5. クラスタリング¶
Ansible Tower 3.1 では、冗長化の代わりのアプローチとしてクラスタリングが導入され、プライマリーインスタンスとセカンダリーインスタンスを使用する active-passive ノードで設定されていた冗長化ソリューションの後継となります。3.1 より前のバージョンは、以前のバージョンの Ansible Tower Administration Guide のクラスタリングの章を参照してください。
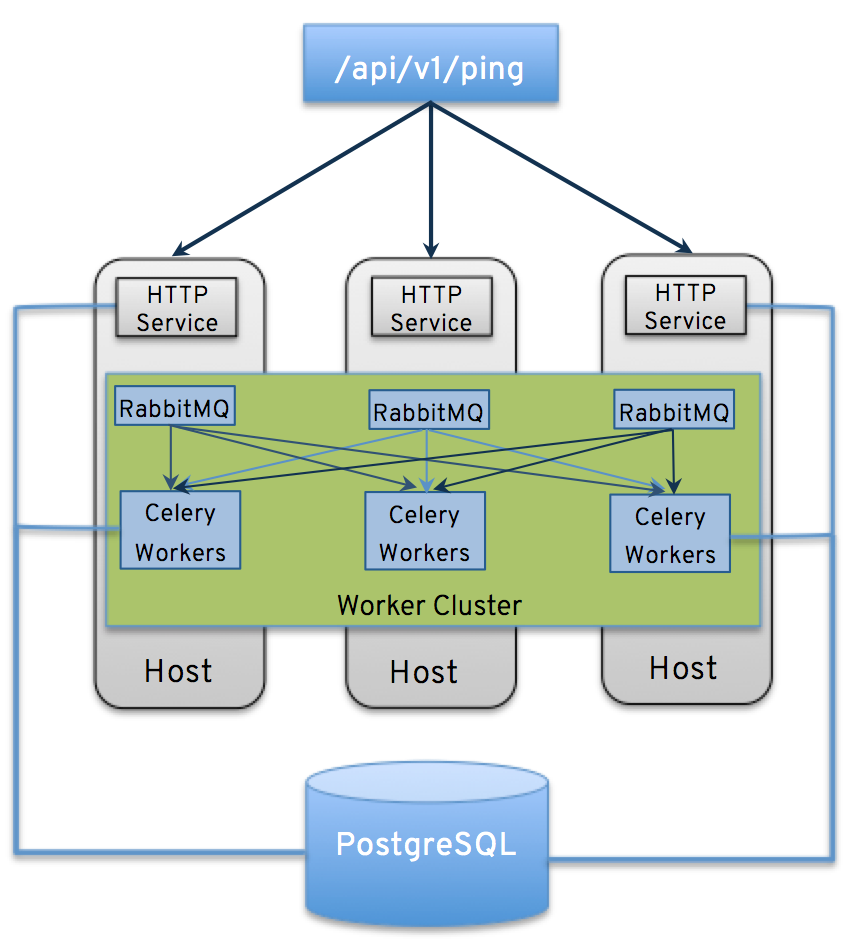
クラスタリングでは、ホスト間で負荷が共有されます。各ノードは、UI および API アクセスのエントリーポイントとして機能します。これにより、Tower の管理者が複数のノードの手前でロードバランサーを使用できるようになり、データの可視性が向上されるはずです。
注釈
負荷分散はオプションで、必要に応じて 1 つまたはすべてのノードで受信することも可能です。
各ノードは、Tower のクラスターに参加して、ジョブの実行機能を拡張することができます。現在これは簡単なシステムになっており、ジョブの実行場所を指定するのではなく、ジョブをどこでも実行できます。
5.1. 設定の留意事項¶
新規クラスタリング環境における重要な留意事項:
- PostgreSQL は、まだスタンドアロンのインスタンスノードで、クラスター化されていません。Tower はレプリカ設定やデータベースのフェイルオーバーを管理しません (ユーザーが待機レプリカを設定した場合)。
- 全ノードは、他のすべてのノードから到達でき、データベースにアクセスできる必要があります。ホストに安定したアドレスおよび/またはホスト名を指定することも重要です (Tower ホストの設定方法により異なる)。
- RabbitMQ は、Tower のクラスタリングシステムには不可欠です。設定要件や動作の多くは、それぞれのニーズにより決まるので、Tower の設定 Playbook に含まれないカスタマイズには制約があります。各 Tower ノードには、RabbitMQ のデプロイメントが含まれており、他のノードの RabbitMQ インスタンスと合わせてクラスタリングされます。
- 既存の旧式の HA デプロイメントは、アップグレードプロセス中に、自動的に新しい HA システムに移行されます。
- 手動のプロジェクトでは、顧客が手動で全ノードを同期して、一度に全ノードを更新する必要があります。
- 新しい Tower システムにはプライマリー/セカンダリーのコンセプトはありません。システムはすべてプライマリーです。
- 設定 Playbook は RabbitMQ を設定したり、ホストが使用するネットワークタイプを提供したり変化します。
- Tower デプロイメントの
inventoryファイルは保存/永続化する必要があります。新規ノードをプロビジョニングする場合は、パスワード、設定オプション、ホスト名をインストーラーで利用できるようにしなければなりません。
5.2. インストールおよび設定¶
新規ノードのプロビジョニングは、inventory ファイルを更新して、設定 Playbook を再実行するだけです。このファイルには、クラスターのインストール時に使用するすべてのパスワードと情報が含まれていることが重要です。含まれていない場合には、他のノードが再設定される場合があります。現在のスタンドアロンのノード設定は、3.1 のデプロイメントでは変更はありません。inventory ファイルには重要な変更が含まれています。
- プライマリー/セカンダリーの設定がないので、このようなインベントリーグループはなくなり、単一のインベントリーグループ
towerに置き換えられました。ただし、データベースのグループは、外部の Postgres を指定するために残されています。
[tower]
hostA
hostB
hostC
[database]
hostDB
注釈
クラスターには最低でも 3 つの Tower ノードを使用することを推奨しています。
redis_passwordフィールドは[all:vars]から削除されています。RabbitMQ の新規フィールドは以下のとおりです。
rabbitmq_port=5672: RabbitMQ は、各ノードにインストールされ、オプションではありません。またこれは外部に設定することはできません。この設定により、どのポートをリッスンするのかを指定します。rabbitmq_vhost=tower: Tower が RabbitMQ virtualhost を構成して分離するための設定を制御します。rabbitmq_username=towerおよびrabbitmq_password=tower: 各ノードおよびノード毎の Tower インスタンスがこれらの値で設定されます。これは、Tower で他に使用するユーザー名/パスワードと似ています。rabbitmq_cookie=<somevalue>: この値は、スタンドアロンのデプロイメントでは使用されませんが、クラスターのデプロイメントには必要不可欠です。これは、RabbitMQ クラスターのメンバーがお互いを識別できるように、シークレットキーとして機能します。rabbitmq_use_long_names: RabbitMQ は、各ノードの名称に厳密に反応しますが、Tower は柔軟性が高く、FQDN (host01.example.com)、短い名前 (host01) または ip アドレス (192.168.5.73) に対応できます。インベントリーファイルで各ホストの特定に使用する方法によって、この値は変化する可能性があります。- FQDN および IP アドレスの場合は、この値は
trueです。 - 短い名前の場合は、値を
falseに設定します。 - localhost を使用する場合は、
rabbitmq_use_long_name=falseのデフォルト設定を true に変更しないでください。
- FQDN および IP アドレスの場合は、この値は
5.2.1. RabbitMQ デフォルト設定¶
以下の設定は、RabbitMQ のデフォルト設定です。
rabbitmq_port=5672
rabbitmq_vhost=tower
rabbitmq_username=tower
rabbitmq_password=''
rabbitmq_cookie=cookiemonster
# For FQDNs and IP addresses, this value needs to be true
rabbitmq_use_long_name=false
# Needs to remain false if you are using localhost
5.2.2. Tower が使用するノードおよびポート¶
Tower が使用するポートとノードは以下のとおりです。
- 80、443 (通常の Tower ポート)
- 22 (ssh)
- 5432 (データベースノード: データベースが外部ノードにインストールされた場合は、Tower ノードに対してこのポートを開放する必要があります。)
クラスタリング/RabbitMQ ポート:
- 4369、25672 (クラスターの管理に RabbitMQ 専用で使用するポート。各ノード間でこのポートを開放する必要があります)
- 15672 (RabbitMQ 管理インターフェースが有効化されている場合には、このポートを開放する必要があります (任意))
5.3. ブラウザーの API を使用したステータスの確認およびモニタリング¶
Tower は、/api/v1/ping で、クラスターのヘルスを検証するために Browsable API を使用してステータスをできるだけレポートします。以下に例を示します。
- HTTP 要求にサービスを提供するノード
- クラスター内にある他の全ノードが出した最後のハートビートのタイムスタンプ
- ジョブキューの状態。各ノードが実行するジョブ
- RabbitMQ クラスターのステータス
5.4. ノードサービスおよび障害時の動作¶
各 Tower ノードは、複数の異なるサービスで構成されており、これらのサービスは連携しています。
- HTTP サービス: これには、Tower アプリケーション自体と外部の Web サービスが含まれます。
- Callback Receiver: 実行中の Ansible ジョブからジョブイベントを受信します。
- Celery: 全ジョブを処理、実行するワーカーキュー
- RabbitMQ: このメッセージブローカーは、Celery のシグナルメカニズムおよびアプリケーションに伝搬するイベントデータとして使用されます。
- Memcached: サービスが配置されているノードのローカルキャッシュサービス
サービスやコンポーネントに障害が発生すると、全サービスが再起動されるように Tower は構成されています。サービスやコンポーネントが短期間で何度も機能しなくなった場合には、予期せぬ動作を発生させずに修正できるように自動的に全ノードがオフラインに切り替えられます。
5.5. ジョブランタイムの動作¶
ジョブの実行や、Tower の「通常」ユーザーへレポートする方法は変更されません。システム側には、注目すべき相違点が複数あります。
- ジョブが API インターフェースから送信されると、RabbitMQ の Celery キューにプッシュされます。単一の RabbitMQ ノードは個別キューをまとめるマスターとなり、各 Tower ノードは特定のスケジュールアルゴリズムを使用してキューに接続し、そのキューからジョブを受信します。クラスター内のいずれのノードも、同じ確率でジョブを受信してタスクを実行します。ジョブの実行時にノードが失敗すると、ジョブは永続的に「失敗」とマークされます。
Tower ノードはオンラインになると、1 つの全体ユニット (クラスターの容量) として測定されるので、Tower システムの作業容量が効率的に拡張されます。反対に、ノードのプロビジョニングを解除すると、クラスターからの容量がなくなります。詳細は、次のセクションの「ノードのプロビジョニング解除」を参照してください。
注釈
すべてのノードを同じ容量でプロビジョニングする必要はありません。
プロジェクトの更新は、以前とは動作が異なります。以前のリリースでは、単一のノードで実行される通常のジョブでした。今回のリリースでは、ジョブを実行可能なノードであればどこでも正常に実行できることが重要です。プロジェクトは、ジョブの実行直前に、ノード上で正しいバージョンに同期されます。
5.6. ノードのプロビジョニング解除¶
Tower のプロビジョニングを解除すると、自動的にノードのプロビジョニングが解除されます。これは現在、ノードがオフラインになった理由が意図的なのか、障害が原因なのかをクラスターでは識別できないためです。代わりに、Tower ノードの全サービスをシャットダウンしてから、他のノードからプロビジョニング解除ツールを実行します。
ansible-tower-service stopのコマンドで、ノードをシャットダウンするか、サービスを停止します。別のノードから
$ tower-manage deprovision_node —-name=<name used in inventory file>のプロビジョニング解除のコマンドを実行して、Tower のクラスターレジストリーと、RabbitMQ クラスターレジストリーから削除します。例:
tower-manage deprovision_node -—name=hostB