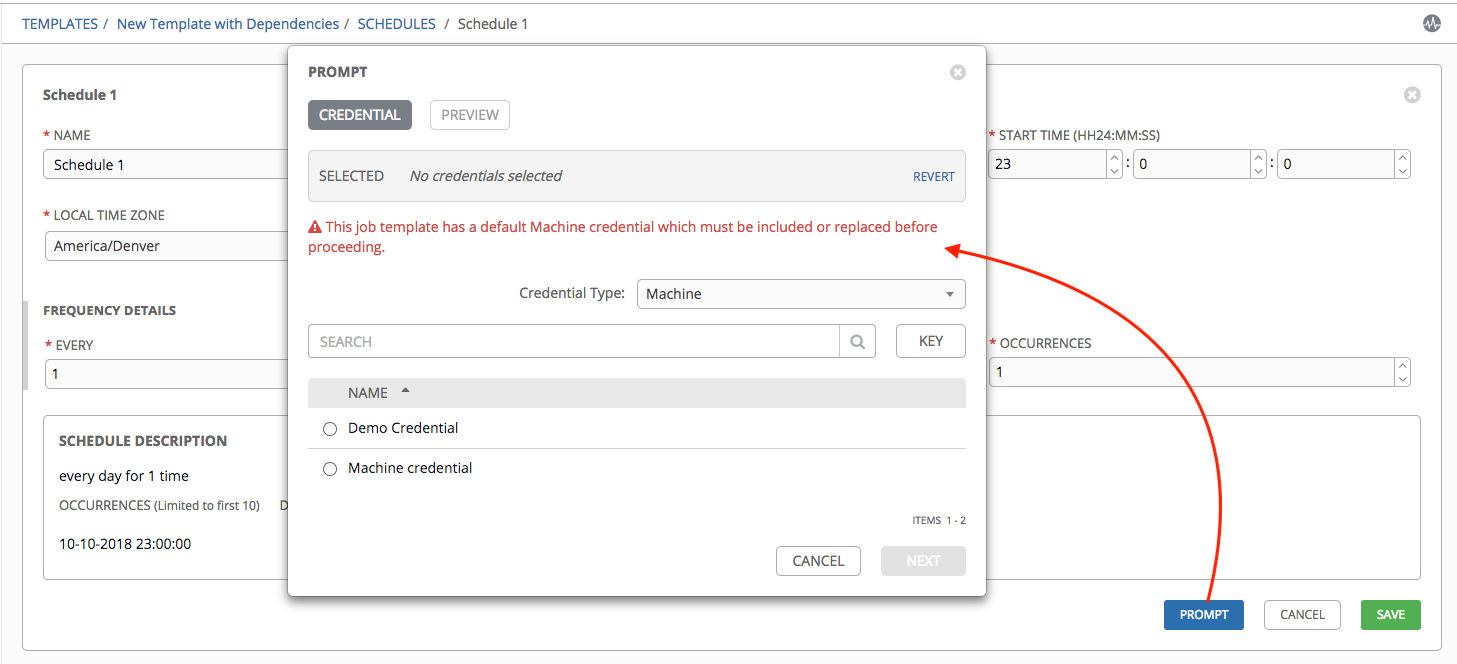
如果在 Credentials 字段中选择了 Prompt on Launch,当您为作业模板创建或编辑调度信息时,Schedules 表单的底部将显示 Prompt 按钮。如果没有在保存前将默认机器凭证替换为另一个机器凭证,您将无法在 Prompt 对话框中删除默认机器凭证。以下是此类消息的示例:
注解
为了能够在计划中设置 extra_vars,您必须在作业模板中为 EXTRA VARIABLES 选择 Prompt on Launch,或者在作业模板中启用问卷调查,然后那些回答的问卷调查问题将成为 extra_vars。
16.6. 调查¶
在作业模板创建或编辑屏幕中,运行或检查作业类型将提供一种设置问卷调查的方法。问卷调查为 playbook 设置额外变量,类似于“Prompt for Extra Variables”,但是以用户友好的问答方式进行。问卷调查还可允许验证用户输入。点击  按钮可以创建问卷调查。
按钮可以创建问卷调查。
问卷调查的用例有很多。例如,运营人员可能希望向开发人员提供一个无需高级 Ansible 知识即可运行的“推送到阶段”按钮。启动时,该任务可能会提示输入问题的回答,例如:“我们应该发布什么标签?”
可以询问很多类型的问题,包括多项选择题。
16.6.1. 创建问卷调查¶
要创建问卷调查,请执行以下操作:
点击
按钮来调出 Add Survey 窗口。
使用屏幕顶部的 ON/OFF 切换按钮来快速激活或取消激活本次调查提示。
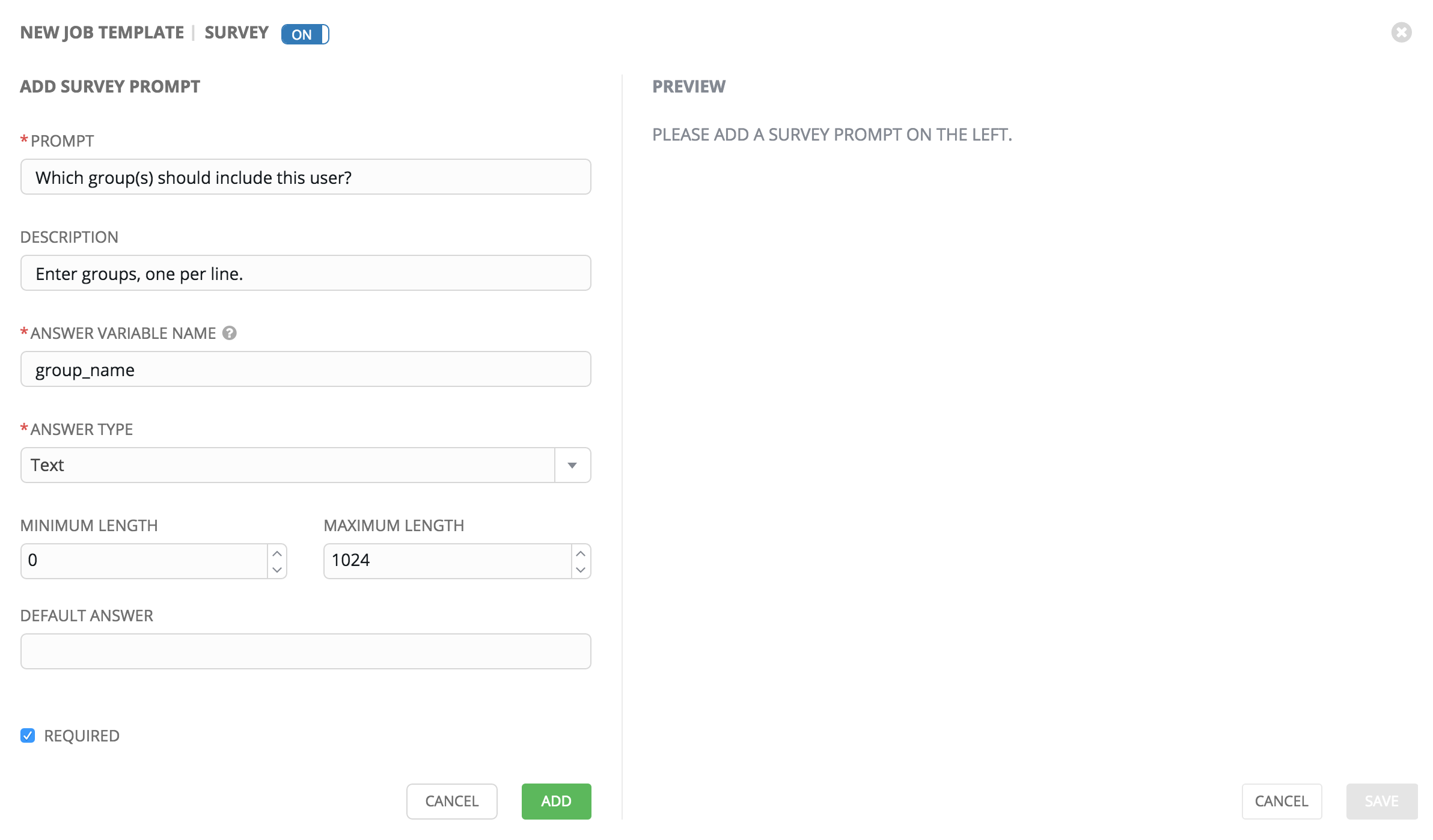
问卷调查可由任何数量的问题组成。对每个问题,请输入以下信息:
Name:询问用户的问题
**Description**(可选):向用户询问的问题描述。
Answer Variable Name:将用户回答存储在其中的 Ansible 变量名称。这是供 playbook 使用的变量。变量名称不能包含空格。
Answer Type:从以下问题类型中选择。
Text:单行文本。您可以为该回答设置最小和最大长度(字符数)。
Textarea:多行文本字段。您可以为该回答设置最小和最大长度(字符数)。
Password:回答被视为敏感信息,和实际密码的处理方式很像。您可以为该回答设置最小和最大长度(字符)。
Multiple Choice (single select):选项列表,每次只能选择其中一个选项。请在 Multiple Choice Options 框中输入选项,每行一个。
Multiple Choice (multiple select):列表选项,每次可选择其中任意数量的选项。在 Multiple Choice Options 框中输入选项,每行一个。
Integer:整数。您可以为该回答设置最小和最大长度(字符数)。
Float:小数。您可以为该答案设置最小和最大长度(字符数)。
Default Answer:问题的默认回答。这个值在界面中预先填充,并在用户未提供回答时使用。
Required:用户是否需要回答这个问题。
输入问题信息后,点击
按钮添加问题。
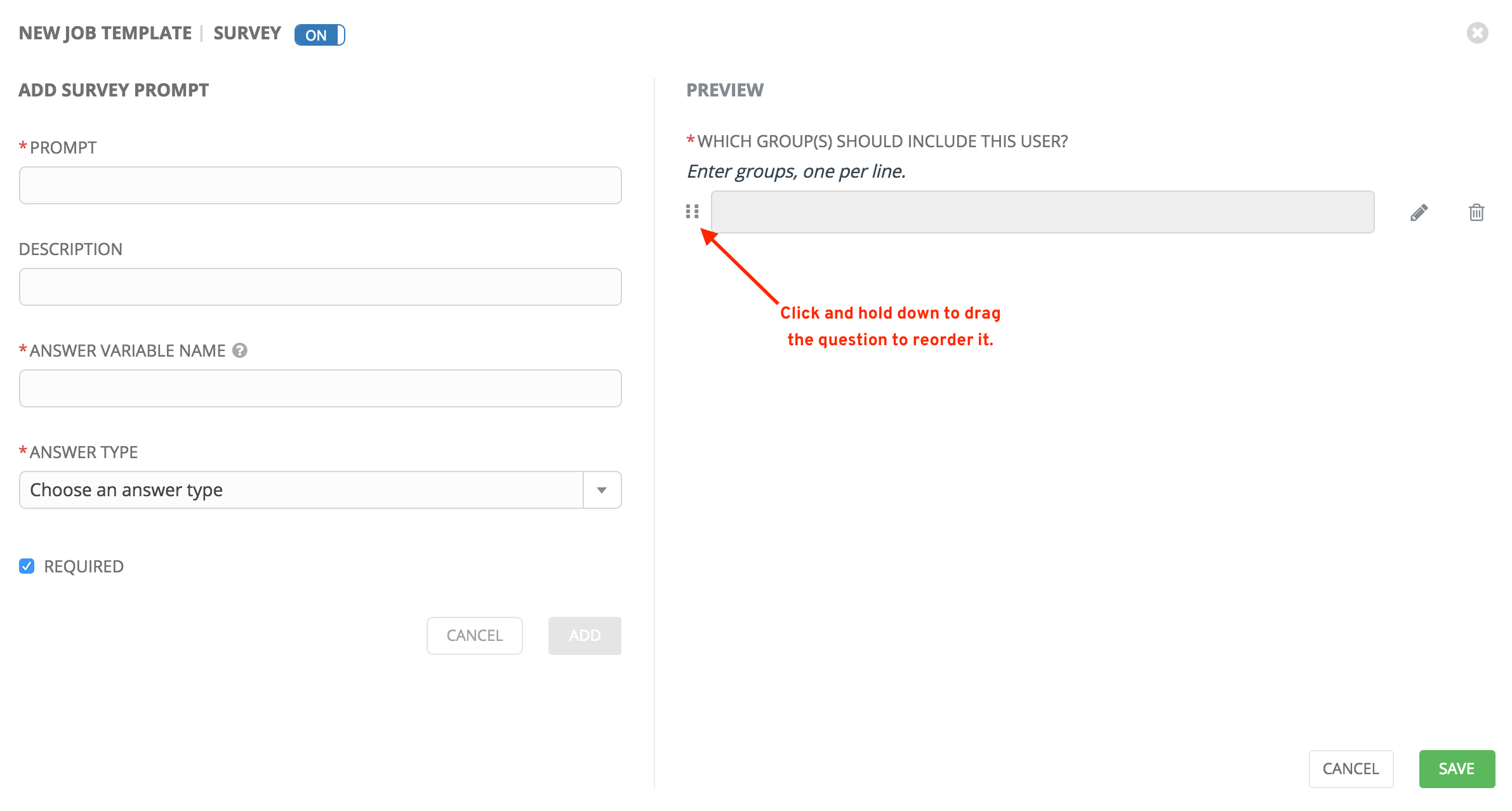
调查的样式化版本显示在 Preview 窗格中。对于任何问题,您可以点击 Edit 按钮编辑问题,Delete 按钮删除问题,然后点击并拖动网格图标来重新安排问题的顺序。
返回左窗格以添加其他问题。
完成后,点击 Save 保存问卷调查。
16.6.2. 可选的问卷调查问题¶
问卷调查问题的 Required 设置决定了对于与之交互的用户,回答是不是可选的。
在后台,可选的问卷调查变量可在 extra_vars 中传递给 playbook,即使没有填写也一样。
如果非文本变量(输入类型)标记为可选,且未填写,则不会将任何问卷调查
extra_var传递给 playbook。如果文本输入或文本区域输入标记为可选,未填充,且最小
length > 0,则不会将任何问卷调查extra_var传递给 playbook。如果文本输入或文本区域输入标记为可选,未填写,且最小
length === 0,则会将该问卷调查extra_var传递给 playbook,并将值设为空字符串 ( "" )。
16.7. 启动作业模板¶
Ansible Tower 的主要优点是 Ansible playbook 的按钮式部署。您可以在 Tower 中轻松配置模板,以存储您通常会在命令行上传递给 ansible-playbook 的所有参数,不仅仅包括 playbook,还包括清单、凭证、额外变量以及您可在命令行上指定的所有选项和设置。
更简单的部署意味着每次都能以相同的方式运行 playbook,可以提高一致性,并且您可以委托职责。即使用户不是 Ansible 专家,也可以运行由其他人编写的 Tower playbook。
通过以下任一方式启动作业模板:
从
 导航链接或在作业模板详情视图中访问作业模板列表,滚动到底部以从模板列表中访问 按钮。
导航链接或在作业模板详情视图中访问作业模板列表,滚动到底部以从模板列表中访问 按钮。
在要启动的作业模板的作业模板视图中,点击 Launch。
作业可能需要额外信息才能运行。启动时可能会要求提供以下数据:
设置的凭证
为任意参数选择
Prompt on Launch选项已设置为 Ask 的密码
问卷调查(如果已经为作业模板配置了问卷调查)
额外变量(如果作业模板要求提供)
注解
如果一个作业有用户提供的值,则这些值会在重新启动时被考虑。如果用户没有指定值,作业会使用作业模板中的默认值。作业并不会按当前的状态原样重新启动。在重新启动时用户的输入会被应用到作业模板中。
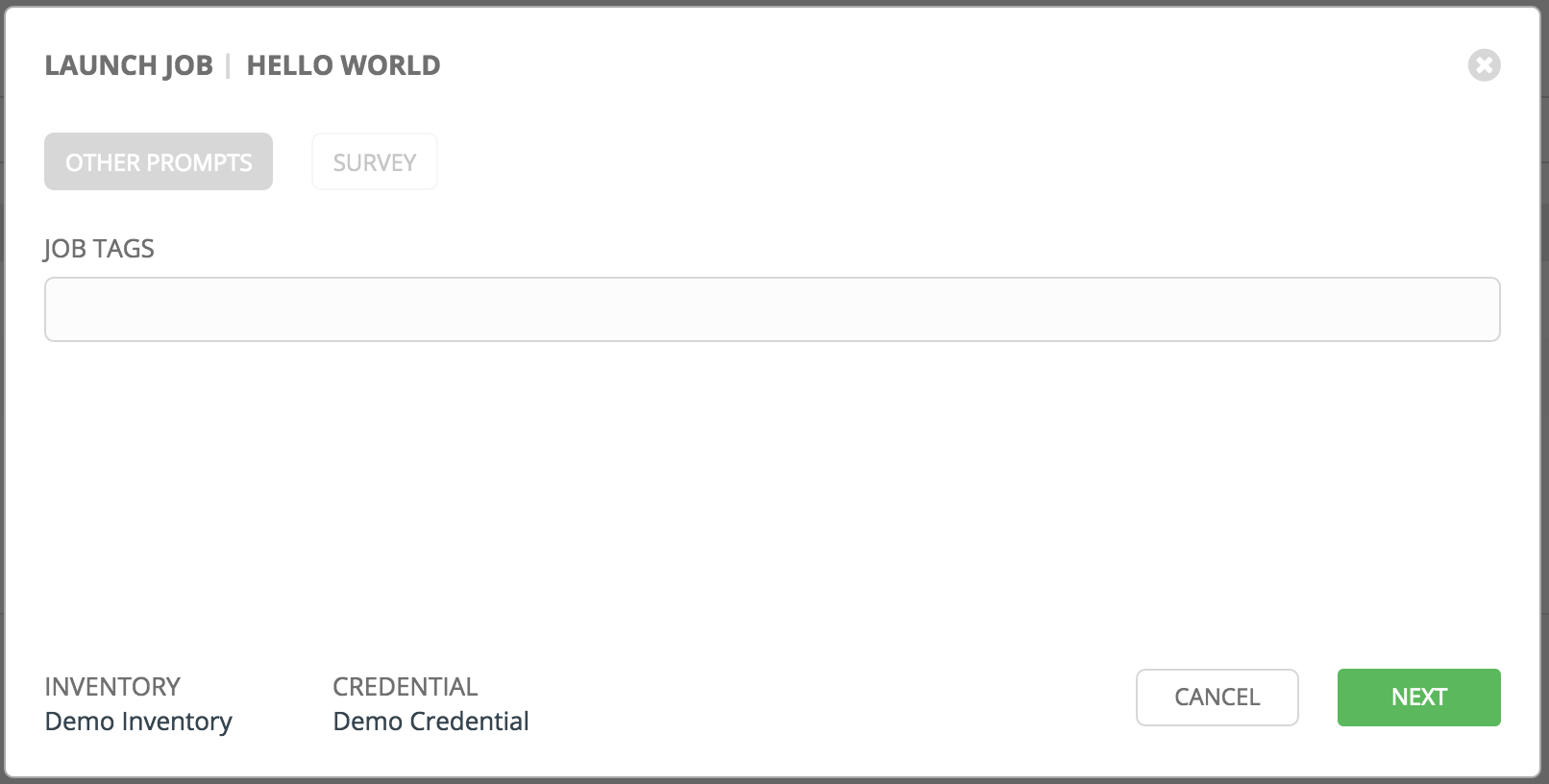
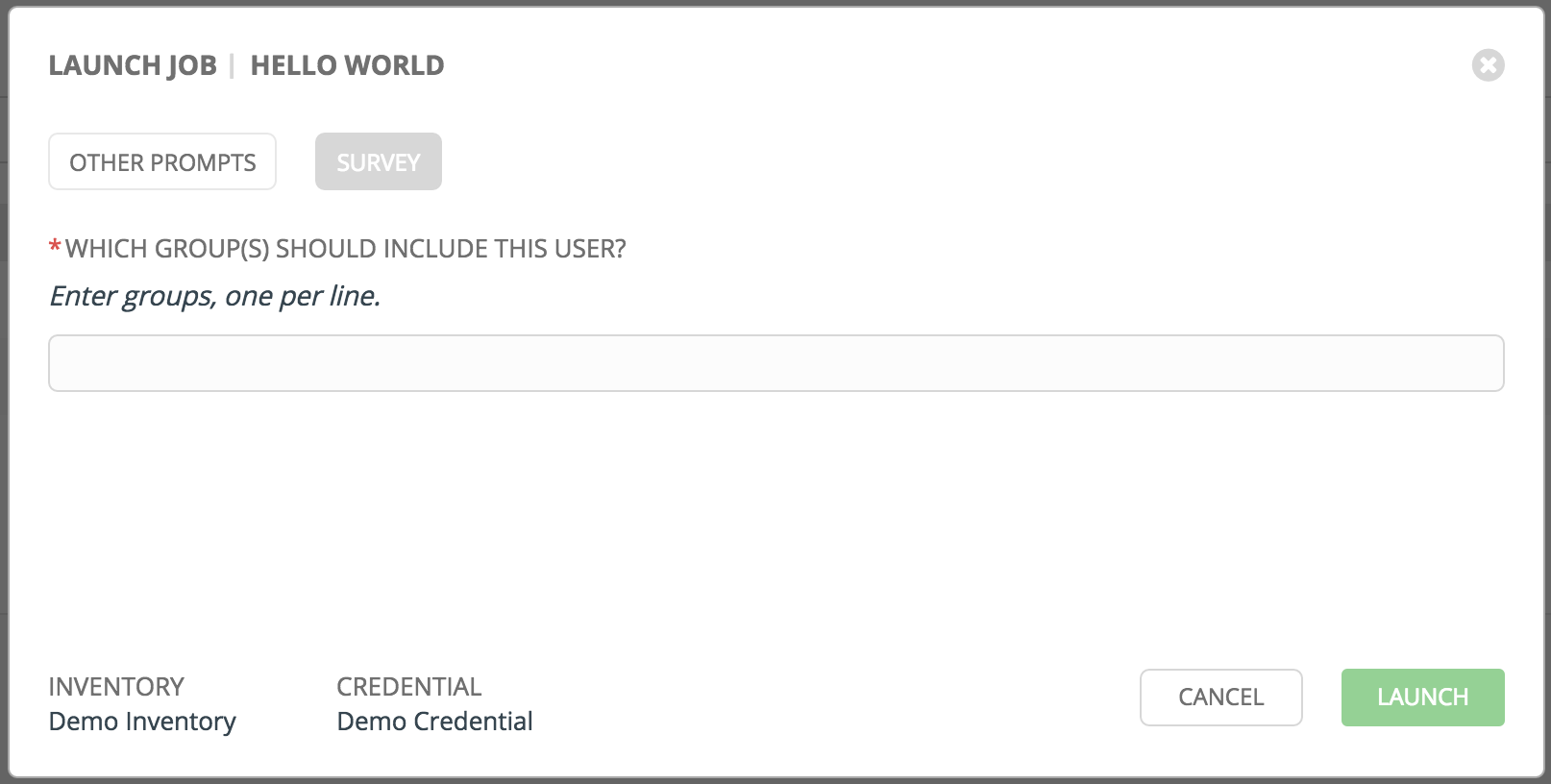
以下是一个作业启动示例,它提示输入作业标签,并运行 调查 中创建的示例问卷调查。
注解
在一个标签页中输入值,然后返回上一个标签页,然后再继续进入下一个标签页会导致在剩余标签页中需要重新提供值。请安装提示出现的顺序填写标签页来避免出现这种情况。
除了作业模板和问卷调查中设置的额外变量之外,Tower 还会自动将以下变量添加到作业环境中:
tower_job_id:此作业运行的作业 IDtower_job_launch_type:用于说明作业启动方式的描述:manual:作业是由用户手动启动的。
relaunch:作业是通过重启来启动的。
callback:作业是通过主机回调启动的。
scheduled:作业是由一个调度启动的。
dependency:作业是作为另一个作业的依赖项启动的。
workflow:作业是从工作流作业中启动的。
sync:作业是从项目同步启动的。
scm:作业是作为清单 SCM 同步创建的。
tower_job_template_id:此作业运行使用的作业模板 IDtower_job_template_name:此作业使用的作业模板名称tower_project_revision:此特定作业使用的源树的修订标识符(它还与作业的字段scm_revision相同)tower_user_email:启动了此作业的 Tower 用户的用户电子邮件。此变量不可用于回调或调度的作业。tower_user_first_name:启动了此作业的 Tower 用户的名字。此变量不可用于回调或调度的作业。tower_user_id:启动了此作业的 Tower 用户的用户 ID。此变量不可用于回调或调度的作业。tower_user_last_name:启动了此作业的 Tower 用户的姓氏。此变量不可用于回调或调度的作业。tower_user_name:启动了此作业的 Tower 用户的用户名。此变量不可用于回调或调度的作业。tower_schedule_id:启动了此作业的调度的 ID(如果适用)tower_schedule_name:启动了此作业的调度的名称(如果适用)tower_workflow_job_id:启动了此作业的工作流作业的 ID(如果适用)tower_workflow_job_name:启动了此作业的工作流作业的名称(如果适用)。请注意,这还与工作流作业模板相同。tower_inventory_id:此作业使用的清单的 ID(如果适用)tower_inventory_name:此作业使用的清单的名称(如果适用)
还为所有变量添加了“awx”前缀,例如,awx_job_id。
启动后,Tower 会在 Jobs 标签页下自动将 Web 浏览器重定向到此作业的 Job Status 页面。
注解
您可以从列表视图中重新启动最新的作业,以便针对指定清单中的所有主机或者仅仅是失败的主机重新运行。更多详情请参阅 Ansible Tower User Guide 中的 Jobs
当分片作业正在运行时,作业列表会显示工作流和作业分片,以及用于单独查看其详情的链接。
16.8. 复制作业模板¶
Ansible Tower 3.0 引入了复制作业模板的功能。选择复制作业模板时,**不会**复制任何关联的计划、通知或权限。计划和通知必须由创建作业模板副本的用户或管理员重新创建。将为复制作业模板的用户授予管理员权限,但不会将任何权限分配(复制)到作业模板。
从
导航链接或在作业模板详情视图中访问作业模板列表,滚动到底部以从模板列表中访问它。
点击
按钮。
此时会打开一个新模板,带有作为复制来源的模板的名称和一个时间戳。
将 Name 字段的内容替换为新名称,并提供或者修改其他字段中的条目以完成此页面。
完成后请点击 Save。
16.9. 扫描作业模板¶
从 Ansible Tower 3.2 开始,不再支持扫描作业。此系统跟踪功能曾用来捕获和存储事实作为历史数据。现在,事实将通过事实缓存存储在 Tower 中。如需了解更多信息,请参阅 事实缓存。
如果您在 Ansible Tower 3.2 之前的系统中有作业模板扫描作业,它们已被转换为运行类型(类似于正常作业模板),并且保留了其相关资源(例如清单、凭证)。默认情况下会为没有相关项目的作业模板扫描作业分配一个特殊的 playbook,或者您可以使用自己的扫描 playbook 指定一个项目。之前为每个机构创建了一个指向 https://github.com/ansible/tower-fact-modules 的项目,并将作业模板设为 playbook https://github.com/ansible/tower-fact-modules/blob/master/scan_facts.yml.
16.9.1. 事实扫描 Playbook¶
扫描作业 playbook scan_facts.yml 包含三个 fact scan modules``(软件包、服务和文件)的调用以及 Ansible 的标准事实收集。``scan_facts.yml playbook 文件类似如下:
- hosts: all
vars:
scan_use_checksum: false
scan_use_recursive: false
tasks:
- scan_packages:
- scan_services:
- scan_files:
paths: '{{ scan_file_paths }}'
get_checksum: '{{ scan_use_checksum }}'
recursive: '{{ scan_use_recursive }}'
when: scan_file_paths is defined
scan_files 事实模块是唯一接受参数的模块,通过扫描作业模板中的 extra_vars 传递。
scan_file_paths: '/tmp/'
scan_use_checksum: true
scan_use_recursive: true
scan_file_paths参数可能有多个设置(如/tmp/或/var/log)。scan_use_checksum和scan_use_recursive参数也可以设为 false 或省略。省略等同于 false 设置。
扫描作业模板应启用 become 并使用使 become 成为可能的凭证。您可以通过从 Options 菜单中选中 Enable Privilege Escalation 来启用 become:
注解
如果在 Ansible Tower 3.1.x 中维护扫描作业模板,然后升级到 Ansible Tower 3.2,则会自动创建一个新的“Tower Fact Scan - Default”项目。此项目包含之前在 Ansible Tower 版本中使用的旧扫描 playbook。
16.9.2. scan_facts.yml 支持的操作系统¶
如果您将 scan_facts.yml playbook 与“使用事实缓存”搭配使用,请确保您的操作系统受支持:
Red Hat Enterprise Linux 5、6 和 7
CentOS 5、6 和 7
Ubuntu 16.04(Unbuntu 支持已被弃用并将在以后的发行版本中删除)
OEL 6 和 7
SLES 11 和 12
Debian 6、7、8
Fedora 22、23、24
Amazon Linux 2016.03
Windows Server 2008 及更新版本
请注意,其中有些操作系统可能需要进行初始配置,才能运行 python 和/或访问扫描模块依赖的 python 软件包(比如 python-apt)。
16.9.3. 预扫描设置¶
以下的 playbook 示例配置了特定发行版运行扫描,以便可以针对它们运行扫描作业。
Bootstrap Ubuntu (16.04)
---
- name: Get Ubuntu 16, and on ready
hosts: all
sudo: yes
gather_facts: no
tasks:
- name: install python-simplejson
raw: sudo apt-get -y update
raw: sudo apt-get -y install python-simplejson
raw: sudo apt-get install python-apt
Bootstrap Fedora (23, 24)
---
- name: Get Fedora ready
hosts: all
sudo: yes
gather_facts: no
tasks:
- name: install python-simplejson
raw: sudo dnf -y update
raw: sudo dnf -y install python-simplejson
raw: sudo dnf -y install rpm-python
CentOS 5 或 Red Hat Enterprise Linux 5 可能还需要安装 simplejson 软件包。
16.9.4. 自定义事实扫描¶
自定义事实扫描的 playbook 与上方的事实扫描 Playbook 类似。例如,只使用自定义 scan_foo Ansible 事实模块的 playbook 类似如下:
scan_custom.yml:
- hosts: all
gather_facts: false
tasks:
- scan_foo:
scan_foo.py:
def main():
module = AnsibleModule(
argument_spec = dict())
foo = [
{
"hello": "world"
},
{
"foo": "bar"
}
]
results = dict(ansible_facts=dict(foo=foo))
module.exit_json(**results)
main()
要使用自定义事实模块,请确保它位于扫描作业模板中使用的 Ansible 项目的 /library/ 子目录中。此事实扫描模块非常简单,返回一组硬编码的事实:
[
{
"hello": "world"
},
{
"foo": "bar"
}
]
如需更多信息,请参阅 Ansible 文档的 Module Provided 'Facts' 部分。
16.10. 事实缓存¶
Tower 可以通过 Ansible 事实缓存插件按主机存储和检索事实。此行为可以按作业模板进行配置。事实缓存默认关闭,但可以启用以满足与作业运行相关的清单中所有主机的事实请求。这可让您将作业模板与 --limit 搭配使用,同时仍可访问整个主机事实清单。插件按主机强制应用的全局超时设置可通过 Configure Tower 界面在 Jobs 标签页下指定(以秒为单位):
启动使用事实缓存 (use_fact_cache=True) 的作业后,Tower 会将与该作业相关清单中的每个主机相关联的所有 ansible_facts 注入到 memcached。清单中所有主机的列表也会与 inventory_id 键和主机名值一起注入到 memcached。Ansible Tower 随附的 Ansible 事实缓存插件只会在启用了事实缓存 (use_fact_cache=True) 的作业上启用。在 Ansible 中运行的事实缓存插件将连接至同一 memcached 实例。
当某个作业完成启用了事实缓存 (use_fact_cache=True) 的运行时,Tower 会通过 memcached 检索清单中主机的所有记录。任何记录只要更新时间晚于每个主机当前存储的事实,都会保存到数据库中。
Tower 总是会将主机 ansible_facts 注入到 memcached。缓存的值可能会也可能不会显示,具体取决于每个主机新存储的事实以及为全局缓存设置指定的超时值。
新事实和更改的事实将通过 Tower 的日志记录功能记录,具体来说是记录到 system_tracking 命名空间或日志记录器。日志记录有效负载将包括以下字段:
host_name
inventory_id
ansible_facts
其中 ansible_facts 是 Tower 清单 inventory_id 中 host_name 的所有 Ansible 事实的字典。
注解
如果主机名包含正斜杠 (/),事实缓存将不适用于该主机。如果清单中有 100 个主机,其中一个主机的名称中有一个 /,其中的 99 个主机仍会收集事实。
16.10.1. 事实缓存的好处¶
相较于运行事实收集,事实缓存会节省大量时间。如果您在一个针对一千个主机和 fork 运行的作业中有一个 playbook,您可以轻松地花 10 分钟来收集所有这些主机的事实。但是如果您定期运行一个作业,第一次运行会缓存这些事实,而下一次运行只需从数据库中拉取它们。这会大幅削减针对大型清单(包括智能清单)的作业运行时间。
注解
不要修改 tower.cfg 文件来应用事实缓存。自定义事实缓存可能会与 Tower 的事实缓存功能冲突。我们推荐使用 Ansible Tower 附带的事实缓存模块。隔离的节点不支持事实缓存。
您可以选择在作业模板窗口的 Options 字段中启用缓存的事实以在作业中使用它。

要清除事实,您需要运行 Ansible clear_facts meta task。以下是使用 Ansible clear_facts 元任务的示例 playbook。
- hosts: all
gather_facts: false
tasks:
- name: Clear gathered facts from all currently targeted hosts
meta: clear_facts
事实缓存的 API 端点可以在以下网站找到:http://<Tower server name>/api/v2/hosts/x/ansible_facts。
16.11. 使用云凭证¶
云凭证可以在同步相应的云清单时使用。云凭证还可能与作业模板关联,并包含在运行时环境中,供 playbook 使用。云凭证是在 Ansible Tower 版本 2.4.0 中引入的,目前支持以下几种:
16.11.1. OpenStack¶
以下示例 playbook 调用 nova_compute Ansible OpenStack 云模块,并要求凭证进行任何有意义的操作,它要求提供以下信息:auth_url、username、password 和 project_name。这些字段通过环境变量 OS_CLIENT_CONFIG_FILE 提供给 playbook,此变量指向 Tower 根据云凭证的内容编写的 YAML 文件。此示例 playbook 会将 YAML 文件加载到 Ansible 变量空间中。
OS_CLIENT_CONFIG_FILE 示例:
clouds:
devstack:
auth:
auth_url: http://devstack.yoursite.com:5000/v2.0/
username: admin
password: your_password_here
project_name: demo
Playbook 示例:
- hosts: all
gather_facts: false
vars:
config_file: "{{ lookup('env', 'OS_CLIENT_CONFIG_FILE') }}"
nova_tenant_name: demo
nova_image_name: "cirros-0.3.2-x86_64-uec"
nova_instance_name: autobot
nova_instance_state: 'present'
nova_flavor_name: m1.nano
nova_group:
group_name: antarctica
instance_name: deceptacon
instance_count: 3
tasks:
- debug: msg="{{ config_file }}"
- stat: path="{{ config_file }}"
register: st
- include_vars: "{{ config_file }}"
when: st.stat.exists and st.stat.isreg
- name: "Print out clouds variable"
debug: msg="{{ clouds|default('No clouds found') }}"
- name: "Setting nova instance state to: {{ nova_instance_state }}"
local_action:
module: nova_compute
login_username: "{{ clouds.devstack.auth.username }}"
login_password: "{{ clouds.devstack.auth.password }}"
16.11.2. Amazon Web Services¶
Amazon Web Services 云凭证在 playbook 执行过程中作为以下环境变量公开(在作业模板中,选择您的设置所需的云凭证):
AWS_ACCESS_KEY_IDAWS_SECRET_ACCESS_KEY
所有 AWS 模块在通过 Tower 运行时都会隐式使用这些凭证,而无需设置 aws_access_key_id 或 aws_secret_access_key 模块选项。
16.11.3. Rackspace¶
Rackspace 云凭证在 playbook 执行过程中作为以下环境变量公开(在作业模板中,选择您的设置所需的云凭证):
RAX_USERNAMERAX_API_KEY
所有 Rackspace 模块在通过 Tower 运行时都会隐式使用这些凭证,而无需设置 username 或 api_key 模块选项。
16.11.4. Google¶
Google 云凭证在 playbook 执行过程中作为以下环境变量公开(在作业模板中,选择您的设置所需的云凭证):
GCE_EMAILGCE_PROJECTGCE_CREDENTIALS_FILE_PATH
所有 Google 模块在通过 Tower 运行时都会隐式使用这些凭证,而无需设置 service_account_email、project_id 或 pem_file 模块选项。
16.11.5. Azure¶
Azure 云凭证在 playbook 执行过程中作为以下环境变量公开(在作业模板中,选择您的设置所需的云凭证):
AZURE_SUBSCRIPTION_IDAZURE_CERT_PATH
所有 Azure 模块在通过 Tower 运行时都会隐式使用这些凭证,而无需设置 subscription_id 或 management_cert_path 模块选项。
16.11.6. VMware¶
VMware 云凭证在 playbook 执行过程中作为以下环境变量公开(在作业模板中,选择您的设置所需的云凭证):
VMWARE_USERVMWARE_PASSWORDVMWARE_HOST
以下示例 playbook 演示了这些凭证的使用情况:
- vsphere_guest:
vcenter_hostname: "{{ lookup('env', 'VMWARE_HOST') }}"
username: "{{ lookup('env', 'VMWARE_USER') }}"
password: "{{ lookup('env', 'VMWARE_PASSWORD') }}"
guest: newvm001
from_template: yes
template_src: centosTemplate
cluster: MainCluster
resource_pool: "/Resources"
vm_extra_config:
folder: MyFolder
16.12. 置备回调¶
置备回调是 Tower 的一项功能,允许主机启动针对自身运行的 playbook,而不是等待用户启动作业以从 Tower 控制台管理主机。请注意,置备回调*仅*用于在调用主机上运行 playbook。置备回调用于云爆发,即:需要客户端到服务器通信以进行配置(例如传输授权密钥)的新实例,而不是针对另一台主机运行作业。这就为以下操作提供了条件:当一个系统通过另一个系统(例如 AWS 自动缩放或操作系统置备系统,如 kickstart 或 preseed)进行配置后,会自动配置该系统;或者通过编程方式启动作业,而无需直接调用 Tower API。启动的作业模板仅针对请求配置的主机运行。
通常这会通过 firstboot 类型脚本或从 cron 访问。
要启用回调,请选中作业模板中的 Allow Provisioning Callbacks 复选框。这会显示此作业模板的 Provisioning Callback URL。
注解
如果要将 Tower 的置备回调功能与动态清单结合使用,则应该为作业模板中使用的清单组设置在启动时更新。

回调还需要一个主机配置密钥,以确保具有 URL 的外部主机无法请求配置。点击  按钮可为这个回调创建唯一主机密钥,或者输入您自己的密钥。主机密钥可在多个主机间重复使用,以针对多个主机应用此作业模板。如果您希望控制哪些主机可以请求配置,则可以随时更改该密钥。
按钮可为这个回调创建唯一主机密钥,或者输入您自己的密钥。主机密钥可在多个主机间重复使用,以针对多个主机应用此作业模板。如果您希望控制哪些主机可以请求配置,则可以随时更改该密钥。
要通过 REST 手动回调,请查看 UI 中的回调 URL,其格式为:
http://<TOWER_SERVER_NAME>/api/v2/job_templates/1/callback/
这个示例 URL 中的“1”是 Tower 中的作业模板 ID。
来自主机的请求必须是 POST。以下是一个使用 curl 的示例(全部在一行):
curl -k -f -i -H 'Content-Type:application/json' -XPOST -d '{"host_config_key": "cfbaae23-81c0-47f8-9a40-44493b82f06a"}' \
https://<TOWER_SERVER_NAME>/api/v2/job_templates/1/callback/
发出请求的主机必须在您的清单中定义,才能使回调成功。如果 Tower 无法按名称或 IP 地址在您定义的某一个清单中找到主机,则请求将被拒绝。在以这种方式运行作业模板时,启动针对其自身运行的 playbook 的主机必须位于清单中。如果该主机不在清单中,则作业模板将失败,并显示“No Hosts Matched”类型错误消息。
注解
如果您的主机不在清单中,并且为清单组设置了 Update on Launch,则 Tower 会在运行回调前尝试更新基于云的清单源。
成功请求会在 Jobs 标签页中生成一个条目,可以在其中查看结果和历史记录。
虽然可以通过 REST 访问回调,但建议的回调使用方法是使用 Tower 附带的示例脚本之一 - /usr/share/awx/request_tower_configuration.sh (Linux/UNIX) 或 /usr/share/awx/request_tower_configuration.ps1 (Windows)。用法在文件的源代码中通过传递 -h 标签进行描述,如下所示:
./request_tower_configuration.sh -h
Usage: ./request_tower_configuration.sh <options>
Request server configuration from Ansible Tower.
OPTIONS:
-h Show this message
-s Tower server (e.g. https://tower.example.com) (required)
-k Allow insecure SSL connections and transfers
-c Host config key (required)
-t Job template ID (required)
-e Extra variables
-s Number of seconds between retries (default: 60)
这个脚本非常智能,因为它知道如何重试命令,因此比起简单的 curl 请求,它是更强大的回调使用方法。正如所编写的,脚本每分钟重试一次,最多十分钟。
注解
请注意,这是一个示例脚本。如果您在检测到失败情况时需要更多的动态行为,应编辑这个脚本,因为任何非 200 的错误代码都可能不是需要重试的暂时性错误。
您最有可能在 Tower 中将回调与动态清单搭配使用,如从支持的某个云提供商中拉取云清单。在这些情况下,除了设置 Update On Launch 以外,请务必为清单源配置清单缓存超时,以避免云的 API 端点受到攻击。由于 request_tower_configuration.sh 脚本每分钟轮询一次,最多十分钟,因此推荐的清单缓存失效时间(在清单源本身中配置)将为一分钟或两分钟。
虽然我们不推荐从 cron 作业运行 request_tower_configuration.sh 脚本,但建议的 cron 间隔可能为每 30 分钟。重复的配置可以通过在 Tower 中调度来轻松处理,因此大多数用户主要使用回调来启用一个在上线时引导至最新配置的基础镜像。为此,在第一次引导时运行是更好的做法。初始引导脚本只是简单的 init 脚本,通常会自我删除,因此您可以设置一个调用 request_tower_configuration.sh 脚本副本的 init 脚本,并使之成为一个自动缩放镜像。
16.12.1. 将额外变量传递给配置回调¶
就像您可以在常规作业模板中传递 extra_vars 一样,您也可以将它们传递到配置回调。要传递 extra_vars,发送的数据必须作为应用程序/json(作为内容类型)成为 POST 请求主体的一部分。在添加您自己的 extra_vars 进行传递时,请使用以下 JSON 格式作为示例:
'{"extra_vars": {"variable1":"value1","variable2":"value2",...}}'
(在 Ansible Tower 版本 2.2.0 中添加。)
您还可以使用 curl 将额外变量传递给作业模板调用,如以下示例所示:
root@localhost:~$ curl -f -H 'Content-Type: application/json' -XPOST \
-d '{"host_config_key": "5a8ec154832b780b9bdef1061764ae5a", "extra_vars": "{\"foo\": \"bar\"}"}' \
http://<TOWER_SERVER_NAME>/api/v2/job_templates/1/callback
有关详情请参阅 Launching Jobs with Curl。
16.13. 额外变量¶
注解
Ansible Tower 3.0.0 增加了严格的 extra_vars 验证。传递给作业启动 API 的 extra_vars 只有在以下条件之一被满足时才有效。
它们与启用的问卷调查(survey)中的变量对应
ask_variables_on_launch被设为 True
当您传递问卷调查变量时,它们作为 Tower 中的额外变量 (extra_vars) 传递。这样做可能需要非常小心,因为将额外变量传递给作业模板(就像对问卷调查的操作一样)可能会覆盖从清单和项目传递的其他变量。
例如,假设您为清单定义了一个变量 debug = true。在作业模板问卷调查中完全有可能覆盖 debug = true 这个变量。
为确保不覆盖您需要传递的变量,请通过在问卷调查中重新定义变量来确保将其包括在内。请记住,可以在清单、组和主机级别定义额外的变量。
注解
从 Ansible Tower 版本 2.4 开始,作业模板额外变量和问卷调查变量的行为已经发生改变。以前,使用问卷调查设置的变量会覆盖作业模板中指定的额外变量。在 2.4 及更新版本中,作业模板额外变量字典已与问卷调查变量合并。这可能会导致升级至 2.4 后的行为发生改变。
以下是 YAML 和 JSON 格式的 extra_vars 的一些简化示例:
YAML 格式的配置:
launch_to_orbit: true
satellites:
- sputnik
- explorer
- satcom
JSON 格式的配置:
{
"launch_to_orbit": true,
"satellites": ["sputnik", "explorer", "satcom"]
}
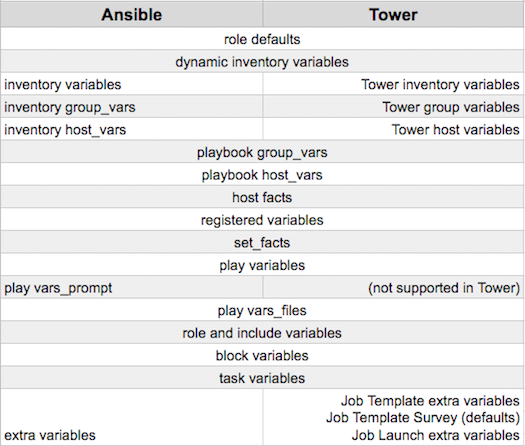
下表记录了 Ansible Tower 中的变量优先级的行为(层次结构)与 Ansible 中的变量优先级比较情况。
Ansible Tower 变量优先级层次结构(最后列出的优先)
16.13.1. 重新启动作业模板¶
Ansible Tower 版本 2.4 的另一个变化是为您的作业引入了 launch_type 设置。重新启动通过将 launch_type 设置为 relaunch 来表示,而不是手动重新启动作业。重新启动行为与启动行为的偏差在于它**不**继承 extra_vars。
作业重新启动不会通过继承逻辑。它会使用为重新启动的作业计算的相同 extra_vars。
例如,假设您启动一个没有 extra_vars 的作业模板,导致创建一个名为 j1 的作业。下一步,假设您编辑作业模板,并加入一些 extra_vars``(如添加 ``"{ "hello": "world" }")。
重新启动 j1 导致创建 j2,但是由于没有继承逻辑,而且 j1 没有 extra_vars,j2 将没有任何 extra_vars。
继续前面的示例,如果您启动了包含您在创建 j1 之后添加的 extra_vars 的作业模板,创建的重新启动作业 (j3) 将包括 extra_vars。重新启动 j3 会导致创建 j4,其中也包括 extra_vars。