15. リソースのプロファイル¶
Ansible Tower では、Playbook の実行中の CPU、メモリー、および PID の数など未加工のパフォーマンスデータを収集する機能が導入されました。これは、Runner に用意されたリソースプロファイリング機能によって実現されます。Runner は Linux control groups ('cgroups') を使用して、実際のリソース使用量を経時的に測定します。cgroups の詳細は、「Introduction to Control Groups」を参照してください。
Ansible Tower をインストールすると、Tower により cgroup が自動的に作成され、Runner が使用できるようになります。
15.1. リソースプロファイリングの有効化¶
Tower のユーザーインターフェースで Runner のリソースプロファイリング機能を有効にするには、以下を実行します。
左のナビゲーションバーから設定 (
 ) アイコンの上にマウスをかざし、ジョブ を選択するか、設定画面から ジョブ タブをクリックしてください。
) アイコンの上にマウスをかざし、ジョブ を選択するか、設定画面から ジョブ タブをクリックしてください。
トグルを使用して 全 Playbook の実行に対する詳細なリソースプロファイリングを有効にする 設定をオンにしてすべてのジョブのデータを収集します。
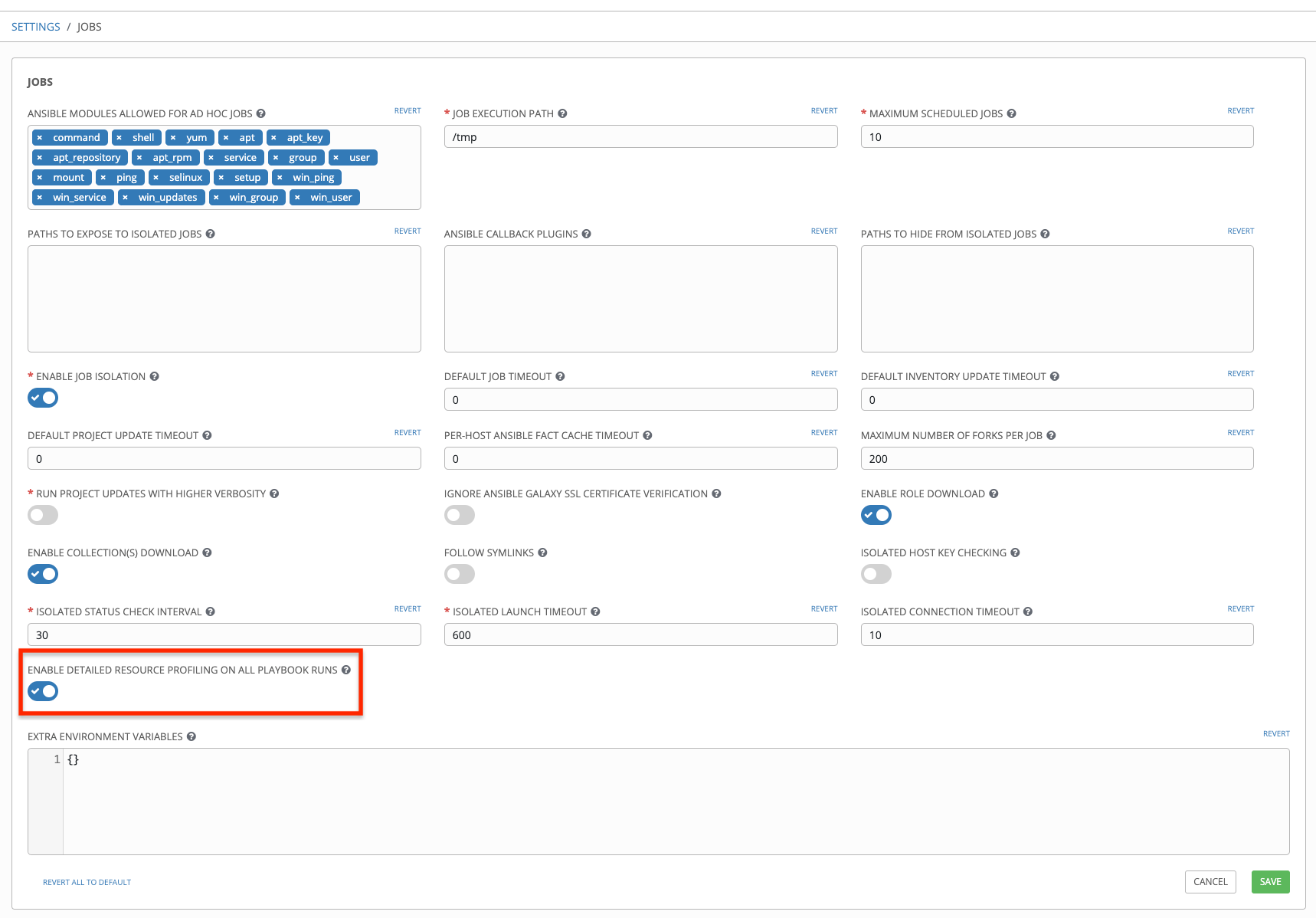
Save をクリックして設定を保存します。
ジョブのパフォーマンスデータが収集されると、そのデータは /var/log/tower/playbook_profiling/<job_id>/ に保存されます。クラスターでは、パフォーマンスデータはそのジョブを実行した Tower のインスタンスに保存されます。ジョブが 分離インスタンス で実行される場合には、そのデータは分離ノードから収集され、分離ノードにジョブを渡すときに使用したコントローラーに保存されます。
タスクごとに 3 つのデータファイル (CPU、メモリー、および PID 数に対応) が作成されます。各ファイルには、JSON テキスト形式のデータが含まれています。ファイルの各行はレコード区切り記号 (RS) で始まり、JSON 辞書が続き、改行 (LF) 文字で終わります。タスクが非常に高速に実行される場合には、そのタスクのパフォーマンスデータがまったく収集されない可能性があります。そのような場合は、対象のタスクのパフォーマンスデータファイルが 1 つまたは複数作成されないことに注意してください。
パフォーマンスデータの内容や、実際のサンプルデータについては、現バージョンの Runner docs を参照してください。