28. 使用情况分析和数据收集¶
Usability data collection is included with automation controller to collect data to better understand how controller users specifically interact with it, to help enhance future releases, and to continue streamlining your user experience.
Only users installing a trial of Red Hat Ansible Automation Platform or a fresh installation of automation controller are opted-in for this data collection.
如果想改变如何参与这个分析的行为,可以改变 User Interface settings 中的设置(在左面浏览栏中点 Settings)。
Automation controller collects user data automatically to help improve the product. You can control the way the controller collects data by setting your participation level in the User Interface settings in the Settings menu.
从 User Tracking State 下拉列表中选择所需的数据收集级别:
Off: 禁用数据收集。
Anonymous: 启用数据收集功能,但不会收集您的特定用户数据。
Detailed: 启用数据收集功能,其中包括您的特定用户数据。
点击 Save 应用设置,或者点 Cancel 取消更改。
如需更多信息,请参阅红帽隐私政策 https://www.redhat.com/en/about/privacy-policy.
28.1. 自动化分析¶
当您首次导入许可证时,会为您提供与收集 Automation Analytics (Ansible Automation Platform 订阅中的一个云服务)数据相关的选项。为了使 Automation Analytics 起作用,您的 automation controller 实例**必须**在 Red Hat Enterprise Linux 上运行。
类似于 Red Hat Insights,Automation Analytics 只收集所需最小数据,它不会收集凭证 secret、个人数据、自动化变量或任务输出。如需更多信息,请参阅 Details of data collection。
要启用这个功能,为 Automation Analytics 打开数据收集功能,在 Settings 菜单中的系统配置选项列表的 Miscellaneous System settings 中输入您的红帽客户凭证。
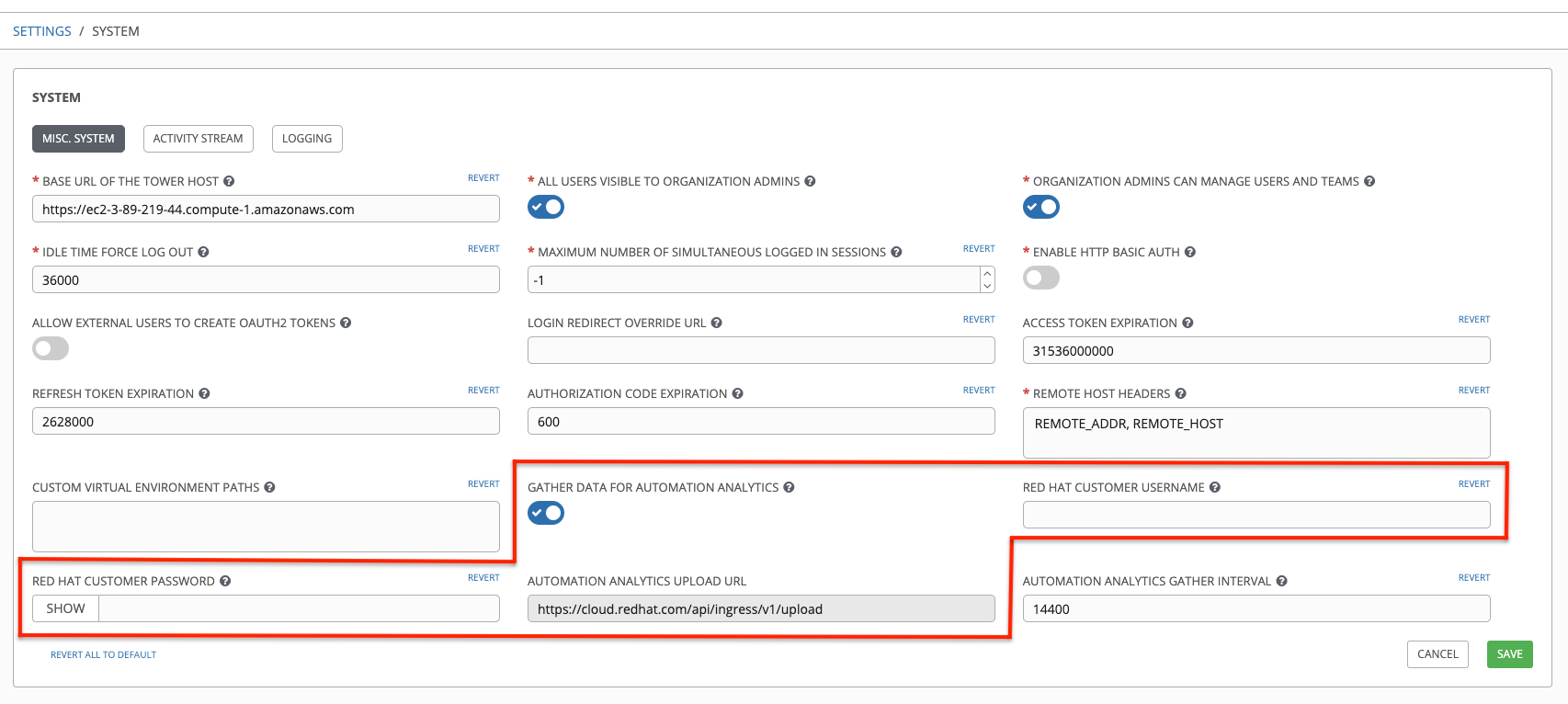
请注意:Automation Analytics Upload URL 字段预先填充位置,收集的洞察数据将上传到该位置。
默认情况下,Automation Analytics 数据会在每 4 小时收集一次,并在启用该功能时,会收集前一个月内的数据(或者直到上次收集)。您可以随时使用 System 配置窗口中的 Miscellaneous System settings 中关闭这个数据收集功能。
此设置也可以通过 API 在其中任何一个端点中指定 INSIGHTS_TRACKING_STATE = True 来启用:
api/v2/settings/allapi/v2/settings/system
这个数据收集所生成的 Automation Analytics 可以在`Red Hat Cloud Services`_ 门户中找到。
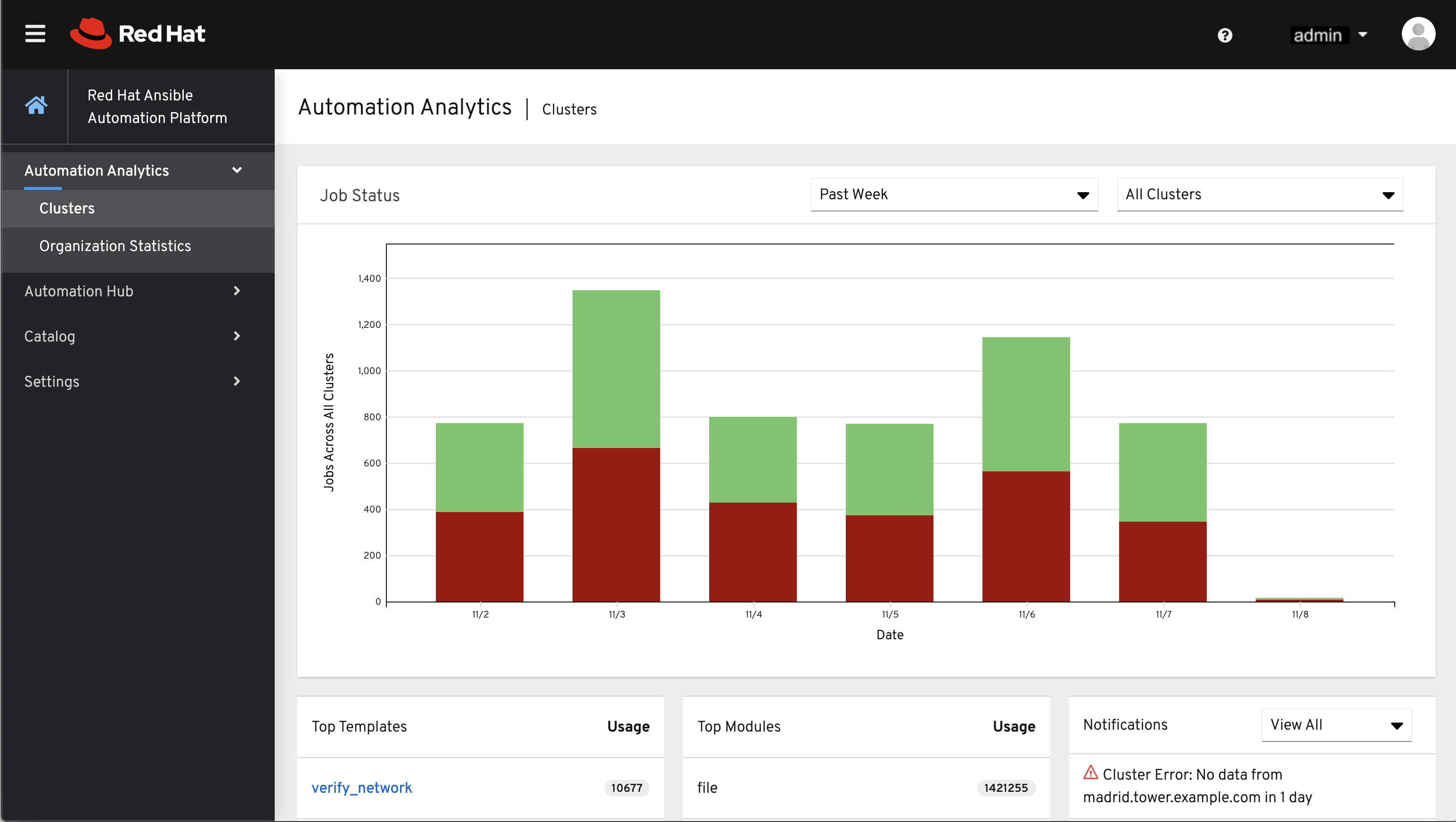
Clusters 数据是默认视图。此图表示一段时间内在所有控制器主机上运行的作业的数量。上例以堆叠的条形图样式显示一周时间跨度,图表由成功运行(绿色)和运行失败(红色)的作业数量组成。
或者,您可以选择单个集群来查看其作业状态信息。
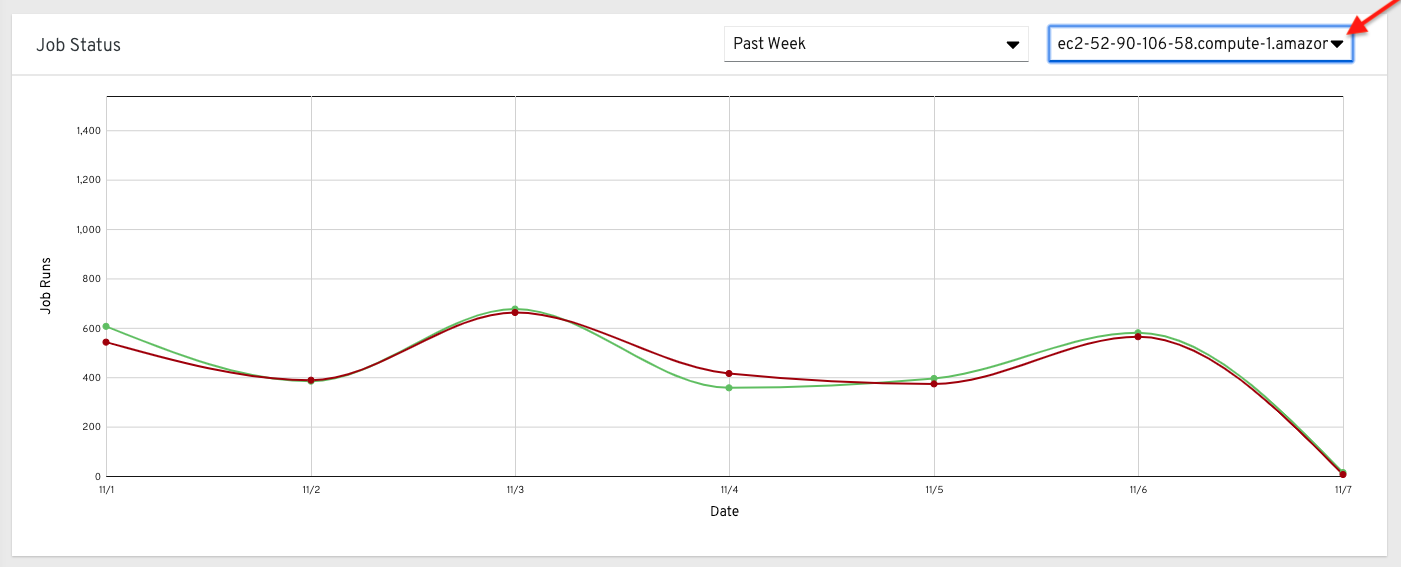
这个多行图表代表在指定时间内为单个控制器集群运行的作业数量。这里的示例显示了一个星期跨度,由成功运行的作业(绿色)和运行失败的作业(红色)组成。您可以指定在一个周、两周以及每月递增的时间跨度内,为所选集群成功运行和运行失败的作业数量。
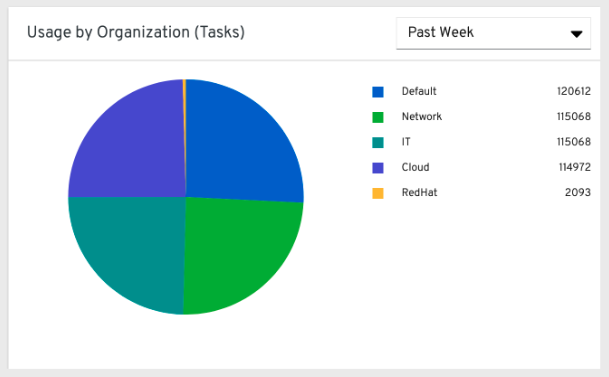
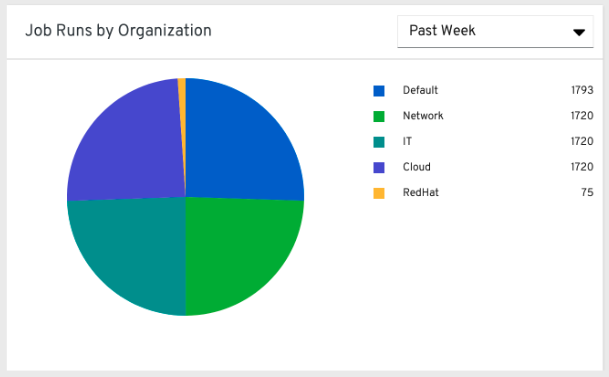
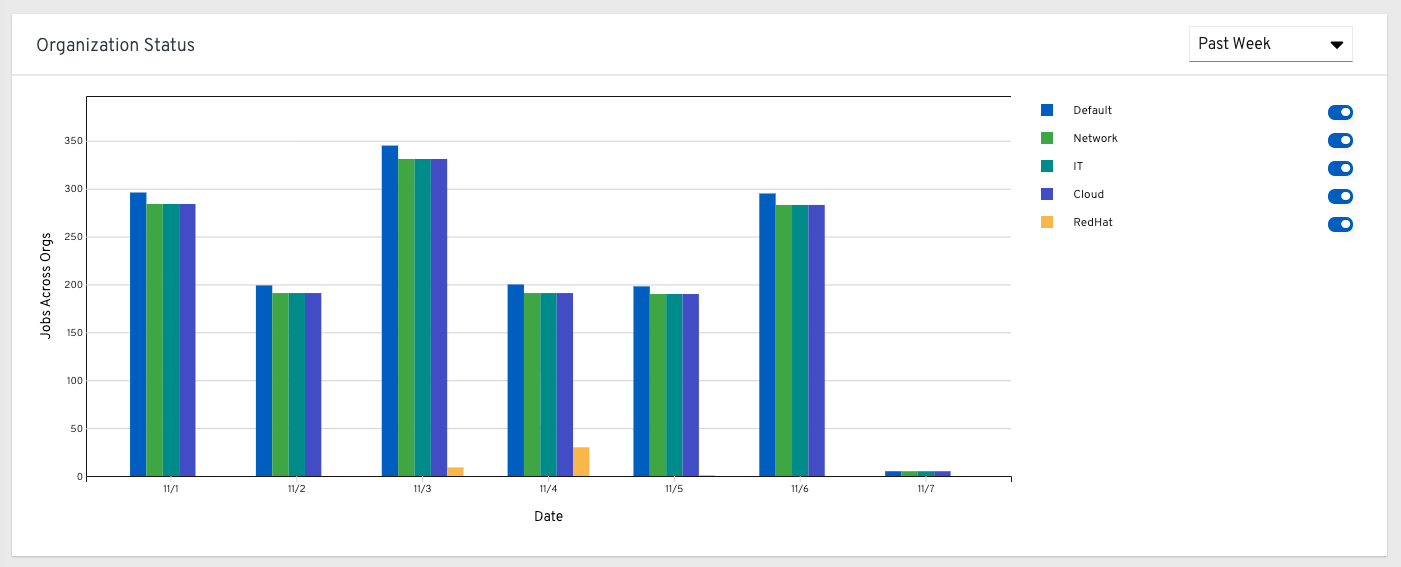
从在左侧导航窗格中,点击 Organization Statistics,查看以下信息:
28.2. 数据收集细节¶
Automation Analytics 从 automation controller 收集特定的数据 :
基本配置,比如启用了哪些功能,以及使用什么操作系统
控制器环境和主机的拓扑和状态,包括容量和健康状况
自动化资源的计数:
机构、团队和用户
清单和主机
凭证(按类型索引)
项目(按类型索引)
模板
调度
活跃会话
运行中和待处理的作业
作业执行详情(启动时间、完成时间、启动类型和成功)
自动化任务详情(成功、主机 id、playbook/role、任务名称以及所使用的模块)
您可以使用 awx-manage gather_analytics (没有 --ship)检查控制器发送的数据,从而消除对数据收集问题的担心。这将创建一个 tarball,其中包含发送到红帽的分析数据。
此文件包含多个 JSON 和 CSV 文件,每个文件都包含一组不同的分析数据。
28.2.1. manifest.json¶
manifest.json 是分析数据的清单。它描述了集合中包含的每个文件,以及该文件的 schema 版本。例如:
{
"config.json": "1.1",
"counts.json": "1.0",
"cred_type_counts.json": "1.0",
"events_table.csv": "1.1",
"instance_info.json": "1.0",
"inventory_counts.json": "1.2",
"job_counts.json": "1.0",
"job_instance_counts.json": "1.0",
"org_counts.json": "1.0",
"projects_by_scm_type.json": "1.0",
"query_info.json": "1.0",
"unified_job_template_table.csv": "1.0",
"unified_jobs_table.csv": "1.0",
"workflow_job_node_table.csv": "1.0",
"workflow_job_template_node_table.csv": "1.0"
}
28.2.2. config.json¶
config.json 文件包含来自集群的配置端点 /api/v2/config 的子集。以下是一个 config.json 示例:
{
"ansible_version": "2.9.1",
"authentication_backends": [
"social_core.backends.azuread.AzureADOAuth2",
"django.contrib.auth.backends.ModelBackend"
],
"external_logger_enabled": true,
"external_logger_type": "splunk",
"free_instances": 1234,
"install_uuid": "d3d497f7-9d07-43ab-b8de-9d5cc9752b7c",
"instance_uuid": "bed08c6b-19cc-4a49-bc9e-82c33936e91b",
"license_expiry": 34937373,
"license_type": "enterprise",
"logging_aggregators": [
"awx",
"activity_stream",
"job_events",
"system_tracking"
],
"pendo_tracking": "detailed",
"platform": {
"dist": [
"redhat",
"7.4",
"Maipo"
],
"release": "3.10.0-693.el7.x86_64",
"system": "Linux",
"type": "traditional"
},
"total_licensed_instances": 2500,
"controller_url_base": "https://ansible.rhdemo.io",
"controller_version": "3.6.3"
}
到收集字段的参考:
- ansible_version
主机上的系统 Ansible 版本
- authentication_backends
可用的用户身份验证后端是什么。如需更多信息,请参阅 设置社交身份认证 或 设置 LDAP 身份验证。
- external_logger_enabled
是否启用外部日志
- external_logger_type
如果启用,使用什么日志后端。如需了解详细信息,请参阅 日志记录和聚合
- logging_aggregators
将哪些日志类别发送到外部日志记录。如需了解详细信息,请参阅 日志记录和聚合
- free_instances
许可证中包括多少个可用的主机。如果为零,则表示集群已完全消耗了它的许可证。
- install_uuid
安装的 UUID(在所有集群节点中是相同的)
- instance_uuid
实例的 UUID(每个集群节点是不同的)
- license_expiry
许可证过期的时间,以秒为单位
- license_type
许可证类型(在大多数情况下都应为 'enterprise')
- pendo_tracking
使用情况分析和数据收集 的状态
- platform
集群正在运行的操作系统
- total_licensed_instances
许可证中的主机总数
- controller_url_base
客户端使用的集群基本 URL(在 Automation Analytics 中显示)
- controller_version
集群中的软件版本
28.2.3. instance_info.json¶
instance_info.json 文件包含组成集群的实例的详细信息,由实例 UUID 进行组织。以下是一个 instance_info.json 示例:
{
"bed08c6b-19cc-4a49-bc9e-82c33936e91b": {
"capacity": 57,
"cpu": 2,
"enabled": true,
"last_isolated_check": "2019-08-15T14:48:58.553005+00:00",
"managed_by_policy": true,
"memory": 8201400320,
"uuid": "bed08c6b-19cc-4a49-bc9e-82c33936e91b",
"version": "3.6.3"
}
"c0a2a215-0e33-419a-92f5-e3a0f59bfaee": {
"capacity": 57,
"cpu": 2,
"enabled": true,
"last_isolated_check": "2019-08-15T14:48:58.553005+00:00",
"managed_by_policy": true,
"memory": 8201400320,
"uuid": "c0a2a215-0e33-419a-92f5-e3a0f59bfaee",
"version": "3.6.3"
}
}
到收集字段的参考:
- capacity
实例执行任务的能力。如需了解如何计算这个值,请参阅 <link>。
- CPU
实例的 CPU 内核
- memory
实例的内存
- enabled
该实例是否已启用并在接受任务
- managed_by_policy
实例在实例组中的成员资格是否由策略管理,还是手动管理
- version
实例中软件的版本
28.2.4. counts.json¶
counts.json 文件包含集群中每个相关类别的对象总数。一个示例 counts.json 是:
{
"active_anonymous_sessions": 1,
"active_host_count": 682,
"active_sessions": 2,
"active_user_sessions": 1,
"credential": 38,
"custom_inventory_script": 2,
"custom_virtualenvs": 4,
"host": 697,
"inventories": {
"normal": 20,
"smart": 1
},
"inventory": 21,
"job_template": 78,
"notification_template": 5,
"organization": 10,
"pending_jobs": 0,
"project": 20,
"running_jobs": 0,
"schedule": 16,
"team": 5,
"unified_job": 7073,
"user": 28,
"workflow_job_template": 15
}
此文件的每个条目都用于 /api/v2 中的对应 API 对象,但活跃会话计数除外。
28.2.5. org_counts.json¶
org_counts.json 文件包含集群中每个机构的信息,以及与该机构关联的用户和团队的数量。一个 org_counts.json 示例:
{
"1": {
"name": "Operations",
"teams": 5,
"users": 17
},
"2": {
"name": "Development",
"teams": 27,
"users": 154
},
"3": {
"name": "Networking",
"teams": 3,
"users": 28
}
}
28.2.6. cred_type_counts.json¶
cred_type_counts.json 文件包含集群中不同凭据类型的信息,以及每种类型的凭据数量。一个 cred_type_counts.json 示例:
{
"1": {
"credential_count": 15,
"managed_by_controller": true,
"name": "Machine"
},
"2": {
"credential_count": 2,
"managed_by_controller": true,
"name": "Source Control"
},
"3": {
"credential_count": 3,
"managed_by_controller": true,
"name": "Vault"
},
"4": {
"credential_count": 0,
"managed_by_controller": true,
"name": "Network"
},
"5": {
"credential_count": 6,
"managed_by_controller": true,
"name": "Amazon Web Services"
},
"6": {
"credential_count": 0,
"managed_by_controller": true,
"name": "OpenStack"
},
...
28.2.7. inventory_counts.json¶
iventory_counts.json 文件包含集群中不同清单的信息。一个 inventory_counts.json 示例:
{
"1": {
"hosts": 211,
"kind": "",
"name": "AWS Inventory",
"source_list": [
{
"name": "AWS",
"num_hosts": 211,
"source": "ec2"
}
],
"sources": 1
},
"2": {
"hosts": 15,
"kind": "",
"name": "Manual inventory",
"source_list": [],
"sources": 0
},
"3": {
"hosts": 25,
"kind": "",
"name": "SCM inventory - test repo",
"source_list": [
{
"name": "Git source",
"num_hosts": 25,
"source": "scm"
}
],
"sources": 1
}
"4": {
"num_hosts": 5,
"kind": "smart",
"name": "Filtered AWS inventory",
"source_list": [],
"sources": 0
}
}
28.2.8. projects_by_scm_type.json¶
pojects_by_scm_type.json 文件根据源控制类型提供集群中的所有项目。一个 projects_by_scm_type.json 示例:
{
"git": 27,
"hg": 0,
"insights": 1,
"manual": 0,
"svn": 0
}
28.2.9. query_info.json¶
query_info.json 文件详细介绍了数据收集何时及如何发生。一个 query_info.json 示例:
{
"collection_type": "manual",
"current_time": "2019-11-22 20:10:27.751267+00:00",
"last_run": "2019-11-22 20:03:40.361225+00:00"
}
collection_type 是 “manual” 或 “automatic” 中的一个。
28.2.10. job_counts.json¶
job_counts.json 文件提供集群作业历史记录的详细信息,描述如何启动作业及其完成状态。一个 job_counts.json 示例:
{
"launch_type": {
"dependency": 3628,
"manual": 799,
"relaunch": 6,
"scheduled": 1286,
"scm": 6,
"workflow": 1348
},
"status": {
"canceled": 7,
"failed": 108,
"successful": 6958
},
"total_jobs": 7073
}
28.2.11. job_instance_counts.json¶
job_instance_counts.json 文件提供与 job_counts.json 相同的详细信息,按照实例划分。一个 job_instance_counts.json 示例:
{
"localhost": {
"launch_type": {
"dependency": 3628,
"manual": 770,
"relaunch": 3,
"scheduled": 1009,
"scm": 6,
"workflow": 1336
},
"status": {
"canceled": 2,
"failed": 60,
"successful": 6690
}
}
}
请注意,这个文件中的实例是主机名,而在 instance_info 中是 UUID。
28.2.12. unified_job_template_table.csv¶
unified_job_template_table.csv 文件提供系统中作业模板的信息。每行都包含作业模板的以下字段:
- id
作业模板的 ID
- 名称
作业模板名称
- polymorphic_ctype_id
模板类型的 id
- model
模板的 polymorphic_ctype_id。示例包括 'project', 'systemjobtemplate', 'jobtemplate', 'inventorysource' 和 'workflowjobtemplate'
- created
模板创建的时间
- modified
模板最后一次更新的时间
- created_by_id
创建模板的 userid。如果由系统创建,则为空。
- modified_by_id
上一次修改模板的 userid。如果由系统修改,则为空。
- current_job_id
目前为模板执行的作业 id(如果存在)
- last_job_id
作业最后一次执行
- last_job_run
作业最后一次执行的时间
- last_job_failed
last_job_id 是否失败
- status
last_job_id 的状态
- next_job_run
模板的下一次调度执行(若有)
- next_schedule_id
next_job_run 的调度 ID,如果存在
28.2.13. unified_jobs_table.csv¶
unified_jobs_table.csv 文件提供了有关系统运行的作业的信息,每行包含作业的以下字段:
- id
Job id
- 名称
作业名称(从模板中)
- polymorphic_ctype_id
作业类型的 id
- model
作业的 polymorphic_ctype_id 的名称。示例包括 'job'、'worfklow' 等等。
- organization_id
作业的机构 ID
- organization_name
organization_id 的名称
- created
作业记录创建的时间
- started
作业开始执行的时间
- finished
作业完成的时间
- elapsed
作业已经过的时间(以秒为单位)
- unified_job_template_id
此任务的模板
- launch_type
"manual", "scheduled", "relaunched", "scm", "workflow", 或 "dependnecy" 中的一个
- schedule_id
启动了此作业的调度的 ID(如果存在)
- instance_group_id
执行作业的实例组
- execution_node
执行作业的节点(主机名,而不是 UUID)
- controller_node
作业的控制器节点,如果作为隔离作业运行,或者在容器组中
- cancel_flag
该作业是否被取消
- status
作业状态
- 失败
作业是否失败
- job_explanation
无法正确执行作业的附加详情
- forks
为此作业执行的 fork 数量
28.2.14. workflow_job_template_node_table.csv¶
workflow_job_template_node_table.csv 提供系统工作流作业模板中定义的节点的信息。
每行包含 一 个 worfklow 作业模板节点的以下字段:
- id
节点 ID
- created
节点创建的时间
- modified
节点最后一次更新的时间
- unified_job_template_id
此节点的作业模板、项目、清单或其他父资源的 id
- workflow_job_template_id
包含此节点的工作流任务模板
- inventory_id
此节点使用的清单
- success_nodes
此节点成功后触发的节点
- failure_nodes
此节点失败后触发的节点
- always_nodes
此节点完成后始终触发的节点
- all_parents_must_converge
此节点是否需要满足其所有父条件才能启动
28.2.15. workflow_job_node_table.csv¶
workflow_job_node_table.csv 提供了作为系统工作流一部分执行的作业的信息。
每行包含作为工作流一部分运行的作业的以下字段:
- id
节点 ID
- created
作业记录创建的时间
- modified
最后更新节点记录的时间
- job_id
此节点的作业运行的作业 id
- unified_job_tempalte_id
此作业运行的作业模板、项目、清单或其他父资源的 ID
- workflow_job_id
此作业运行的父工作流任务
- inventory_id
此作业使用的清单
- success_nodes
此节点成功后被触发的节点
- failure_nodes
此节点失败后被触发的节点
- always_nodes
此节点完成后被触发的节点
- do_not_run
因启动条件没有被触发而无法在工作流中运行的节点
- all_parents_must_converge
此节点是否需要满足其所有父条件才能启动
28.2.16. events_table.csv¶
events_table.csv 文件提供了系统中运行的所有作业事件的信息。每行包括一个作业事件的以下字段:
- id
事件 ID
- uuid
事件 UUID
- created
事件创建的时间
- parent_uuid
此事件的父 UUID,如果存在
- event
Ansible 事件类型(如 runner_on_failed)
- task_action
与这个事件关联的模块(如果有的话)(比如 'command' 或 'yum')
- 失败
事件是否返回 "failed"
- changed
事件是否返回 "changed"
- playbook
与事件关联的 playbook
- play
来自 playbook 的 play 名称
- task
playbook 的任务名称
- role
来自 playbook 的角色名称
- job_id
此事件来自于的作业 ID
- host_id
此事件相关联的主机 ID (若有)
- host_name
此事件相关联的主机名称(若有)
- start
任务开始的时间
- end
任务结束的时间
- duration
任务持续的时间
- warnings
任务/模块中的任何警告
- deprecations
任务/模块中的任何弃用警告