29. ユーザビリティーアナリティクスおよびデータ収集¶
Usability data collection is included with automation controller to collect data to better understand how controller users specifically interact with it, to help enhance future releases, and to continue streamlining your user experience.
Only users installing a trial of Red Hat Ansible Automation Platform or a fresh installation of automation controller are opted-in for this data collection.
Automation controller collects user data automatically to help improve the product. You can opt out or control the way the controller collects data by setting your participation level in the User Interface settings in the Settings menu.
Click Settings from the left navigation bar and select User Interface settings.
Click Edit.
Select the desired level of data collection from the User Analytics Tracking State drop-down list:
オフ: データ収集を行いません。
匿名: ユーザー固有のデータを含めないデータ収集を有効化します。
詳細: お使いのユーザー固有のデータを含めたデータ収集を有効化します。
保存 をクリックして設定を適用するか、キャンセル をクリックして変更を破棄します。
詳細は、Red Hat プライバシーポリシー (https://www.redhat.com/en/about/privacy-policy) を参照してください。
29.1. 自動化アナリティクス¶
ライセンスを初めてインポートしたときに、Automation Analytics (Ansible Automation Platform サブスクリプションの一部であるクラウドサービス) を強化するデータの収集に関連するオプションが提供されました。Automation Analytics のオプトインで効果を得るには、automation controller のインスタンスは Red Hat Enterprise Linux で 実行している必要があります。
Red Hat Insights と同じように、Automation Analytics は必要最小限のデータのみを収集するように構築されています。認証情報のシークレット、個人データ、自動化変数、またはタスク出力は収集されません。詳細は、以下の Details of data collection を参照してください。
この機能を有効にするには、Automation Analytics のデータ収集をオンにし、設定 メニューにあるオプションのシステム設定一覧の その他のシステム設定 に、Red Hat カスタマー認証情報を入力します。
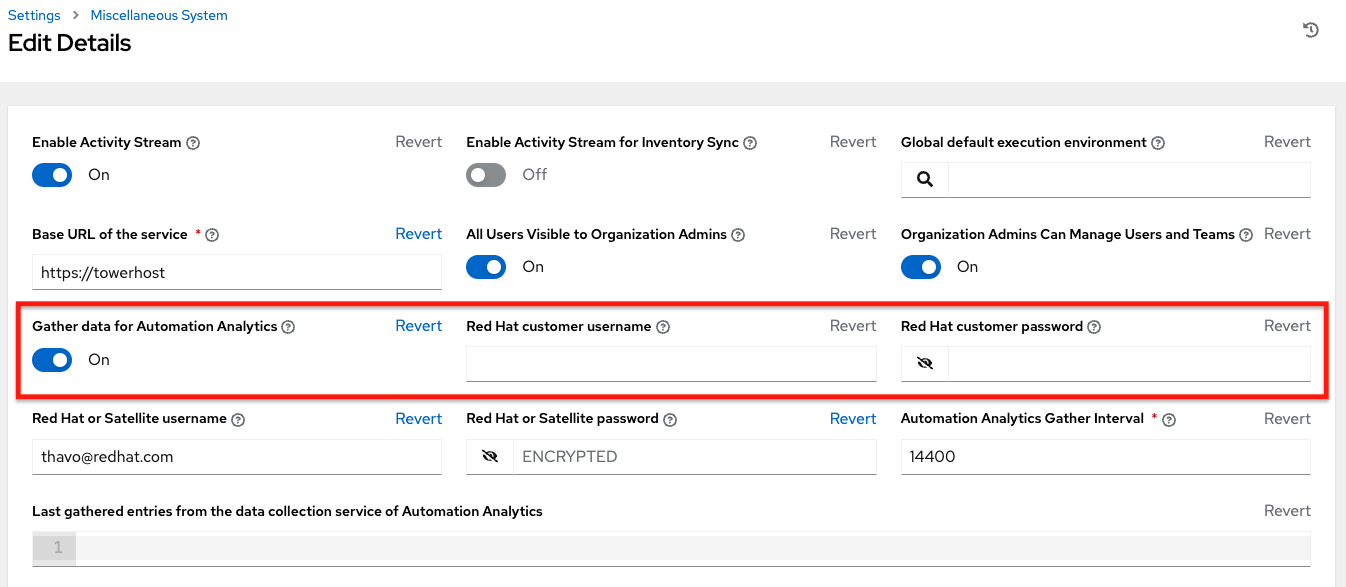
You can view the location to which the collection of insights data will be uploaded in the Automation Analytics upload URL field in the Details view.
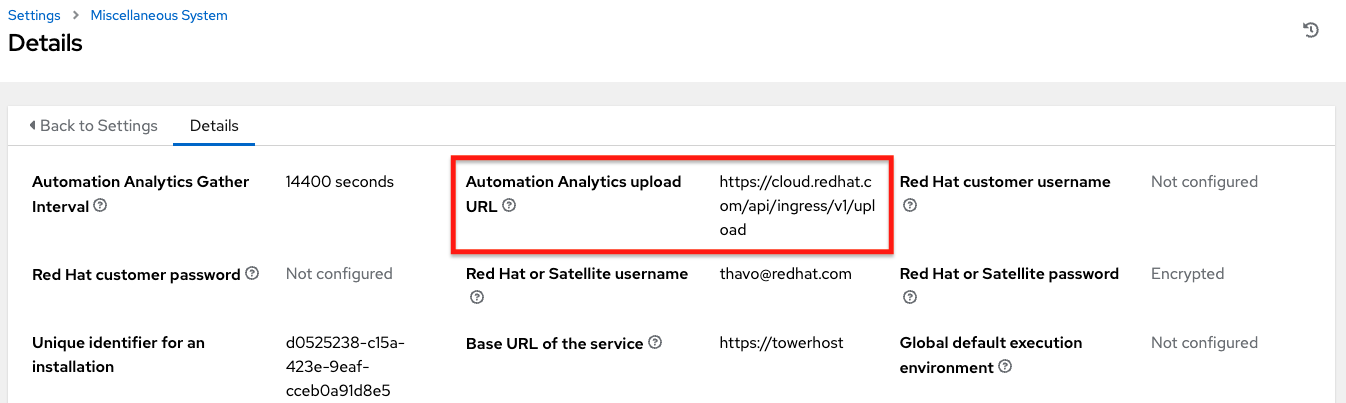
デフォルトでは、Automation Analytics データは 4 時間ごとに収集され、機能を有効にすると、最長 1 カ月前 (または前回の収集まで) のデータが収集されます。このデータ収集は、システム設定ウィンドウの **その他のシステム設定* でいつでもオフにすることができます。
この設定は、以下のエンドポイントのいずれかで INSIGHTS_TRACKING_STATE = True を指定し、API 経由で有効にすることも可能です。
api/v2/settings/allapi/v2/settings/system
このデータ収集から生成された Automation Analytics は Red Hat Cloud Services ポータルで確認できます。
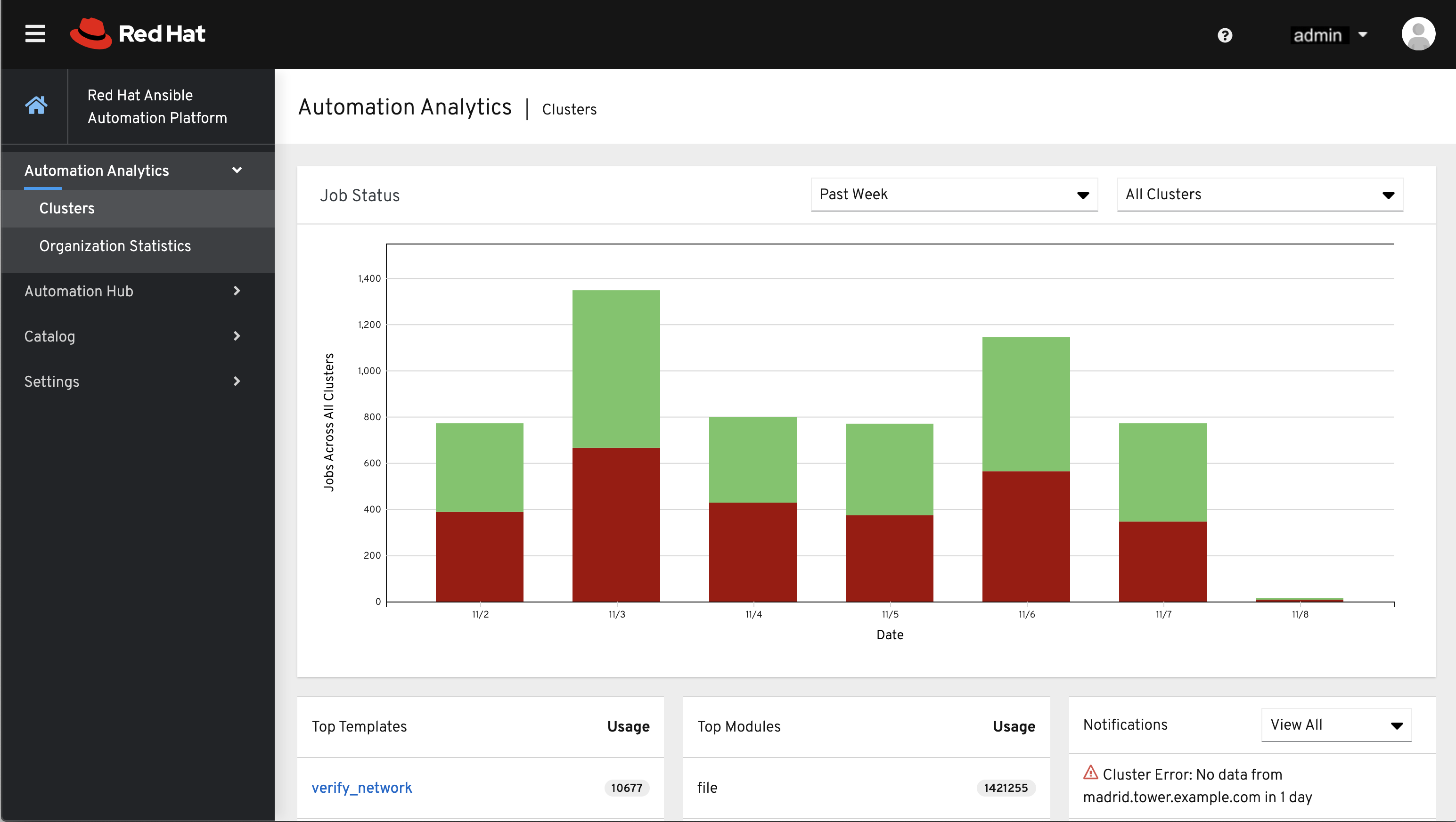
Clusters データはデフォルトのビューです。このグラフは、ある期間において、すべてのコントローラークラスターで実行されているジョブの数を示しています。上記の例は、1 週間の期間を積み重ね棒グラフで表したもので、成功したジョブの数 (緑) と失敗したジョブの数 (赤) で構成されています。
クラスターを 1 つ選択して、そのジョブステータス情報を表示することもできます。
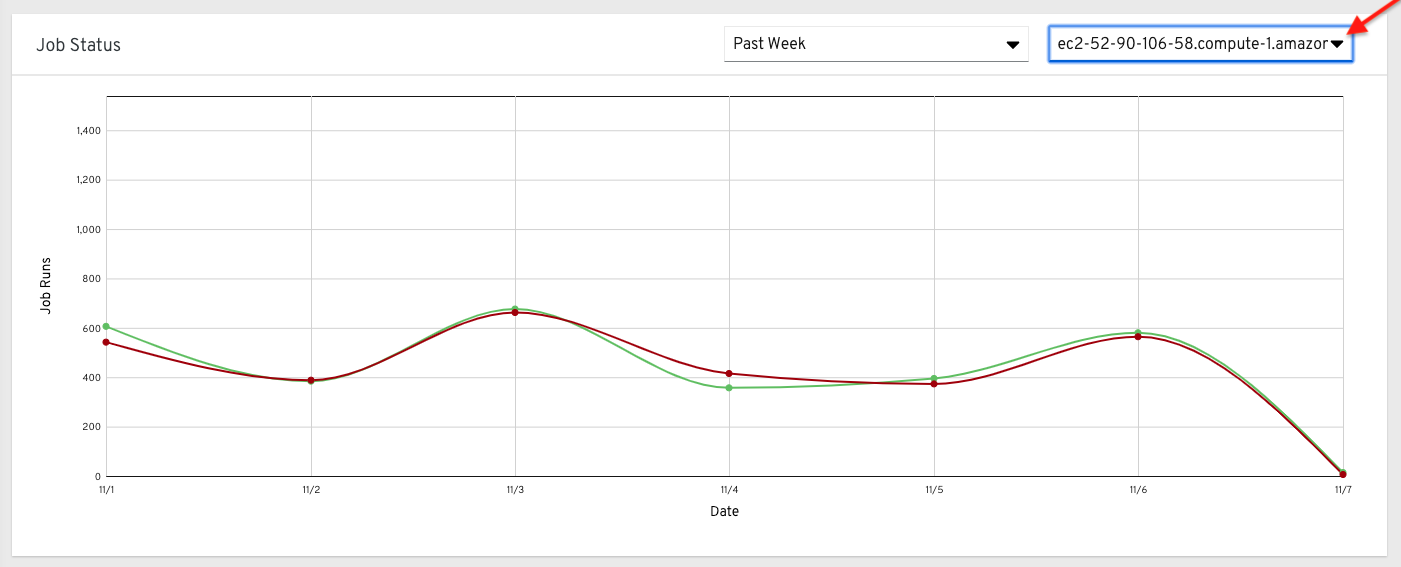
この複数線グラフは、指定の期間における単一のコントローラークラスターのジョブ実行数を表します。この例は、1 週間分表示されており、正常に実行しているジョブ (緑) と失敗したジョブ (赤) の数で整理されています。1 週間、2 週間、および月単位の増分で、選択したクラスターで成功したジョブ数と、失敗したジョブ数を指定できます。
左のナビゲーションペインで Organization Statistics をクリックして、以下の情報を表示します。
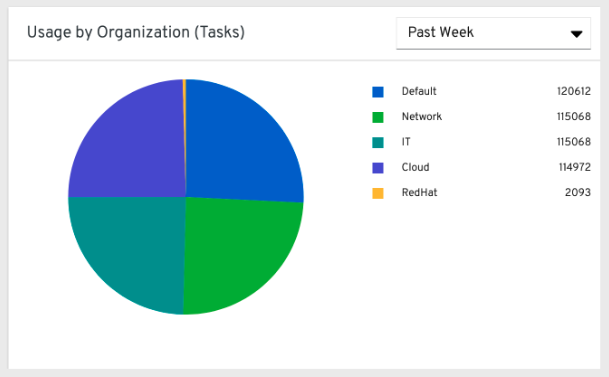
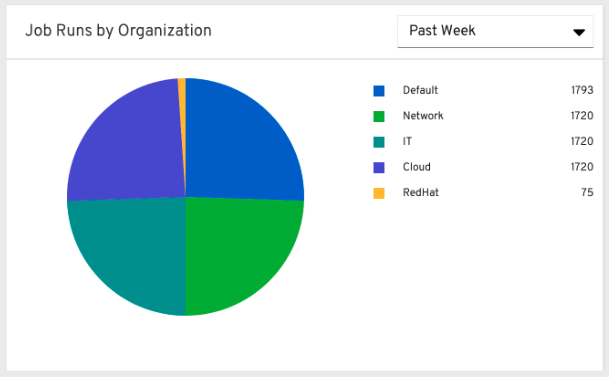
29.1.2. 組織ごとのジョブの実行数¶
この円グラフは、組織ごとの すべての コントローラークラスターでのコントローラーの使用量を表します。これは、その組織で実行されるジョブの数によって計算されます。
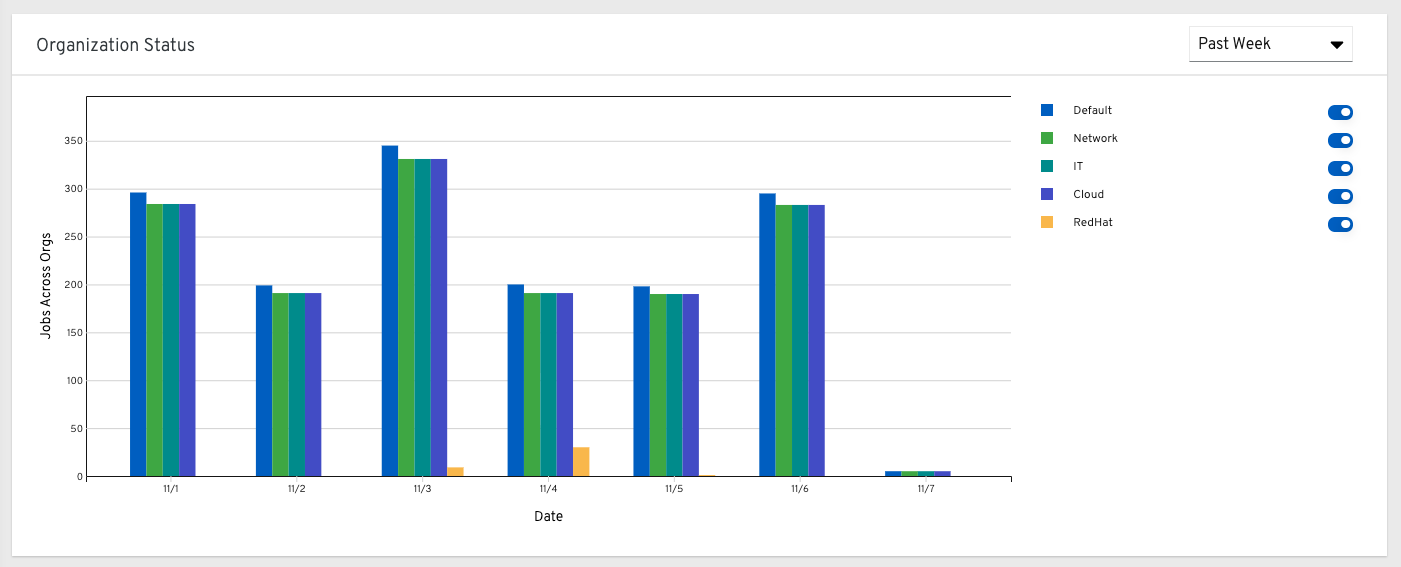
29.1.3. 組織の状態¶
この棒グラフは、組織および日付ごとのコントローラーの使用量を表すもので、特定の日付にその組織が実行したジョブの数によって計算されます。または、1 週間、2 週間、および毎月の増分で、組織ごとのジョブ実行数を表示するように指定することもできます。
29.2. データ収集の詳細¶
Automation Analytics は、automation controller から特定のクラスのデータを収集します。
有効になっている機能や使用されているオペレーティングシステムなどの基本設定
容量とヘルスなど、コントローラー環境とホストのトポロジーおよびステータス
自動化リソースの数:
組織、チーム、ユーザー
インベントリーとホスト
認証情報 (タイプで索引付け)
プロジェクト (タイプで索引付け)
テンプレート
スケジュール
アクティブセッション
実行中および保留中のジョブ
ジョブ実行の詳細 (開始時間、終了時間、起動タイプ、成功)
自動化タスクの詳細 (成功、ホスト ID、Playbook/ロール、タスク名、使用モジュール)
awx-manage gather_analytics (--ship なしで) を使用して、コントローラーが送信するデータを検査し、データ収集の懸念を満たすことができます。これにより、Red Hat に送信される分析データを含む tarball が作成されます。
このファイルには、いくつかの JSON ファイルと CSV ファイルが含まれています。各ファイルには、異なる分析データのセットが含まれています。
29.2.1. manifest.json¶
manifest.json は、分析データのマニフェストです。コレクションに含まれている各ファイルと、そのファイルのスキーマのバージョンが含まれています。マニフェストの例は次のとおりです。
{
"config.json": "1.1",
"counts.json": "1.0",
"cred_type_counts.json": "1.0",
"events_table.csv": "1.1",
"instance_info.json": "1.0",
"inventory_counts.json": "1.2",
"job_counts.json": "1.0",
"job_instance_counts.json": "1.0",
"org_counts.json": "1.0",
"projects_by_scm_type.json": "1.0",
"query_info.json": "1.0",
"unified_job_template_table.csv": "1.0",
"unified_jobs_table.csv": "1.0",
"workflow_job_node_table.csv": "1.0",
"workflow_job_template_node_table.csv": "1.0"
}
29.2.2. config.json¶
config.json ファイルには、クラスターの設定エンドポイント /api/v2/config のサブセットが含まれています。config.json の例は次のとおりです。
{
"ansible_version": "2.9.1",
"authentication_backends": [
"social_core.backends.azuread.AzureADOAuth2",
"django.contrib.auth.backends.ModelBackend"
],
"external_logger_enabled": true,
"external_logger_type": "splunk",
"free_instances": 1234,
"install_uuid": "d3d497f7-9d07-43ab-b8de-9d5cc9752b7c",
"instance_uuid": "bed08c6b-19cc-4a49-bc9e-82c33936e91b",
"license_expiry": 34937373,
"license_type": "enterprise",
"logging_aggregators": [
"awx",
"activity_stream",
"job_events",
"system_tracking"
],
"pendo_tracking": "detailed",
"platform": {
"dist": [
"redhat",
"7.4",
"Maipo"
],
"release": "3.10.0-693.el7.x86_64",
"system": "Linux",
"type": "traditional"
},
"total_licensed_instances": 2500,
"controller_url_base": "https://ansible.rhdemo.io",
"controller_version": "3.6.3"
}
収集されたフィールドのリファレンス:
- ansible_version
ホスト上のシステム Ansible バージョン
- authentication_backends
どのようなユーザー認証バックエンドが利用できるか。詳細は、ソーシャル認証の設定 または LDAP 認証の設定 を参照してください。
- external_logger_enabled
外部ロギングが有効かどうか。
- external_logger_type
有効になっている場合に使用されているロギングバックエンド。詳細は「ロギングおよびアグリゲーション」を参照してください。
- logging_aggregators
外部ロギングに送信されるロギングカテゴリー。詳細は「ロギングおよびアグリゲーション」を参照してください。
- free_instances
ライセンスで利用可能なホストの数。ゼロの値は、クラスターがライセンスを完全に消費していることを意味します。
- install_uuid
インストールの UUID (すべてのクラスターノードで同一)
- instance_uuid
インスタンスの UUID (クラスターノードごとに異なる)
- license_expiry
ライセンスの有効期限 (秒)
- license_type
ライセンスのタイプ (ほとんどの場合「enterprise」である必要があります)
- pendo_tracking
- platform
クラスターが実行されているオペレーティングシステム
- total_licensed_instances
このライセンス内のホストの合計数
- controller_url_base
クライアントが使用するクラスターのベース URL (Automation Analytics に示す)
- controller_version
クラスター上のソフトウェアのバージョン
29.2.3. instance_info.json¶
instance_info.json ファイルには、クラスターを構成するインスタンスの詳細情報がインスタンスの UUID ごとにまとめられています。instance_info.json の例は次のとおりです。
{
"bed08c6b-19cc-4a49-bc9e-82c33936e91b": {
"capacity": 57,
"cpu": 2,
"enabled": true,
"last_isolated_check": "2019-08-15T14:48:58.553005+00:00",
"managed_by_policy": true,
"memory": 8201400320,
"uuid": "bed08c6b-19cc-4a49-bc9e-82c33936e91b",
"version": "3.6.3"
}
"c0a2a215-0e33-419a-92f5-e3a0f59bfaee": {
"capacity": 57,
"cpu": 2,
"enabled": true,
"last_isolated_check": "2019-08-15T14:48:58.553005+00:00",
"managed_by_policy": true,
"memory": 8201400320,
"uuid": "c0a2a215-0e33-419a-92f5-e3a0f59bfaee",
"version": "3.6.3"
}
}
収集されたフィールドのリファレンス:
- capacity
タスクを実行するためのインスタンスの容量。この計算方法の詳細は、「<link>」を参照してください。
- cpu
インスタンスの CPU コア
- memory
インスタンスのメモリー
- enabled
インスタンスが有効でタスクを受け付けているかどうか
- managed_by_policy
インスタンスグループのインスタンスのメンバーシップがポリシーによって管理されているか、手動で管理されているか
- version
インスタンス上のソフトウェアのバージョン
29.2.4. counts.json¶
counts.json ファイルには、クラスター内の関連する各カテゴリーにオブジェクトの総数が含まれています。counts.json の例は次のとおりです:
{
"active_anonymous_sessions": 1,
"active_host_count": 682,
"active_sessions": 2,
"active_user_sessions": 1,
"credential": 38,
"custom_inventory_script": 2,
"custom_virtualenvs": 4,
"host": 697,
"inventories": {
"normal": 20,
"smart": 1
},
"inventory": 21,
"job_template": 78,
"notification_template": 5,
"organization": 10,
"pending_jobs": 0,
"project": 20,
"running_jobs": 0,
"schedule": 16,
"team": 5,
"unified_job": 7073,
"user": 28,
"workflow_job_template": 15
}
このファイルの各エントリーは、アクティブなセッション数を除いて、/api/v2 で対応する API オブジェクト用です。
29.2.5. org_counts.json¶
org_counts.json ファイルには、クラスター内の各組織に関する情報と、その組織に関連付けられているユーザーとチームの数が含まれています。org_counts.json の例は以下のようになります:
{
"1": {
"name": "Operations",
"teams": 5,
"users": 17
},
"2": {
"name": "Development",
"teams": 27,
"users": 154
},
"3": {
"name": "Networking",
"teams": 3,
"users": 28
}
}
29.2.6. cred_type_counts.json¶
cred_type_counts.json ファイルには、クラスター内のさまざまな認証情報のタイプ、および各タイプに存在する認証情報の数に関する情報が含まれています。cred_type_counts.json の例は次のとおりです:
{
"1": {
"credential_count": 15,
"managed_by_controller": true,
"name": "Machine"
},
"2": {
"credential_count": 2,
"managed_by_controller": true,
"name": "Source Control"
},
"3": {
"credential_count": 3,
"managed_by_controller": true,
"name": "Vault"
},
"4": {
"credential_count": 0,
"managed_by_controller": true,
"name": "Network"
},
"5": {
"credential_count": 6,
"managed_by_controller": true,
"name": "Amazon Web Services"
},
"6": {
"credential_count": 0,
"managed_by_controller": true,
"name": "OpenStack"
},
...
29.2.7. inventory_counts.json¶
inventory_counts.json ファイルには、クラスター内のさまざまなインベントリーに関する情報が含まれています。以下は、inventory_counts.json の例です:
{
"1": {
"hosts": 211,
"kind": "",
"name": "AWS Inventory",
"source_list": [
{
"name": "AWS",
"num_hosts": 211,
"source": "ec2"
}
],
"sources": 1
},
"2": {
"hosts": 15,
"kind": "",
"name": "Manual inventory",
"source_list": [],
"sources": 0
},
"3": {
"hosts": 25,
"kind": "",
"name": "SCM inventory - test repo",
"source_list": [
{
"name": "Git source",
"num_hosts": 25,
"source": "scm"
}
],
"sources": 1
}
"4": {
"num_hosts": 5,
"kind": "smart",
"name": "Filtered AWS inventory",
"source_list": [],
"sources": 0
}
}
29.2.8. projects_by_scm_type.json¶
projects_by_scm_type.json ファイルは、ソース管理タイプごとに、クラスタ内のすべてのプロジェクトの内訳を提供します。projects_by_scm_type.json の例は次のとおりです:
{
"git": 27,
"hg": 0,
"insights": 1,
"manual": 0,
"svn": 0
}
29.2.9. query_info.json¶
query_info.json ファイルは、データ収集がいつどのように行われたかについての詳細を提供します。query_info.json の例は次のとおりです。
{
"collection_type": "manual",
"current_time": "2019-11-22 20:10:27.751267+00:00",
"last_run": "2019-11-22 20:03:40.361225+00:00"
}
collection_type は、「手動」または「自動」のいずれかです。
29.2.10. job_counts.json¶
job_counts.json ファイルは、クラスターのジョブ履歴の詳細を提供し、ジョブの起動方法とジョブの終了ステータスの両方を記述します。job_counts.json の例は次の通りです:
{
"launch_type": {
"dependency": 3628,
"manual": 799,
"relaunch": 6,
"scheduled": 1286,
"scm": 6,
"workflow": 1348
},
"status": {
"canceled": 7,
"failed": 108,
"successful": 6958
},
"total_jobs": 7073
}
29.2.11. job_instance_counts.json¶
job_instance_counts.json ファイルは、job_counts.json と同じ詳細をインスタンスごとに提供します。job_instance_counts.json の例は次の通りです:
{
"localhost": {
"launch_type": {
"dependency": 3628,
"manual": 770,
"relaunch": 3,
"scheduled": 1009,
"scm": 6,
"workflow": 1336
},
"status": {
"canceled": 2,
"failed": 60,
"successful": 6690
}
}
}
このファイルのインスタンスは、instance_info にあるような UUID ではなく、ホスト名によるものであることに注意してください。
29.2.12. unified_job_template_table.csv¶
unified_job_template_table.csv ファイルは、システム内のジョブテンプレートに関する情報を提供します。各行には、ジョブテンプレートの次のフィールドが含まれています。
- id
ジョブテンプレート ID
- name
ジョブテンプレート名
- polymorphic_ctype_id
テンプレートのタイプの ID
- model
テンプレートの polymorphic_ctype_id の名前。例には、「project」、「systemjobtemplate」、「jobtemplate」、「inventorysource」、および「workflowjobtemplate」が含まれます
- created
テンプレートが作成されたとき
- modified
テンプレートが最後に更新された日時
- created_by_id
テンプレートを作成したユーザー ID。システムによって実行された場合は空白です。
- modified_by_id
テンプレートを最後に変更したユーザー ID。システムによって実行された場合は空白です。
- current_job_id
テンプレートの現在実行中のジョブ ID (存在する場合)
- last_job_id
ジョブの最後の実行
- last_job_run
ジョブが最後に実行された時刻
- last_job_failed
last_job_id が失敗したかどうか
- status
last_job_id のステータス
- next_job_run
テンプレートで次にスケジュールされた実行 (該当する場合)
- next_schedule_id
next_job_run のスケジュール ID (該当する場合)
29.2.13. unified_jobs_table.csv¶
unified_jobs_table.csv ファイルは、システムによって実行されるジョブに関する情報を提供します。各行には、ジョブの次のフィールドが含まれています。
- id
ジョブ ID
- name
ジョブ名 (テンプレートから)
- polymorphic_ctype_id
職種の ID。
- model
そのジョブの polymorphic_ctype_id の名前。例としては、「job」、「worfklow」などがあります。
- organization_id
ジョブの組織 ID
- organization_name
organization_id の名前
- created
ジョブレコードが作成されたとき
- started
ジョブが実行を開始したとき
- finished
ジョブが終わったとき
- elapsed
秒単位でのジョブの経過時間
- unified_job_template_id
このジョブのテンプレート
- launch_type
「manual」、「scheduled」、「relaunched」、「scm」、「workflow」、または「dependnecy」のいずれか
- schedule_id
このジョブを起動したスケジュールの ID (該当する場合)
- instance_group_id
ジョブを実行したインスタンスグループ
- execution_node
ジョブを実行したノード (UUID ではなくホスト名)
- controller_node
分離されたジョブとして実行される場合、またはコンテナーグループ内で実行される場合、ジョブのコントローラーノード
- cancel_flag
ジョブがキャンセルされたかどうか
- status
ジョブのステータス
- 失敗
ジョブが失敗したかどうか
- job_explanation
適切に実行できなかったジョブの追加の詳細
- forks
このジョブで実行されたフォークの数
29.2.14. workflow_job_template_node_table.csv¶
workflow_job_template_node_table.csv は、システムのワークフロージョブテンプレートで定義されるノードの情報を提供します。
各行には、ワークフローのジョブテンプレートノードに以下のフィールドが含まれます。
- id
Node id
- created
ノードが作成された日時
- modified
ノードが最後に更新された日時
- unified_job_template_id
このノードのジョブテンプレート、プロジェクト、インベントリー、またはその他の親リソースの ID
- workflow_job_template_id
このノードを含むワークフローのジョブテンプレート
- inventory_id
このノードによって使用されるインベントリー
- success_nodes
このノードに成功するとトリガーされるノード
- failure_nodes
このノードに障害が発生した後にトリガーされるノード
- always_nodes
このノードの終了後に常にトリガーされるノード
- all_parents_must_converge
このノードが開始するためにすべての親条件が満たされる必要があるかどうか
29.2.15. workflow_job_node_table.csv¶
workflow_job_node_table.csv は、システム上のワークフローの一部として実行されたジョブに関する情報を提供します。
各行には、ワークフローの一部として実行されるジョブに次のフィールドが含まれています。
- id
Node id
- created
ノードレコードが作成された日時
- modified
ノードレコードの最終更新時
- job_id
このノードのジョブ実行のジョブ ID
- unified_job_tempalte_id
このジョブ実行のジョブテンプレート、プロジェクト、インベントリー、またはその他の親リソースの ID
- workflow_job_id
このジョブの親ワークフロージョブの実行
- inventory_id
このジョブによって使用されるインベントリー
- success_nodes
このノードが成功した後にトリガーされた、またはトリガーされるノード
- failure_nodes
このノードが失敗した後にトリガーされた、またはトリガーされるノード
- always_nodes
このノードの終了後にトリガーされた、またはトリガーされるノード
- do_not_run
開始条件がトリガーされていないためにワークフローで実行されなかったノード
- all_parents_must_converge
このノードが開始するためにすべての親条件が満たされる必要があるかどうか
29.2.16. events_table.csv¶
events_table.csv ファイルは、システム内のすべてのジョブ実行からのすべてのジョブイベントに関する情報を提供します。各行には、ジョブイベントの次のフィールドが含まれています。
- id
イベント ID
- uuid
イベント UUID
- created
イベントが作成されたとき
- parent_uuid
このイベントの親 UUID (存在する場合)
- イベント
Ansible イベントタイプ (runner_on_failed など)
- task_action
このイベントに関連付けられているモジュール (存在する場合) (「command」または「yum」など)
- 失敗
イベントが「失敗」を返したかどうか
- changed
イベントが「変更」を返したかどうか
- playbook
イベントに関連付けられた Playbook
- play
Playbook から名前を再生
- task
Playbook のタスク名
- role
Playbook のロール名
- job_id
このイベントが発生したジョブの ID
- host_id
このイベントが関連付けられているホストの ID (存在する場合)
- host_name
このイベントが関連付けられているホストの名前 (存在する場合)
- start
タスクの開始時間
- end
タスクの終了時間
- duration
タスクの期間
- warnings
タスク/モジュールからのすべての警告
- deprecations
タスク/モジュールから非推奨となった警告